这篇文章的主要贡献点在于:
1.实验证明仅仅利用图像整体的弱标签很难训练出很好的分割模型;
2.可以利用bounding box来进行训练,并且得到了较好的结果,这样可以代替用pixel-level训练中的ground truth;
3.当我们用少量的pixel-level annotations和大量的图像整体的弱标签来进行半监督学习时,其训练效果可和全部使用pixel-level annotations差不多;
4.利用额外的强弱标签可以进一步提高效果。
这是用image-level labels来做的,通过图像的标签对每个像素进行处理,如果该像素的用CNN得到的score map中有该图像标签,则对m位置处的CNN输出做调整并选取其中的最大值作为最新标签,然后用M步中的批量梯度下降法得到新的CNN参数(这个步骤和之前用pixel-level做是一样的),不再需要人工来做大量的工作进行像素级的标定。但是这种方法不太准确,所以用像素级的一部分标签加上图像的标签来进行训练。
这篇文章在DeepLab的基础上进一步研究了使用bounding box和image-level labels作为标记的训练数据。使用了期望值最大化算法(EM)来估计未标记的像素的类别和CNN的参数。
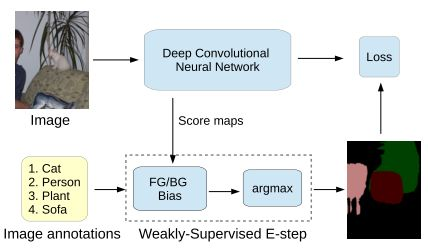
对于image-level标记的数据,我们可以观测到图像的像素值和图像级别的标记
,但是不知道每个像素的标号
,因此把
当做隐变量。使用如下的概率图模式:
使用EM算法估计和
。E步骤是固定
求
的期望值,M步骤是固定
使用SGD计算
。
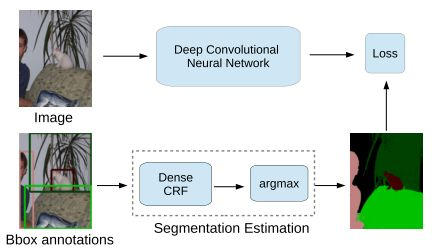
对于给出bounding box标记的训练图像,该方法先使用CRF对该训练图像做自动分割,然后在分割的基础上做全监督学习。通过实验发现,单纯使用图像级别的标记得到的分割效果较差,但是使用bounding box的训练数据可以得到较好的结果,在VOC2012 test数据集上得到mIoU 62.2%。另外如果使用少量的全标记图像和大量的弱标记图像进行结合,可以得到与全监督学习(70.3%)接近的分割结果(69.0%)。