主要内容:hdfs的核心工作原理:namenode元数据管理机制,checkpoint机制;数据上传下载流程
1、hdfs的核心工作原理
1.1、namenode元数据管理要点
1、什么是元数据?
hdfs的目录结构及每一个文件的块信息(块的id,块的副本数量,块的存放位置<datanode>)
2、元数据由谁负责管理?
namenode
3、namenode把元数据记录在哪里?
试想一下,如果元数据是以文件的形式存在和管理的,会很不方便,因为文件是一个顺序的结构,当用户新上传或者,移动,删除hdfs中的文件是,对文本元数据的维护会变得很麻烦。
实际上元数据是放在内存中的,用java对象来表示,使用树(精心设计的数据结构对象)表示目录结构,这样会很方便对元数据进行管理。放到内存就会遇到一个严重的问题,万一宕机或者断电,我们知道内存中的数据是不可逆的,会丢失,所以还需要定期的保存一份备份数据在硬盘上,在namenode工作目录下形成一个特定文件。那么序列化时机呢?
如果元数据一发生变化就将其序列化到硬盘,这显然是不妥的,因为元数据信息可能很大,硬盘难以承受频繁的写操作,所以只能定期的进行序列化,这样又带来一个问题,在这个期间内存中的元数据可能发发生变化,如果在这个期间宕机,下次启动,从硬盘恢复过来的数据就不是最新的,怎么办?
现在遇到的问题是,内存中的数据是实时更新的,硬盘中的数据没法实时更新,通用解决方案,(任何地方碰到类似的情况下也适用):一旦用户发出修改内存数据的请求,应当在修改内存数据完成后,将本次的修改操作记录下来(以日志的形式,日志不存在修改的问题,只是追加),形成文件,保存在硬盘。这样宕机重启之后,将上一次序列化的文件反序列化,然后解析日志,将反序列化结果按照日志解析结果进行相应的数据修改,恢复到上次宕机是的状态。
日志采用滚动记录形式,确保不会出现很大的日志文件,避免单机重启的时候,重放日志花去太多的时间,还有一个问题,若宕机之前,namanode正常运转了很长一段时间,形成了许许多多的日志块,若下次重启机器的时候从最老的日志开始重放吗?若是这样同样会花去很多时间。如何改进呢?
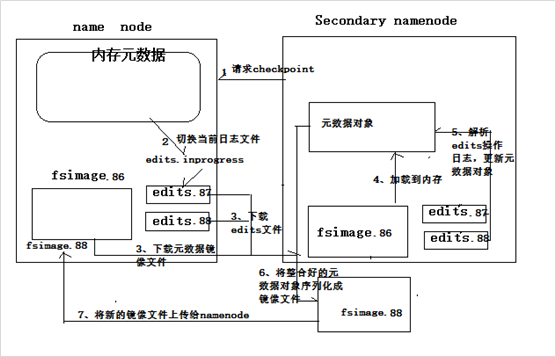
解决办法,不必等到宕机重启的时候去重放日志来恢复,定期重放日志,将日志和fsimage合并,将合并完的日志删除,并对合并结果进行编号(编号参考合并日志中最大(最新)的编号);为了保证namnode工作性能,专心管理元数据,这整个过程由secondary name node来完成。
secondary namenode 第一次从namenode拉去fsimage_00文件和edits_00 --- edits_95(最新)日志,到secondary 的本地,然后发序列化fsimage_00在自己的内存中形成元数据对象,然后重放日志endits_00 --edits_95修改内存中的元数据对象,然后将修改好的元数据对象序列化到自己的硬盘中,形成fsimage_95文件,然后将fsimage_95文件上传到namenode工作目录下;此时namenode的工作目录下会同时并存fsimage_00和fsimage_95(保存最新的两个版本);然后secondary namenode 继续讲编号95之后的日志(比如edits_96 --- edits_195)拉取到本地,不会再拉取fsimage(只会在第一次操作的时候拉取fsimage),然后继续将本地的fsimage_95 和 最新的日志edits_96 --- edits_195合并,最终形成fsimage_195,上传给namenode,同时删除最老的fsimage_00。 默认每隔一个小时做一次合并操作。整个机制就是checkpoint(在某个检查点形成新的状态)。下次namenode宕机重启的时候,会将自己工作目录下的fsimage反序列化并重返新的日志。
