主要内容:mapreduce整体工作机制介绍;wordcont的编写(map逻辑 和 reduce逻辑)与提交集群运行;调度平台yarn的快速理解以及yarn集群的安装与启动。
1、mapreduce整体工作机制介绍
回顾第HDFS第一天单词统计实例(HDFS版wordcount):
统计HDFS的/wordcount/input/a.txt文件中的每个单词出现的次数——wordcount
但是,进一步思考:如果文件又多又大,用上面那个程序有什么弊端?
慢!因为只有一台机器在进行运算处理
从这个简单的案例中我们收到一些启发:
1、可以在任何地方运行程序,访问HDFS上的文件并进行统计运算,并且可以把统计的结果写回HDFS的结果文件中;
2、如何变得更快?核心思想:让我们的运算程序并行在多台机器上执行!
3、面向接口编程,整个程序的主框架是通用的,使用业务接口编程,主流程形成通用的框架,写好之后不需要修改,我们只要按照业务接口,提供具体的业务实现类,即可完成具体的业务操作。
幸运的是,hadoop中已经为我们提供了分布式计算的解决方案,就是mapreduce计算框架,用来在分布式环境下处理数据。
下图是mapreduce整体工作机制的简要介绍,后续还会有详细的介绍。
mapreduce与我们之前自己写个hdfs版本的wordcount一样,都是运算程序,而且可以在分布式环境下,并行运行,他的主处理流程同我们的wordcount主处理流程一样都是成形的计算框架设定好之后就不会改变了,框架中用到的统一的业务接口和业务方法(业务接口数据处理逻辑)需要我们实现并提供给框架。框架按照接口规定方法中设定好的参数要求,想特定类型和形式的数据传给用户提供的实现类,用户接受框架传入的参数,进行业务处理并将处理结果写入接口中规定的数据缓存对象中。
mapreduce程序分俩个阶段,整个运算流程分为map阶段和reduce阶段,分别有mapTask和reduceTask程序来实现。mapTask和reduceTask的大致工作机制如下。
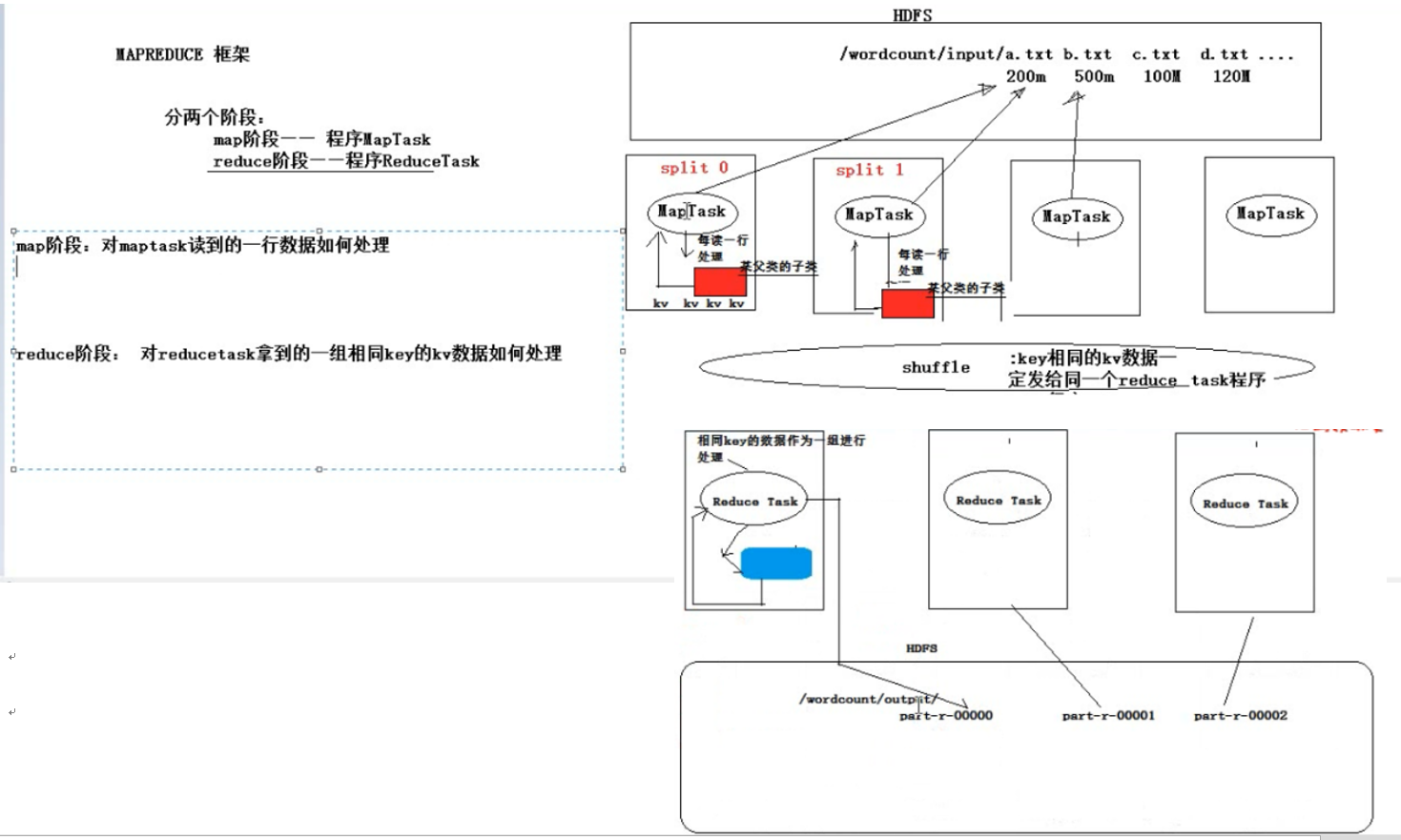
mapTask可以在很多机器上运行,具体运行多少个mapTask要看要处理的数据总量有多少,这个过程由程序自动计算,无需我们担心,计算好之后每个mapTask都会分到自己要处理的数据范围,术语叫做数据切片;一般来讲是这么计算的,赔了保证每个task处理的数据大体差不多,程序会将hdfs中的待处理的文件进行切片划分,默认一个切片(一个maptask要处理的数据范围)128M大小。