一、SparkSQL介绍
1、概述: sparkSQL是spark用来处理结构化数据的一个模块。 sparkSQL提供了一个编程的抽象叫做DataFrame并且作为我们分布式SQL的查询引擎 2、作用:用来处理结构化数据,先将非结构化的数据转成结构化数据。 3、SparkSQL提供了两种编程模型: 1)SQL的方式 select * from user; 2)DataFrame方式(DSL) HQL:将SQL转换为mr任务 SparkSQL:将SQL转换为RDD,效率快 4、特点: 1)容易整合 spark 2)统一数据的访问方式 3)标准的数据连接 支持JDBC/ODBC,可以对接BI工具 4)兼容HIVE
二、DataFrame介绍
与RDD类似,DataFrame也是一个分布式数据容器。
SparkSQL属于SQL解析引擎。在spark,将SQL解析RDD。注意:这个RDD比较特殊,是带有schema信息的RDD。
这个RDD就叫DataFrame。
DataFrame像数据库的二维表格(有行有列表描述),它除了数据之外还记录了数据的结构信息(schema)。
与RDD区别:
DataFrame:存放了结构化数据的描述信息
RDD:存储文本数据、二进制、音频、视频...
三、SQL风格
1、SqlTest1
import org.apache.spark.rdd.RDD import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType} import org.apache.spark.sql.{DataFrame, Row, SparkSession} /** * spark2.x * SQL风格 */ object SqlTest1 { def main(args: Array[String]): Unit = { //1.构建SparkSession val sparkSession = SparkSession.builder().appName("SqlTest1") .master("local[2]") .getOrCreate() //2.创建RDD val dataRdd: RDD[String] = sparkSession.sparkContext .textFile("hdfs://192.168.146.111:9000/user.txt") //3.切分数据 val splitRdd: RDD[Array[String]] = dataRdd.map(_.split(" ")) //4.封装数据 val rowRdd = splitRdd.map(x => { val id = x(0).toInt val name = x(1).toString val age = x(2).toInt //封装一行数据 Row(id, name, age) }) //5.创建schema(描述DataFrame信息) sql=表 val schema: StructType = StructType(List( StructField("id", IntegerType, true), StructField("name", StringType, true), StructField("age", IntegerType, true) )) //6.创建DataFrame val userDF: DataFrame = sparkSession.createDataFrame(rowRdd, schema) //7.注册表 userDF.registerTempTable("user_t") //8.写sql val uSql: DataFrame = sparkSession.sql("select * from user_t order by age") //9.查看结果 show databases; uSql.show() //10.释放资源 sparkSession.stop() } }
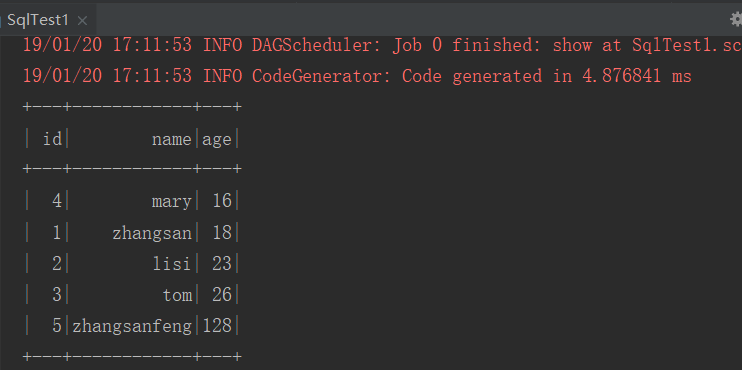
2、user.txt
1 zhangsan 18 2 lisi 23 3 tom 26 4 mary 16 5 zhangsanfeng 128
3、结果
四、toDF使用
scala> val rdd = sc.textFile("hdfs://192.168.146.111:9000/user.txt").map(_.split(" "))
rdd: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[2] at map at <console>:24
scala> case class User(id:Int,name:String,age:Int)
defined class User
scala> val userRdd = rdd.map(x => User(x(0).toInt,x(1),x(2).toInt))
userRdd: org.apache.spark.rdd.RDD[User] = MapPartitionsRDD[4] at map at <console>:28