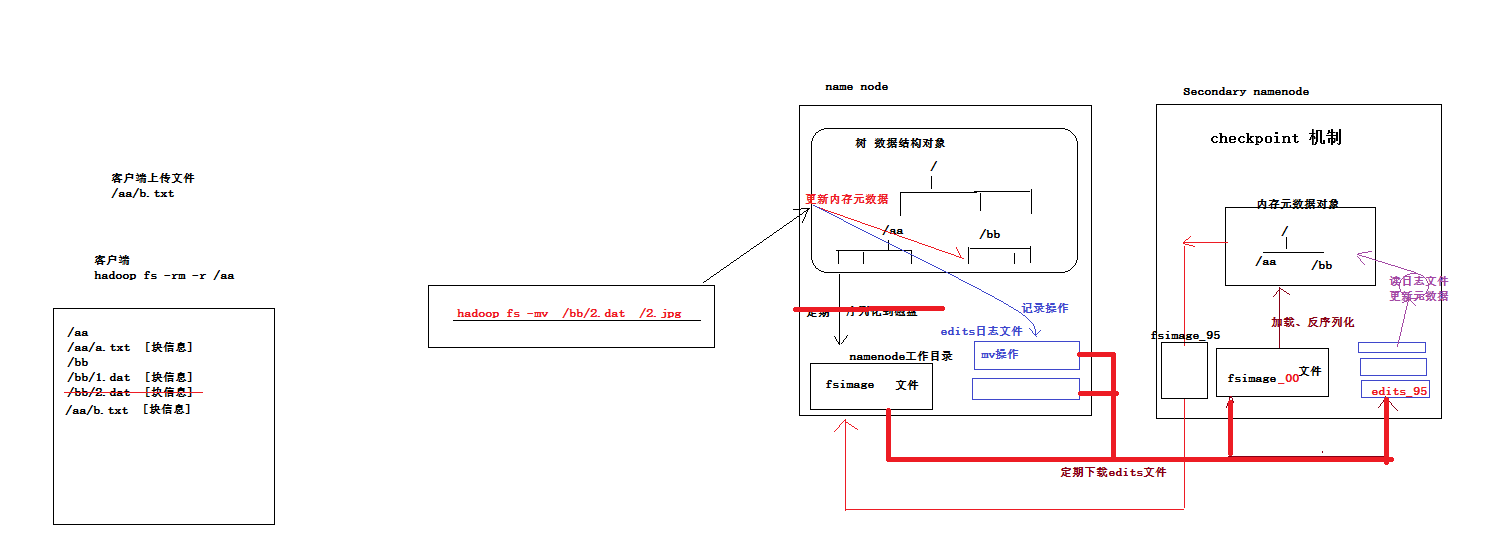

namenode的实时的完整的元数据存储在内存中;
namenode还会在磁盘中(dfs.namenode.name.dir)存储内存元数据在某个时间点上的镜像文件;
namenode会把引起元数据变化的客户端操作记录在edits日志文件中;
|
secondarynamenode会定期从namenode上下载fsimage镜像和新生成的edits日志,然后加载fsimage镜像到内存中,然后顺序解析edits文件,对内存中的元数据对象进行修改(整合) 整合完成后,将内存元数据序列化成一个新的fsimage,并将这个fsimage镜像文件上传给namenode |
|
上述过程叫做:checkpoint操作 提示:secondary namenode每次做checkpoint操作时,都需要从namenode上下载上次的fsimage镜像文件吗? 第一次checkpoint需要下载,以后就不用下载了,因为自己的机器上就已经有了。 |
补充:secondary namenode启动位置的配置
|
默 认 值 |
<property> <name>dfs.namenode.secondary.http-address</name> <value>0.0.0.0:50090</value> </property> |
把默认值改成你想要的机器主机名即可
secondarynamenode保存元数据文件的目录配置:
|
默 认 值 |
<property> <name>dfs.namenode.checkpoint.dir</name> <value>file://${hadoop.tmp.dir}/dfs/namesecondary</value> </property> |
改成自己想要的路径即可:/root/dfs/namesecondary
2、写数据流程
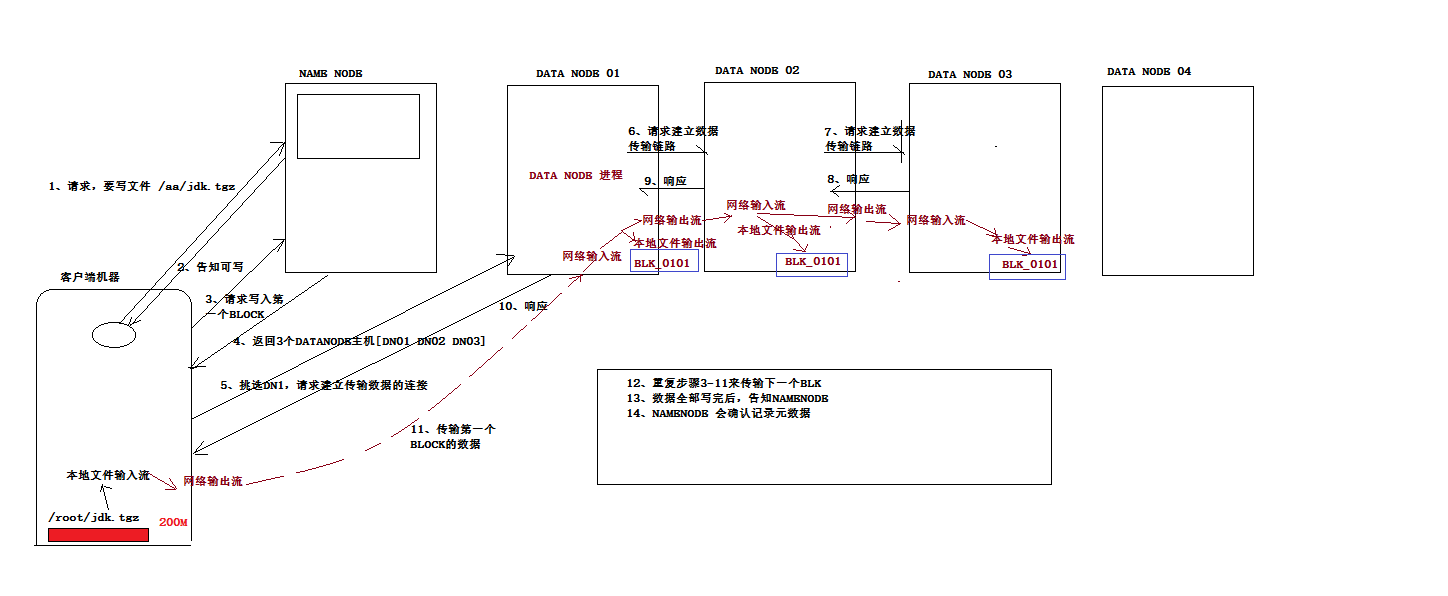
datanode会定期的向namenode回报自身持有的block信息,如果与元数据记录信息不一致,会少补多删。假如客户端在传最后一块block的时候出现异常,会通知namenode文件上传失败,那么清空该上传文件的元数据,此时datanode中存在的已经上传好的block会在定期向namenode汇报之后删除。
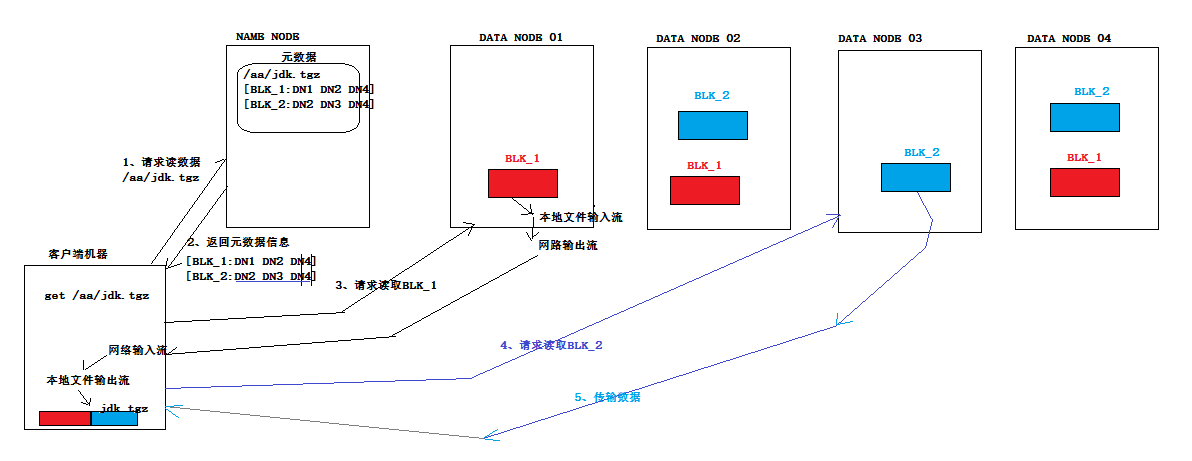
3、读数据流程
4、hadoop的HA机制原理解析
namenode程序是带状态的,所有两个节点之间的同步就比较复杂(standby需要继承挂掉的节点的状态)。yarn集群的HA就没有这么复杂(没有状态继承,只需要在Zookeeper中记录谁是active就可以)
两点:
1、元数据如何同步
2、状态如何切换

4.1、Qjournal分布式日志管理系统--集群