假如要处理的文件有:a.txt(200m)b.txt(500m)c.txt(100m)d.txt(120m)如果一个task程序负责一个文件,显然是不公平不合理的,其实hadoop会按照128m大小为一个单位,对数据进行切片操作:a->2,b->4,c->1,d->1,总数据一共被切分成8个切片或者说8个任务,一个mapTask就处理一个切片或者说任务,一共需要8个maptask,那么就分配8个mapTask,这样每个mapTask就明确了自己的任务(所有task的处理逻辑都一样,都是上面提到的用户提供的业务实现类,只不过是处理的数据范围不同)和要处理的数据范围,接下来就是启动一批mapTask进行作业,当然如果文件很多很大,会需要很多的mapTask,至于一次启动多少个task以及一台物理机器会运行多少个mapTask,这和你的集群规模以及运行配置有关。mapTask就是一个程序,一台机子上可以启动过个mapTask,如果你你的集群只有两台机器负责mapTask运算,理论上每台机器会分启动4个maptask任务,但是若果机器性能有限,一次最多只能负载3个mapTask,也没关系,只不过是先运行一批mapTask(3+3=6个)每个task都有自己的任务只执行自己分陪到的任务,运行结束后在启动剩余的2个mapTask。所以不用担心机器不够用,既然任务分的很明确,可以每次运行一批mapTask,分批完成全部的。
maptask启动后会干什么,这个过程已经在mapreduce中写死了,每个mapTask会分到部分数据,然后一行一行的去读数据,每读一行数据,进行一次处理,具体的处理逻辑有用户提供的接口实现类来完成(需要用户提供具体的业务实现类,并且以某种方式通知mapreduce框架去调用哪一个实现类,可以通过配置文件或者参数的形式;mapTask将读到的数据作为参数传给业务方法,业务方法将处理的结果传给mapTask)。
那么这样还有一个问题,每个mapTask的处理数据范围和结果都只是整个数据的一个局部,并非全局结果,如何得到全局结果,这就需要mapreduce的第二个阶段,reduce阶段进行局部数据汇总统计。
reduce阶段有reduceTask程序来实现,可以在很多他机器上并行运行。reduceTask数量与mapTask数量没有关系,reduceTask要整理mapTask产生的数据,就需要统一大家的数据形式,这里统一为key :value键值对的形式。mapTask产生的key:value需要传递给reduceTask,而且核心思想是同时要确保,相同key的数据必须传递给同一个reduceTask,这就需要mapTask和reduceTask之间的数据分发机制,shuffle机制:可以相同的key:value数据一定发给同一个reduceTask程序。
reduce Task 聚合操作具体做什么,聚合操作就是对key相同的一组数据进行处理,具体的聚合逻辑通过接口的方式暴露给用户,由用户来指定(同mapTask方式)。
reduce Task处理结果,reduce Task将最后的聚合结果写入hdfs中,每个reduce Task最终形成一个文件,文件名称默认是part-r+reduceTask的编号。