scala> val udf = userRdd.toDF
udf: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> udf.show()
+---+------------+---+
| id| name|age|
+---+------------+---+
| 1| zhangsan| 18|
| 2| lisi| 23|
| 3| tom| 26|
| 4| mary| 16|
| 5|zhangsanfeng|128|
+---+------------+---+
scala> udf.select("name","age").show()
+------------+---+
| name|age|
+------------+---+
| zhangsan| 18|
| lisi| 23|
| tom| 26|
| mary| 16|
|zhangsanfeng|128|
+------------+---+
scala> udf.filter(col("id") <= 3).show()
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 18|
| 2| lisi| 23|
| 3| tom| 26|
+---+--------+---+
scala> udf.filter(col("id") > 3).show()
+---+------------+---+
| id| name|age|
+---+------------+---+
| 4| mary| 16|
| 5|zhangsanfeng|128|
+---+------------+---+
scala> udf.groupBy(("name")).count.show()
+------------+-----+
| name|count|
+------------+-----+
|zhangsanfeng| 1|
| mary| 1|
| zhangsan| 1|
| tom| 1|
| lisi| 1|
+------------+-----+
scala> udf.sort("age").show()
+---+------------+---+
| id| name|age|
+---+------------+---+
| 4| mary| 16|
| 1| zhangsan| 18|
| 2| lisi| 23|
| 3| tom| 26|
| 5|zhangsanfeng|128|
+---+------------+---+
scala> udf.orderBy("age").show()
+---+------------+---+
| id| name|age|
+---+------------+---+
| 4| mary| 16|
| 1| zhangsan| 18|
| 2| lisi| 23|
| 3| tom| 26|
| 5|zhangsanfeng|128|
+---+------------+---+
scala> udf.registerTempTable("user_t")
warning: there was one deprecation warning; re-run with -deprecation for details
scala> spark.sqlContext.sql("select * from user_t").show()
+---+------------+---+
| id| name|age|
+---+------------+---+
| 1| zhangsan| 18|
| 2| lisi| 23|
| 3| tom| 26|
| 4| mary| 16|
| 5|zhangsanfeng|128|
+---+------------+---+
scala> spark.sqlContext.sql("select name,age from user_t where age>18").show()
+------------+---+
| name|age|
+------------+---+
| lisi| 23|
| tom| 26|
|zhangsanfeng|128|
+------------+---+
scala>
五、DSL风格
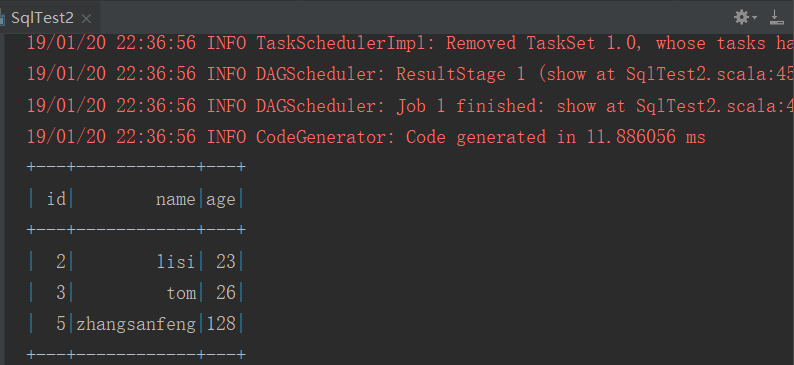