Q:QuorumPeerMain(Zookeeper的进程名字)
分布式日志管理系统(集群)Qjournal(提供数据的可靠保存,半数以上节点存活就可以正常对外提供服务;与Zookeeper的数据同步策略相同——paxos算法做数据一致性同步:奇数节点比较合适,半数以上节点存活系统就可正常工作)
active Namenode一方面往自己的本地记录日志edits,另一方面往Qjournal记录日志
standby Namenode 不断的从Qjournal中读取日志文件edits,一方面解析日志跟新内存中的元数据,一方面更新自己的fsimage文件,同时将跟新后的fsimage文件上传到(承担了secondnary NameNode的作用——合并fsimage和edits文件)active namenode,覆盖其原来的fsimage
4.2、zkfc:状态协调功能
activeNamenode 和 standby namenode 之间的状态协调功能;
比如:
1、不能起冲突,active是谁,已经有了active,那么另外一个节点只能是standby;
2、active挂了,standby 得知道,standby要不切换状态
zkfc的由来:namenode的逻辑本身已经十分复杂了,若是在将状态切换功能考虑进去,会更加的复杂,需要推到重做。hadoop开发组将这些状态协调管理功能封装到了另外的程序中,叫做zkfc(Zookeeper failover controller)基于Zookeeper的失败/故障切换/转移控制器。
1、zkfc以本地进程的方式来检测namenode
2、zkfc之间会通过Zookeeper来交换信息
zkfc会在Zookeeper上记录一些状态协调的信息以及注册监听:
1、比如谁是active 状态的namenode;
2、比如哪个namenode挂了
4.3、脑裂
集群中出现了两个active 的nameNode;
可能的原因:zkfc是一本地进程的方式与nameNode交互,若收不到nameNode的回应,会认为nameNode挂了,就会通知另外一台机制上的zkfc,另外一台机子上的zkfc收到消息后,如果立即将本机的standby namenode切换为active namenode,便有产生脑裂的风险;因为事实上,原来的active namenode没有反应不等于就挂了,因为java程序是运行在jvm上的,而jvm的GC机制可能会stop the world(通俗解释,GC平常都是做小范围的垃圾回收,这样肯定无法清理干净,当垃圾积攒到一定程度后会出发Full GC,jvm会停止所的用户线程,去清理垃圾),这样其实原来的active并没有挂掉,而此时的standby 已经切换成了active 转台,当GC做完之后,原来被jvm冻结的active恢复正常,此时就出现了两个ActiveNameNode,这就是脑裂。
zkfc防止脑裂的策略有两种:
1、ssh kill
2、shell 脚本
standby 远程登录原来的active namendoe 执行kill -9命令,若原active有回应,表示杀死了原active的进程,此时standby放心大胆的上位成standby;如果远程ssh kill没有在一个超时时间之内没有反应,则指向用户提供的shell脚本(警告也好,断掉原active的与网络也好,电源也好)。脚本返回0/true,则放心去切换状态。