总结:
map阶段,我们只需要提供具体的业务类,对mapTask读到的一行数据进行处理
reduce阶段,仍然需要我们提供具体的逻辑,对reduce拿到的一组相同key的kv数据进行处理
处理结果的传递:无论是map阶段还是recude阶段,数据处理结果的后续流程无需我们关系,我们只需要将各个阶段的数据都交给人家提供好的context对象就好;map阶段会将数据存着,将来想方设法地将数据结果传递给reduceTask,而且保证同一个key只给同一个reduce,reduce阶段会将数据写入hdfs,只要有一个结果key:value,就会往文件中追加一行。
2、wordcount示例

maptask每次度一行数据都会将数据作为参数传递给我们提给的业务接口实现类中的map方法(map(long l,String v ,context)map方法中的参数分别为,该行行首地址的偏移量,该行的数据,缓存对象),在wordcont程序中,map每次拿到maptask传递过来一行数据,首先将文本数据切分,形成单词数据,直接将(word,1)形式的数据写入context中,以便将来给reduce(context怎么缓存,后续会介绍),为什么里不做统计呢,将单行相同的单词统计一下?单行数据统计之后,任然是单行的结果,最后还得在recue中统计,避免无意义的中将统计,我们最终只在reduce中进行统计。maptask通过shuffle机制将(word,1)形式的数据发给,reduce同时保证相同的key只发往同一个reduce,这些发过来的相同key的一组数据在reduce这边落地成文件;文件中的参数如何给reduceTask的处理逻辑中共的reduce方法(reduce(k,value迭代器,context)参数分别是:一组数据的key,改组数据中的key都相同,任意一个都可以;value迭代器,可以不断的取出下一个值,context对象)。每一组(相同key)数据调用一次reduce逻辑。
2.1、 wordcount程序整体运行流程示意图
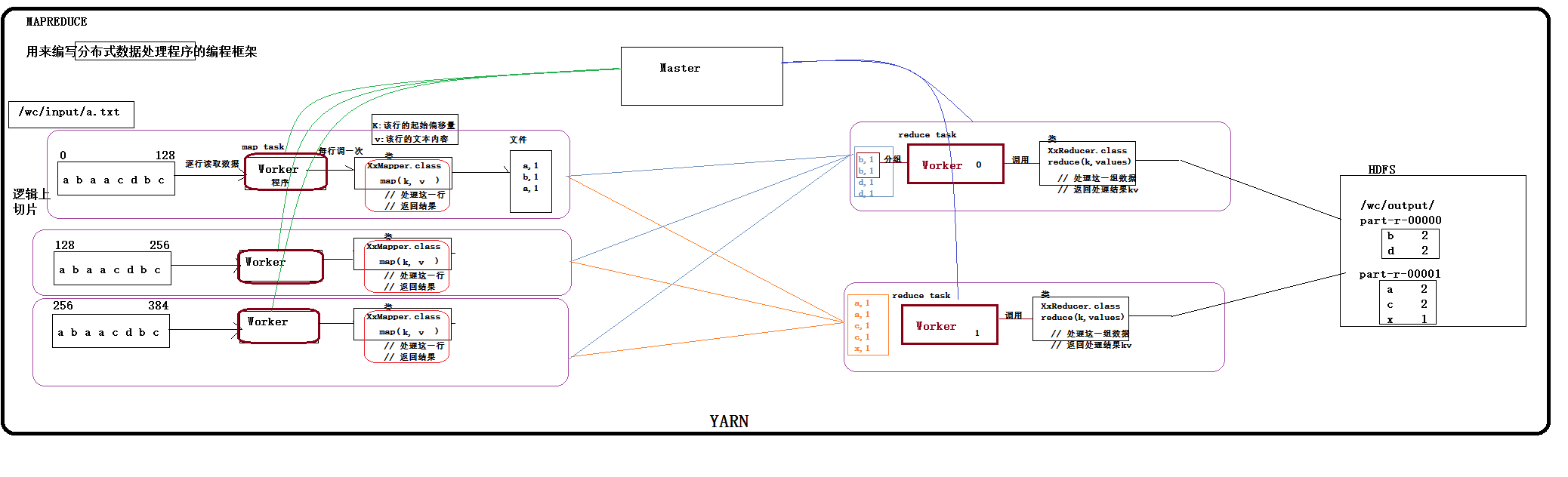
map阶段: 将每一行文本数据变成<单词,1>这样的kv数据
reduce阶段:将相同单词的一组kv数据进行聚合:累加所有的v
注意点:mapreduce程序中,
map阶段的进、出数据,
reduce阶段的进、出数据,
类型都应该是实现了HADOOP序列化框架的类型,如:
String对应Text
Integer对应IntWritable
Long对应LongWritable
2.2、 编码实现
WordcountMapper类开发


