
【5分钟阅读】

【Cadence推出机器学习芯片设计技术Cerebrus】
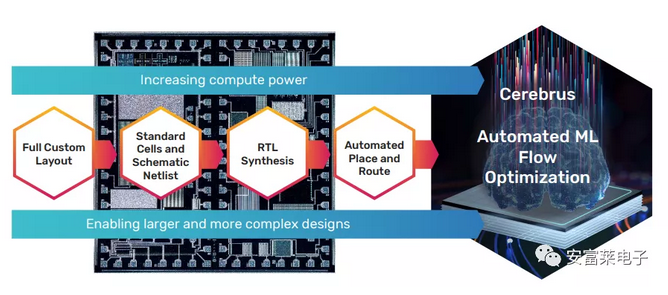
Cadence推出的基于机器学习的Cerebrus智能芯片设计技术,直接集成到Cadence芯片设计工具链中,大大优化PPA(芯片设计三要素,Performance(性能)、Power(功耗)、Area(尺寸))。
【Cadence推出机器学习芯片设计技术Cerebrus】
Cadence推出的基于机器学习的Cerebrus智能芯片设计技术,直接集成到Cadence芯片设计工具链中,大大优化PPA(芯片设计三要素,Performance(性能)、Power(功耗)、Area(尺寸))。

Cerebrus白皮书介绍这个工具帮助一位工程师在 10 天内实现 3.5 GHz 移动 CPU,同时节省泄漏功率、总功率并提高晶体管密度。与几个月内使用近十几名工程师的预测时间线相比,Cerebrus 改进了最佳手调设计,提高了 420 MHz 的频率,节省了 26 mW 的泄漏功率和 62 mW 的总功率。


URL:https://www.cadence.com/en_US/home/company/newsroom/press-releases/pr/2021/cadence-extends-digital-design-leadership-with-revolutionary-ml-.html

【超高速芯片设计公司ADSANTEC】
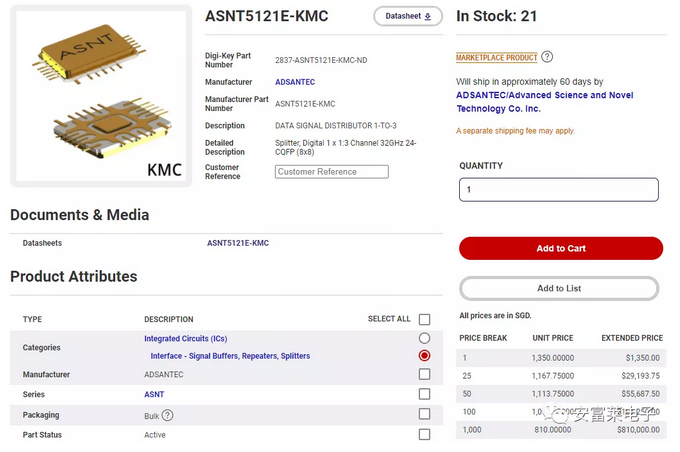
有兴趣可以逛逛这个公司的官网,很开眼,都是几十GHz的模拟和数字IC产品。


搜了下芯片价格,比如这个数据信号分发器ASNT5121E-KMC,售价1000美元。
URL:https://www.adsantec.com/

【RISC-V安全调研】
一篇比较系统的文档《A Survey on RISC-V Security: Hardware and Architecture》:

URL:https://arxiv.org/pdf/2107.04175.pdf

【华邦OctalNAND Flash与新思科技DesignWare AMBA IP完美契合,提供完整的高容量 NAND 闪存解决方案】
作为全球首款8 I/O串列式NAND Flash,与NOR Flash解决方案相同,但更具成本优势。
大多数高容量嵌入式应用中,一般都会将大量系统代码映射到 DRAM 中执行,而OctalNAND Flash的读取传输速率可达每秒240MB,并且具备连续读取的能力,能够大幅度节省传输时间。虽然NAND Flash无法避免内存坏块的出现,但华邦的OctalNAND Flash具备坏块置换功能,可以将坏块映射并做好块替换,从而使主芯片机能够保持数据传输的连续性,并简化高速代码映射的流程,无需主芯片进行跳过坏块的处理方式。

URL:https://www.winbond.com/hq/about-winbond/news-and-events/news/winbond-octalnand-flash-with-synopsys-designware-amba-ip-delivers-highdensity-nand-flash-memory-solution.html?__locale=zh

【ST推出业界首款200mm碳化硅SiC产品】
SiC碳化硅是一种复合半导体材料,在关键、高增长的移动电子和工业应用等方面比硅具有更好的性能和效率。

普及视频:
https://v.qq.com/x/page/t3259diwgfp.html
URL:https://newsroom.st.com/media-center/press-item.html/t4380.html?ecmp=tt22394_gl_social_jul2021l