4.4、name service
一对儿的active Namenode 和 standby nameNode术语叫做name service(名称服务)。
5、hadoop的HA集群搭建
最小的HA集群规划

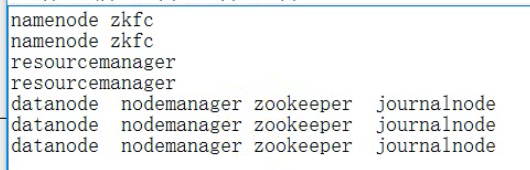
5.1、修改core-site.xml
非HA机制下的core-site.xml配置,指定了namenode以及端口号;而HA机制下不能用url来写死namenode,因为HA机制下是两台nameNode不知道哪一台是active,namenode是会随时切换,如果写死了,客户端只会链接uri中指定的namenode;所以HA机制下只写 name service(代表着一对namenode,name service的名字是自己定的,后面一定会有配置文件来解释这个name service,究竟是哪两个namenode)
<name>fs.defaultFS</name> <value>hdfs://hdp-01:9000/</value>
HA机制下的namenode;
HA机制下的两个namenode之间的切换需要依赖Zookeeper,所以还需要配置Zookeeper
<configuration> <!-- 指定hdfs的nameservice为ns1 --> <property> <name>fs.defaultFS</name> <value>hdfs://hdp24/</value> </property> <!-- 指定hadoop临时目录 -->
<!-- nodemanager 作为容器提供者,会提供容器,运行用户提交的程序,这个过程会产生一些临时的数据,若不配置默认存放在temp目录; --> <property> <name>hadoop.tmp.dir</name> <value>/root/hdptmp/</value> </property> <!-- 指定zookeeper地址 --> <property> <name>ha.zookeeper.quorum</name> <value>hdp-05:2181,hdp-06:2181,hdp-07:2181</value> </property> </configuration>
5.2、修改hdfs-site.xml
原来的配置,HA机制后不再需要secondaryNamenode了,需要删除该项配置。
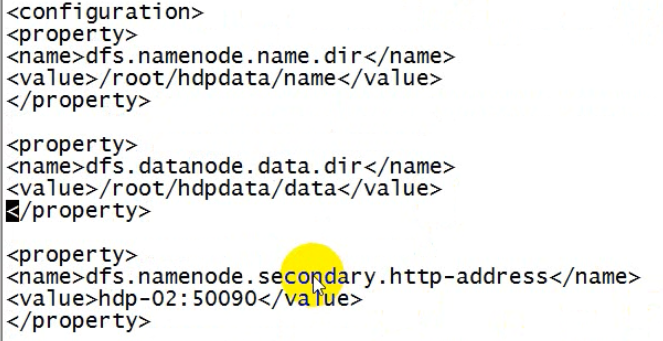
HA机制下的配置
<configuration>
<!-- name service --> <!--指定hdfs的nameservice为bi,需要和core-site.xml中的保持一致 --> <property> <name>dfs.nameservices</name> <value>hdp24</value> </property> <!-- hdp24下面有两个NameNode,分别是nn1,nn2 --> <property> <name>dfs.ha.namenodes.hdp24</name> <!-- 这是逻辑代号,名字随便起 -->