import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; /** * KEYIN :是map task读取到的数据的key的类型,是一行的起始偏移量Long * VALUEIN:是map task读取到的数据的value的类型,是一行的内容String * * KEYOUT:是用户的自定义map方法要返回的结果kv数据的key的类型,在wordcount逻辑中,我们需要返回的是单词String * VALUEOUT:是用户的自定义map方法要返回的结果kv数据的value的类型,在wordcount逻辑中,我们需要返回的是整数Integer * * * 但是,在mapreduce中,map产生的数据需要传输给reduce,需要进行序列化和反序列化,而jdk中的原生序列化机制产生的数据量比较冗余,就会导致数据在mapreduce运行过程中传输效率低下 * 所以,hadoop专门设计了自己的序列化机制,那么,mapreduce中传输的数据类型就必须实现hadoop自己的序列化接口 * * hadoop为jdk中的常用基本类型Long String Integer Float等数据类型封住了自己的实现了hadoop序列化接口的类型:LongWritable,Text,IntWritable,FloatWritable * * * * * @author ThinkPad * */ public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 切单词 String line = value.toString(); String[] words = line.split(" "); for(String word:words){ context.write(new Text(word), new IntWritable(1)); } } }
WordcountReducer类开发
import java.io.IOException; import java.util.Iterator; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { int count = 0; Iterator<IntWritable> iterator = values.iterator(); while(iterator.hasNext()){ IntWritable value = iterator.next(); count += value.get(); } context.write(key, new IntWritable(count)); } }
到这里map和reduce逻辑都写完了,接下来就是
1)设置参数告诉mapTask调哪个类,reduceTask调用哪个类 ;
2)然后将代码提交到集群去运行。