import org.apache.spark.rdd.RDD import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType} import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession} /** * DSL风格 */ object SqlTest2 { def main(args: Array[String]): Unit = { //1.创建sparkSession val sparkSession: SparkSession = SparkSession.builder() .appName("SqlTest2") .master("local[2]") .getOrCreate() //2.创建rdd val dataRDD: RDD[String] = sparkSession.sparkContext .textFile("hdfs://192.168.146.111:9000/user.txt") //3.切分数据 val splitRDD: RDD[Array[String]] = dataRDD.map(_.split(" ")) val rowRDD: RDD[Row] = splitRDD.map(x => { val id = x(0).toInt val name = x(1).toString val age = x(2).toInt //Row代表一行数据 Row(id, name, age) }) val schema: StructType = StructType(List( //结构字段 StructField("id", IntegerType, true), StructField("name", StringType, true), StructField("age", IntegerType, true) )) //4.rdd转换为dataFrame val userDF: DataFrame = sparkSession.createDataFrame(rowRDD, schema) //5.DSL风格 查询年龄大于18 rdd dataFrame dataSet import sparkSession.implicits._ val user1DF: Dataset[Row] = userDF.where($"age" > 18) user1DF.show() //6.关闭资源 sparkSession.stop() } }
结果:
六、WordCount
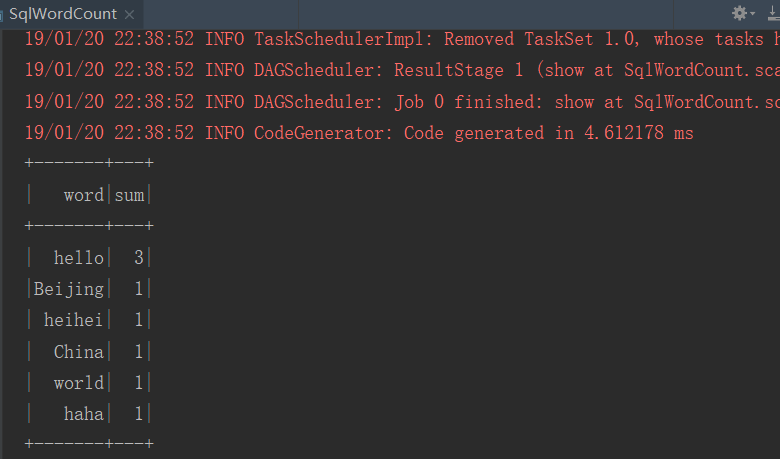
1、SqlWordCount
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} object SqlWordCount { def main(args: Array[String]): Unit = { //1.创建SparkSession val sparkSession: SparkSession = SparkSession.builder() .appName("SqlWordCount") .master("local[2]") .getOrCreate() //2.加载数据 使用dataSet处理数据 dataSet是一个更加智能的rdd,默认有一列叫value val datas: Dataset[String] = sparkSession.read .textFile("hdfs://192.168.146.111:9000/words.txt") //3.sparkSql 注册表/注册视图 rdd.flatMap import sparkSession.implicits._ val word: Dataset[String] = datas.flatMap(_.split(" ")) //4.注册视图 word.createTempView("wc_t") //5.执行sql wordCount val r: DataFrame = sparkSession .sql("select value as word,count(*) sum from wc_t group by value order by sum desc") r.show() sparkSession.stop() } }
2、words.txt
hello world
hello China
hello Beijing
haha heihei
3、结果
七、Join操作
1、JoinDemo
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} /** * SQL方式 */ object JoinDemo { def main(args: Array[String]): Unit = { //1.创建SparkSession val sparkSession: SparkSession = SparkSession.builder().appName("JoinDemo") .master("local[2]").getOrCreate() import sparkSession.implicits._ //2.直接创建dataSet val datas1: Dataset[String] = sparkSession .createDataset(List("1 Tom 18", "2 John 22", "3 Mary 16")) //3.