<value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.hdp24.nn1</name> <value>hdp-01:9000</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.hdp24.nn1</name> <value>hdp-01:50070</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.hdp24.nn2</name> <value>hdp-02:9000</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.hdp24.nn2</name> <value>hdp-02:50070</value> </property> <!-- 指定NameNode的edits元数据在机器本地磁盘的存放位置:namenode本地磁盘工作目录 --> <property> <name>dfs.namenode.name.dir</name> <value>/root/hdpdata/name</value> </property> <property>
<!-- datanode的工作目录 --> <name>dfs.datanode.data.dir</name> <value>/root/hdpdata/data</value> </property> <!-- JournalNode --> <!-- 指定NameNode的共享edits元数据在JournalNode上的存放位置,目录名最好和名称服务一致,当然这一定是一个虚拟目录 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hdp-05:8485;hdp-06:8485;hdp-07:8485/hdp24</value> </property> <!-- 指定JournalNode在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/root/hdpdata/journaldata</value> </property>
<!-- zkfc --> <!-- 开启NameNode失败自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失败自动切换实现方式: 用什么控制器 --> <property>
<!-- 大型集群里可能有多对namenode,也就是多对nameservice --> <name>dfs.client.failover.proxy.provider.hdp24</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行:防止脑裂的2种策略--> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence
<!-- 模拟脚本 --> shell(/bin/true)</value> </property> <!-- 使用sshfence隔离机制时需要ssh免登陆:告知秘钥位置 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!-- 配置sshfence隔离机制超时时间,若不配置会一直发脚本,超时后就会自动调用上面配置的脚本 --> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> </configuration>