目前为止我们的工程中既有mapTask又有recuceTask,还有我们自己实现的逻辑类,是一个完整的工程,现在想要运行该程序,可不想单机版的程序那样直接run main函数那么简单,因为这是一个分布式的程序,它的运行需要依托一个平台,也就是说将来提交工程到集群中去运行的时候,哪些机子启动mapTask,哪些机子启动reduceTask等,启动过程不是一个简单的事情,而是一个复杂的调度过程,需要一套完整的调度系统或者说平台来进行管理,而hadoop中已经为我们提供了这样的一个平台(yarn,也是一个集群,是一个分布式系统,同样有很多服务程序)来完成上述工作。所以我们还需要在集群中安装该平台,在安装完之后,还需要写代码与该平台交互,将我们的工程jar包和配置参数告知平台,让平台帮我们运行程序。
2.3、运行mapreduce程序
1、首先,为你的mapreduce程序开发一个提交job到yarn的客户端类(模板代码):
描述你的mapreduce程序运行时所需要的一些信息(比如用哪个mapper、reducer、map和reduce输出的kv类型、jar包所在路径、reduce task的数量、输入输出数据的路径)
将信息和整个工程的jar包一起交给yarn
2、然后,将整个工程(yarn客户端类+ mapreduce所有jar和自定义类)打成jar包
3、然后,将jar包上传到hadoop集群中的任意一台机器上
4、最后,运行jar包中的(YARN客户端类)
[root@hdp-04 ~]# hadoop jar wc.jar cn.edu360.hadoop.mr.wc.JobSubmitter
JobSubmitter客户端类开发
细节,操作hdfs的用户有权限要求,整个工程要打成jar包,因为job会向yarn集群上传jar包;windows下提交job会有兼容性问题。
import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 用于提交mapreduce job的客户端程序 * 功能: * 1、封装本次job运行时所需要的必要参数 * 2、跟yarn进行交互,将mapreduce程序成功的启动、运行 * @author ThinkPad * */ public class JobSubmitter { public static void main(String[] args) throws Exception { // 在代码中设置JVM系统参数,用于给job对象来获取访问HDFS的用户身份 // 或者通过eclipse图形化界面来设置 -DHADOOP_USER_NAME=root System.setProperty("HADOOP_USER_NAME", "root") ; Configuration conf = new