整理数据 val dataDS1: Dataset[(Int, String, Int)] = datas1.map(x => { val fields: Array[String] = x.split(" ") val id = fields(0).toInt val name = fields(1).toString val age = fields(2).toInt //元组输出 (id, name, age) }) val dataDF1: DataFrame = dataDS1.toDF("id", "name", "age") //2.创建第二份数据 val datas2: Dataset[String] = sparkSession .createDataset(List("18 young", "22 old")) val dataDS2: Dataset[(Int, String)] = datas2.map(x => { val fields: Array[String] = x.split(" ") val age = fields(0).toInt val desc = fields(1).toString //元组输出 (age, desc) }) //3.转化为dataFrame val dataDF2: DataFrame = dataDS2.toDF("dage", "desc") //4.注册视图 dataDF1.createTempView("d1_t") dataDF2.createTempView("d2_t") //5.写sql(join) val r = sparkSession.sql("select name,desc from d1_t join d2_t on age = dage") //6.触发任务 r.show() //7.关闭资源 sparkSession.stop() } }
2、结果
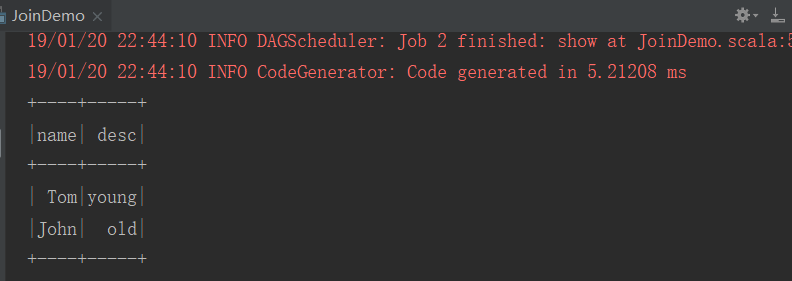
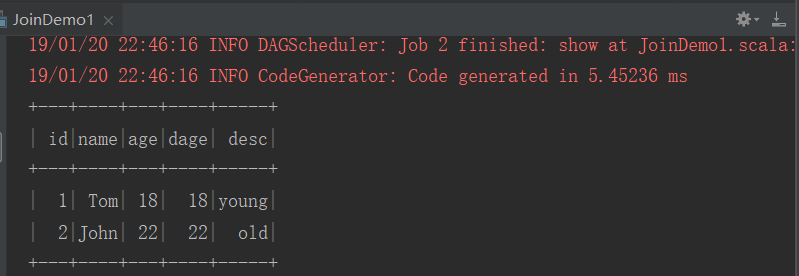
3、JoinDemo1
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} object JoinDemo1 { def main(args: Array[String]): Unit = { //1.创建SparkSession val sparkSession: SparkSession = SparkSession.builder() .appName("JoinDemo1") .master("local[2]").getOrCreate() import sparkSession.implicits._ //2.直接创建dataSet val datas1: Dataset[String] = sparkSession .createDataset(List("1 Tom 18", "2 John 22", "3 Mary 16")) //3.整理数据 val dataDS1: Dataset[(Int, String, Int)] = datas1.map(x => { val fields: Array[String] = x.split(" ") val id = fields(0).toInt val name = fields(1).toString val age = fields(2).toInt //元组输出 (id, name, age) }) val dataDF1: DataFrame = dataDS1.toDF("id", "name", "age") //2.创建第二份数据 val datas2: Dataset[String] = sparkSession .createDataset(List("18 young", "22 old")) val dataDS2: Dataset[(Int, String)] = datas2.map(x => { val fields: Array[String] = x.split(" ") val age = fields(0).toInt val desc = fields(1).toString //元组输出 (age, desc) }) //3.转化为dataFrame val dataDF2: DataFrame = dataDS2.toDF("dage", "desc") //默认方式 inner join //val r: DataFrame = dataDF1.join(dataDF2, $"age" === $"dage") //val r: DataFrame = dataDF1.join(dataDF2, $"age" === $"dage", "left") //val r: DataFrame = dataDF1.join(dataDF2, $"age" === $"dage", "right") //val r: DataFrame = dataDF1.join(dataDF2, $"age" === $"dage", "left_outer") val r: DataFrame = dataDF1.join(dataDF2, $"age" === $"dage", "cross") r.show() //7.关闭资源 sparkSession.stop() } }
4、结果