5.3、修改mapred-site.xml
主要用来表示,job提交后,mapreduce运行在yarn集群上还是本地。
<configuration> <!-- 指定mr框架为yarn方式 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
5.4、修改yarn-site.xml
非HA机制下的配置
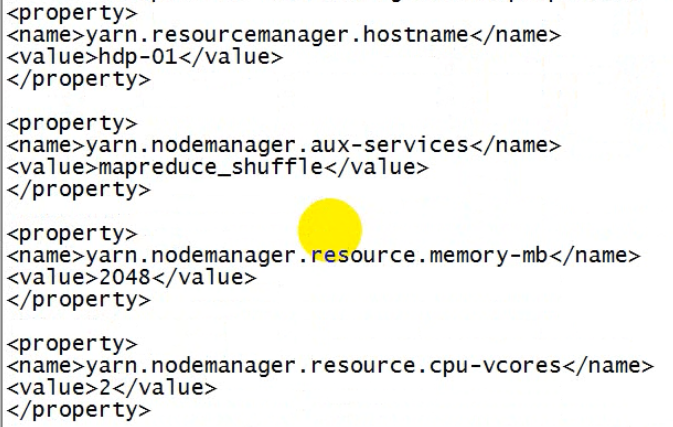
HA机制下的配置。
<configuration> <!-- 开启RM高可用 --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!-- 指定RM的cluster id:因为会有多个RM --> <property> <name>yarn.resourcemanager.cluster-id</name> <!-- 随便起 -->
<value>yrc</value> </property> <!-- 指定RM的逻辑名字 --> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!-- 分别指定RM的地址 --> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>hdp-03</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>hdp-04</value> </property> <!-- 指定zk集群地址:yarn集群也需要依赖Zookeeper --> <property> <name>yarn.resourcemanager.zk-address</name> <value>hdp-01:2181,hdp-02:2181,hdp-03:2181</value> </property> <property>
<!-- nodemanager 给mapreduce提供的辅助服务:mapTask把生成的结果以文件的形式写在了机器上,然后mapTask退出,reduceTask要去下载这些数据,靠nodemanager上的web服务器提供下载功能 --> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
ResourceManager和nodema通信的端口号是默认配置的8032。 ResourceManager的web端口是8088

5.5、修改slaves
slaves其实是启动脚本需要用到的,非hadoop本身要用的。
此时有两个集群的;
1、HDFS集群:有自己的slaves:datanode
2、yarm集群:有自己的slaves:nodemanager,要和datanode在一块比较好
slaves是指定子节点的位置,因为要在hadoop01上启动HDFS、在hadoop03启动yarn,所以hadoop01上的slaves文件指定的是datanode的位置,hadoop03上的slaves文件指定的是nodemanager的位置
5.6、免密钥登录
ssh-keygen -t rsa
ssh-coyp-id hadoop00
ssh-coyp-id hadoop01