Configuration(); // 1、设置job运行时要访问的默认文件系统, map阶段要去读数据,reduce阶段要写数据 conf.set("fs.defaultFS", "hdfs://hdp-01:9000"); // 2、设置job提交到哪去运行:有本地模拟的方式local conf.set("mapreduce.framework.name", "yarn"); conf.set("yarn.resourcemanager.hostname", "hdp-01"); // 3、如果要从windows系统上运行这个job提交客户端程序,则需要加这个跨平台提交的参数 conf.set("mapreduce.app-submission.cross-platform","true"); // job中还要封装个多的参数 Job job = Job.getInstance(conf); // 1、封装参数:jar包所在的位置:因为job客户端将来要把jar包(整个工程)发给yarn //job.setJar("d:/wc.jar"); job.setJarByClass(JobSubmitter.class);//动态获取方式 // 2、封装参数: 本次job所要调用的Mapper实现类、Reducer实现类 job.setMapperClass(WordcountMapper.class); job.setReducerClass(WordcountReducer.class); // 3、封装参数:本次job的Mapper实现类、Reducer实现类产生的结果数据的key、value类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); Path output = new Path("/wordcount/output"); FileSystem fs = FileSystem.get(new URI("hdfs://hdp-01:9000"),conf,"root"); if(fs.exists(output)){ fs.delete(output, true); } // 4、封装参数:本次job要处理的输入数据集所在路径、最终结果的输出路径 FileInputFormat.setInputPaths(job, new Path("/wordcount/input")); FileOutputFormat.setOutputPath(job, output); // 注意:输出路径必须不存在 // 5、封装参数:想要启动的reduce task的数量(默认1),map task不需要设定,会根据数据集的大小自动切片计算。 