ssh-coyp-id hadoop02
ssh-coyp-id hadoop03
ssh-coyp-id hadoop04
ssh-coyp-id hadoop05
ssh-coyp-id hadoop06
ssh-coyp-id hadoop07
5.7、启动
第一次启动集群
###注意:严格按照下面的步骤!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
5.7.1、启动zookeeper集群
(分别在hdp-05、hdp-06、hdp-07上启动zk)
cd /hadoop/zookeeper-3.4.5/bin/
./zkServer.sh start
#查看状态:一个leader,两个follower ./zkServer.sh status
5.7.2、手动启动journalnode
(分别在在hdp-05、hdp-06、hdp-07上执行)
journalnode想要工作正常必须启动Zookeeper
cd /hadoop/hadoop-2.6.4 sbin/hadoop-daemon.sh start journalnode
#运行jps命令检验,hadoop05、hadoop06、hadoop07上多了JournalNode进程
5.7.3、格式化namenode
因为现在namenode不仅在本地记录日志,一会在journalnode上记录日志,所以在格式化namenode之前,需要先启动journalnode;这样namenode格式化的时候会在本地以及journalnode上均写入响应的数据;
另一台namenode千万不要格式化,否则两次格式化,生成的集群id都不一样,应该是将一台格式化后的产生的文件直接拷贝到另外的一台上。保证元数据目录一模一样。
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成一些文件夹和文件
hadoop namenode -format
hdfs namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是/hadoop/hadoop-2.6.4/tmp,然后将/hadoop/hadoop-2.6.4/tmp拷贝到hadoop02的/hadoop/hadoop-2.6.4/下。
scp -r tmp/ hadoop02:/home/hadoop/app/hadoop-2.6.4/
##也可以这样,建议
##也可以这样,建议
hdfs namenode -bootstrapStandby
生成的其中一个文件version
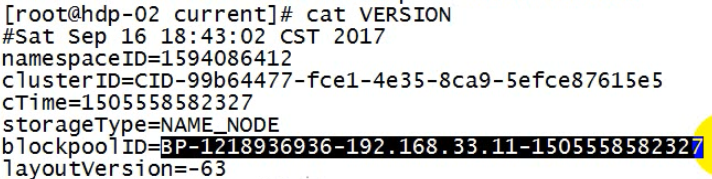
blockpoolID:将来一个大的集群(上万台)会有很多对的namenode,而datanode所有namenode公用的,namenode有很多对,datanode既要给这一对namenode存数据块,也要为另外的namenode存数据块;为了以示区分需要分目录来存取;那个目录名称就是blockpoolID
5.7.4、格式化ZKFC
(在hdp-01上执行即可)
zkfc是做状态切换的,需要在Zookeeper上记录一下信息;这就需要先创建znode节点,这就是格式化的目的。
hdfs zkfc -formatZK

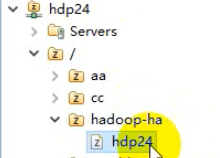 用来记录那个namenode是active状态的。
用来记录那个namenode是active状态的。
***********************************************************************************************************************
到此为止第一次集群启动时候的初始化工作全部完成。
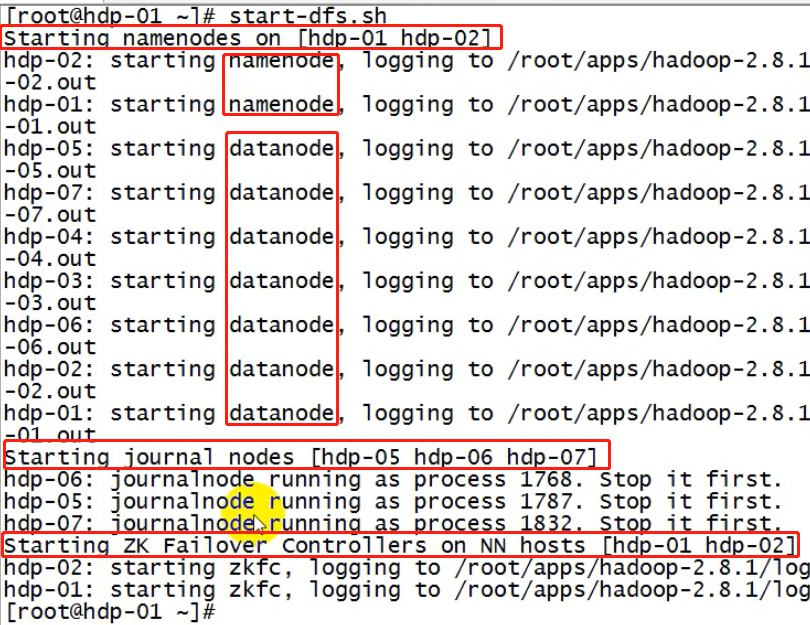
5.7.5、启动HDFS
(在hadoop00上执行)
这个命令会启动namenode,datanode,journalnode,zkfc
# 启动hdfs集群
sbin/start-dfs.sh
5.7.6、启动YARN
ResourceManager和nodema通信的端口号是默认配置的8032。 ResourceManager的web端口是8088
(#####注意#####:是在hadoop02上执行start-yarn.sh,把namenode和resourcemanager分开是因为性能问题,因为他们都要占用大量资源,所以把他们分开了,他们分开了就要分别在不同的机器上启动)
# 这个脚本只会启动本地机器上的ResourceManager和配置的slaves节点的nodemanager,另外一个RM需要手动起
sbin/start-yarn.sh
手动启动另外一台ResourceManager
yarn-daemon.sh start resourcemanager
web访问standby状态的ResourceManager会充当向到active状态的ResourceManager。
5.7.7、测试集群工作状态的一些指令
查看hdfs的各节点状态信息
bin/hdfs dfsadmin -report
获取一个namenode节点的HA状态
bin/hdfs haadmin -getServiceState nn1
单独启动一个namenode进程
sbin/hadoop-daemon.sh start namenode
单独启动一个zkfc进程
./hadoop-daemon.sh start zkfc
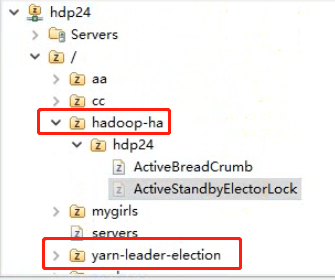
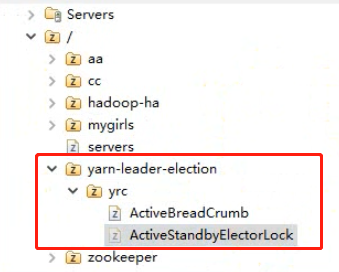
5.7.8、查看Zookeeper的znode
zkfc在Zookeeper上会记录一些信息。
yarn集群的ResourceManager也会在Zookeeper记录当前active状态的rm。


6、hadoop的HA集群客户端编程
非HA集群下,访问HDFS的aip如下,直接访问namenode的url就可以。

HA机制下,直接使用new URI("hdfs://hdp24")是无法解析的,需要在configuration中进行设置,或者将集群中的配置文件,添加到src类路径下。


从hadoopHA集群中下载配置文件。需要不集群中的配置文件放在工程src目录下。(包括core-site.xml hdfs-site.xml yarn-site.xml)
在HA机制下,客户端要想知道集群中的情况,必须将集群上的配置文件放入工程的classpath中。