job.setNumReduceTasks(2); // 6、提交job给yarn,等待集群完成,这是一个阻塞式方法 // 返回true表示mapreduce程序正常运行,false表示mapreduce程序运行失败,可能是中间的某一步。 boolean res = job.waitForCompletion(true);//true便是吧Resource manager(会不断的反馈信息)反馈回来的信息输出。 //job.submit()//提交之后直接退出 //控制退出码 System.exit(res?0:-1); } }
3、yarn快速理解
mapreduce程序应该是在很多机器上并行启动,而且先执行map task,当众多的maptask都处理完自己的数据后,还需要启动众多的reduce task,这个过程如果用用户自己手动调度不太现实,需要一个自动化的调度平台——hadoop中就为运行mapreduce之类的分布式运算程序开发了一个自动化调度平台——YARN(yarn,是一个集群,是一个分布式系统,同样有很多服务程序、包括:mapTask,reduceTask,mrappmaster)。
3.1、yarn的基本概念
yarn是一个分布式程序的运行调度平台,有很多服务程序,会运行在不同的机器上。
yarn中有两大核心角色:主要起作用的是Resource Manager
1、Resource Manager
接受用户(job客户端)提交的分布式计算程序,并为其划分资源
管理、监控各个Node Manager上的资源情况,以便于均衡负载
2、Node Manager
管理它所在机器的运算资源(cpu + 内存)
负责接受Resource Manager分配的任务,创建容器(一个容器默认1G内存大小)、接收jar包,启动程序、回收资源
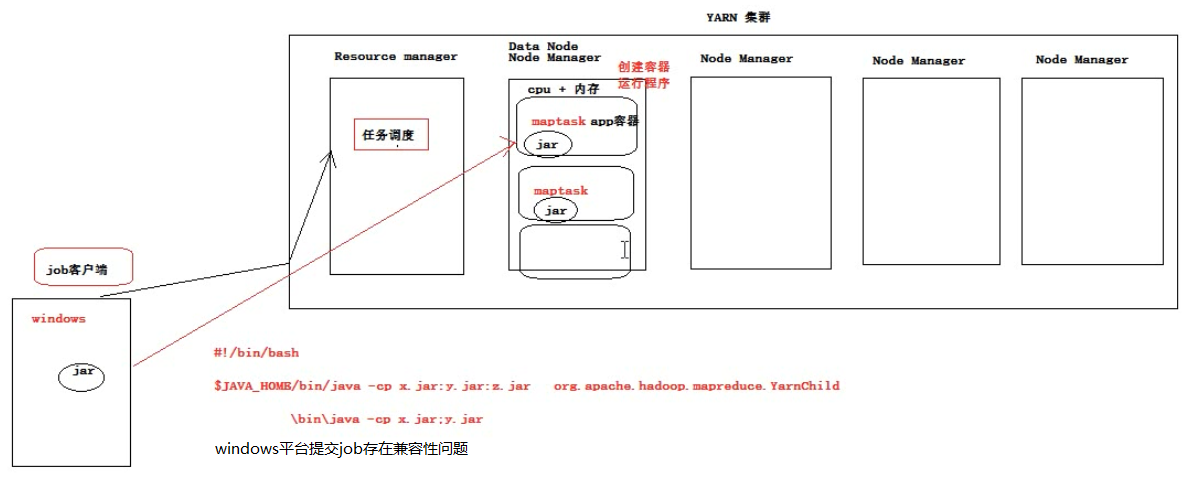
比如客户端提交了一个任务,并通过配置信息,指明需要12个容器运行,Resource Manager接收到客户端请求,将12个容器的计算任务安排给node manager,然后客户端去找对应的node manager进行交互,使用容器进行计算。
3.2、安装yarn集群
yarn集群中有两个角色:
主节点:Resource Manager 1台
从节点:Node Manager N台
node manager在物理上应该跟data node部署在一起,即与HDFS中的data node重叠在一起
resource manager在物理上应该独立部署在一台专门的机器上,一般安装在一台专门的机器上
3.2.1、修改配置文件
yarn-site.xml
<property> <name>yarn.resourcemanager.hostname</name> <value>hdp-04</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
<!-- 一个node manager内存大小 --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>2048</value> </property>
<!-- node manager 的cpu核数 -->
<property>
<name>
yarn.nodemanager.resource.cpu-vcores
</name>
<value>2</value>
</property>
其他的配置可以参考官网
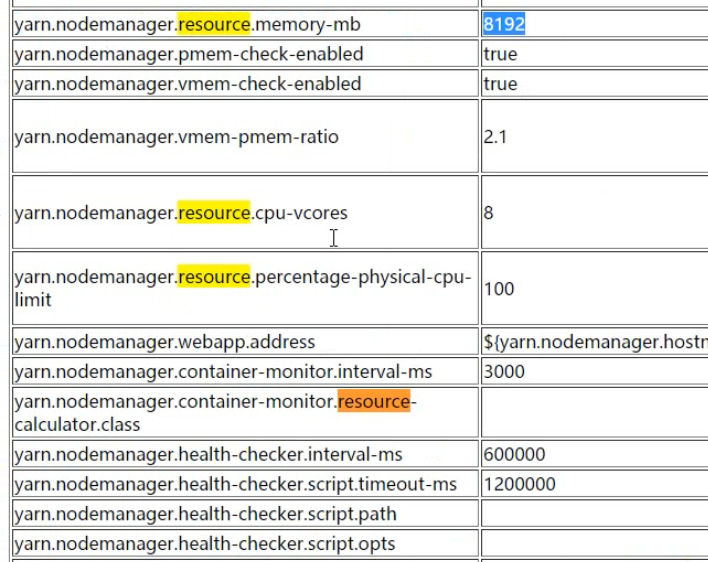
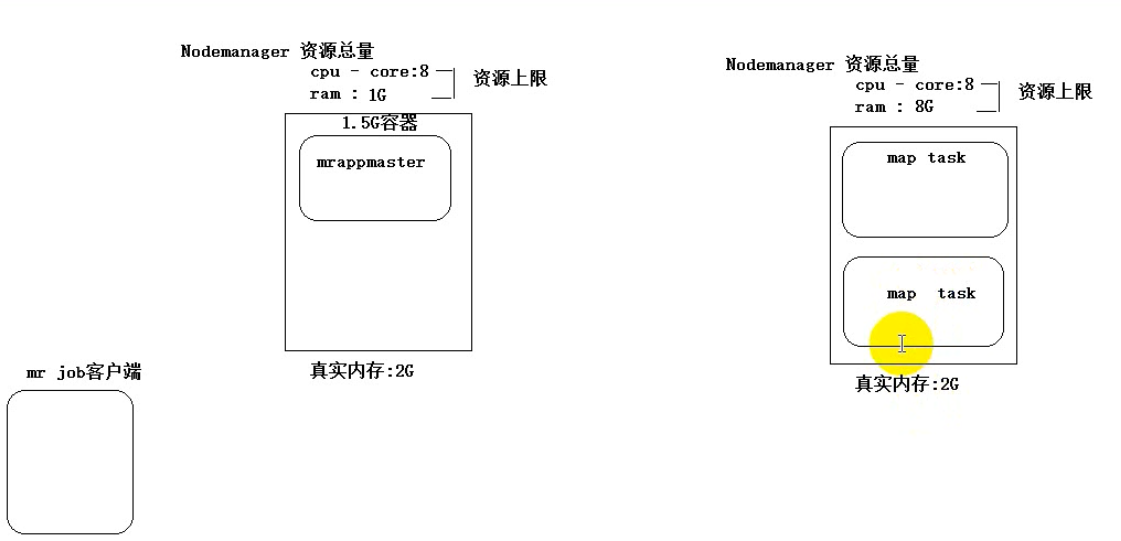
一个运行mapTask reduceTask的容器,默认至少1G内存大小

mrappmaster至少需要1.5G,这个程序 在整个mapreduce程序中之启动一个实例,它是所有mapTask和reduceTask的主管,且要先与task启动,运行在某一台nodemanager机器提供的容器上(容器就是运算资源的抽象)。

3.2.2、复制到每一台机器上
3.2.3、启动yarn集群
逐一启动

批量启动
在hdp-04上,修改hadoop的slaves(可以与hdfs共用)文件,列入要启动nodemanager的机器
然后将hdp-04到所有机器的免密登陆配置好
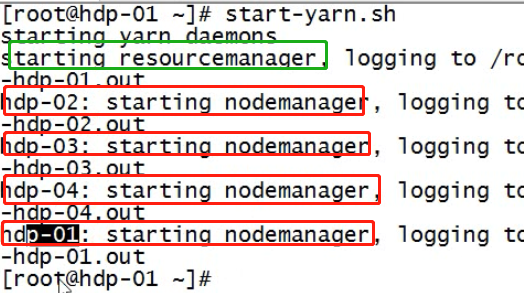
然后,就可以用脚本启动yarn集群:
该自动化脚本与hdfs自动化脚本不同,后者可以在任何的机器上执行,均能正常启动hdfs,而前这只能在resouce manager机器上,因为该脚本启动resouce manager是不会去看配置文件(虽然有),在哪里敲在哪里启动,而启动node manager时会看slaves文件。
sbin/start-yarn.sh #停止: sbin/stop-yarn.sh
3.2.4、检查yarn的进程
用jps检查yarn的进程,用web浏览器查看yarn的web控制台
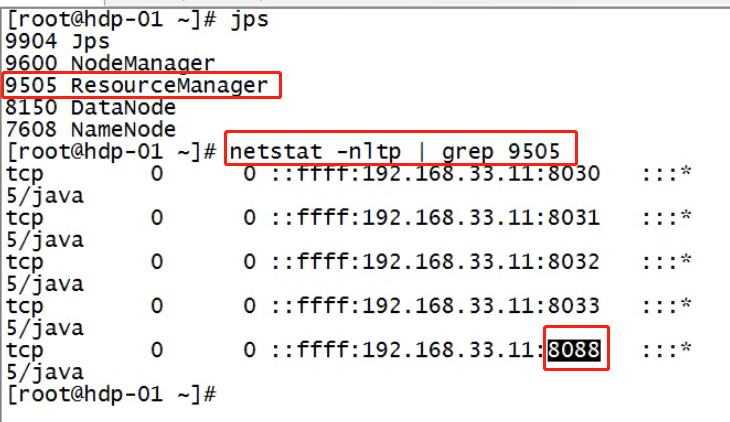
启动完成后,可以在windows上用浏览器访问resourcemanager的web端口8088:
看resource mananger是否认出了所有的node manager节点


上图中的红框表示的内存数其实是有参数来配置的,默认值(一台nodemanager是8G内存,而且是8核),与实际值严重不同。cup核数是一个虚拟值,假设node manager对应的物理机器的可用内存是2G,核数1,而我们在通过配置参数指定了最大的内存为2G,核数为2核,其实将物理机器的1核算力平均分成了两份,作为node manager的2核。