【Embedded Wizard新做的汽车诊断工具界面案例展示】
这界面效果整的跟网页差不多。






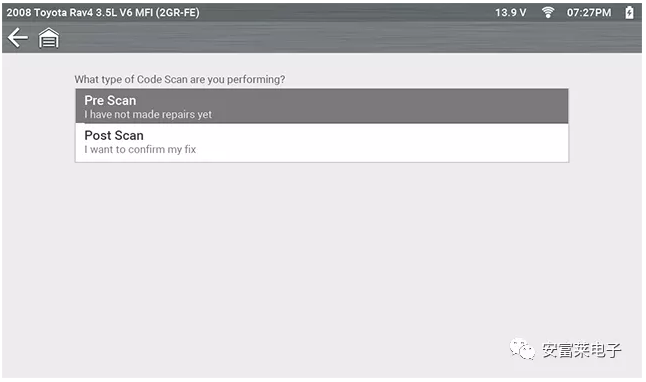
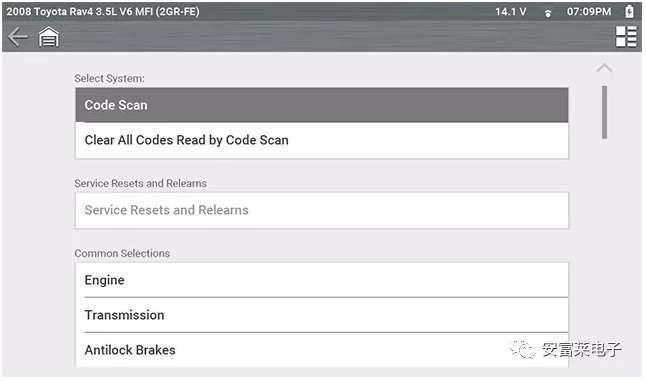
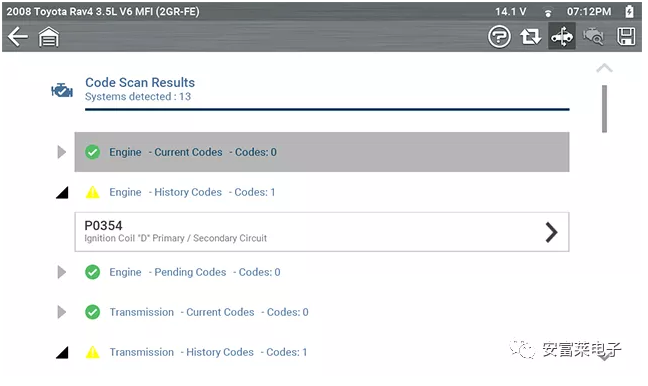
URL:https://www.embedded-wizard.de/cases/snap-on

【30个基于STM32H7的最新版TouchGFX Demo案例】
感谢坛友jnny_cn为我们V7板子提供的30个案例。
30个案例界面效果:
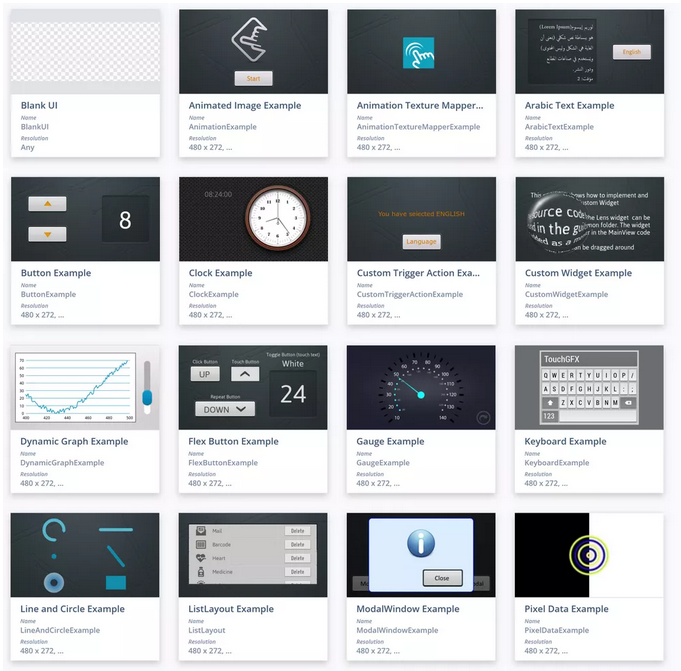

30个例子:
URL:http://www.armbbs.cn/forum.php?mod=viewthread&tid=108039

【花了半天时间,找到CMSIS 5.8.0软件包里面RTX5 底层汇编文件的处理欠妥的地方,ARM这等大厂也有这种骚操作】
这个问题会导致M7F芯片直接硬件异常,为了解决这个问题,倒腾了一下午,一开始研究的方向跑偏了,耽误了不少时间。
当前的RTX5支持MDK,GCC和IAR,所以也专门配套的三种Port文件,我们这里主要说MDK AC6和AC5。
1、先说MDK AC5
这里要说的是MDK AC5的移植文件,当前提供的移植文件irq_armv7m.s(之前是irq_cm4f.s)开头如下:
IF :LNOT::DEF:RTX_STACK_CHECK RTX_STACK_CHECK EQU 0 ENDIF IF ({FPU}="FPv4-SP") FPU_USED EQU 1 ELSE FPU_USED EQU 0 ENDIF
M7单精度要使用FPv5-SP,双精度要使用FPv5-D16。最终修改决定使用 IF {FPU} != "SoftVFP" 判断是否使用软件浮点更简单,屏蔽了用户需要切来切去的问题。
修改后代码如下:
IF :LNOT::DEF:RTX_STACK_CHECK RTX_STACK_CHECK EQU 0 ENDIF IF {FPU} != "SoftVFP" FPU_USED EQU 1 ELSE FPU_USED EQU 0 ENDIF
2、再说MDK AC6
MDK AC5的问题解决了,我使用MDK RTE创建了一个AC6的工程,我一看更惊呆了,直接用的GCC的Port文件。
.syntax unified #include "rtx_def.h" #if (defined(__ARM_FP) && (__ARM_FP > 0)) .equ FPU_USED, 1 #else .equ FPU_USED, 0 #endif .equ I_T_RUN_OFS, 20 // osRtxInfo.thread.run offset .equ TCB_SP_OFS, 56 // TCB.SP offset .equ TCB_SF_OFS, 34 // TCB.stack_frame offset .equ FPCCR, 0xE000EF34 // FPCCR Address .equ osRtxErrorStackOverflow, 1 // Stack overflow
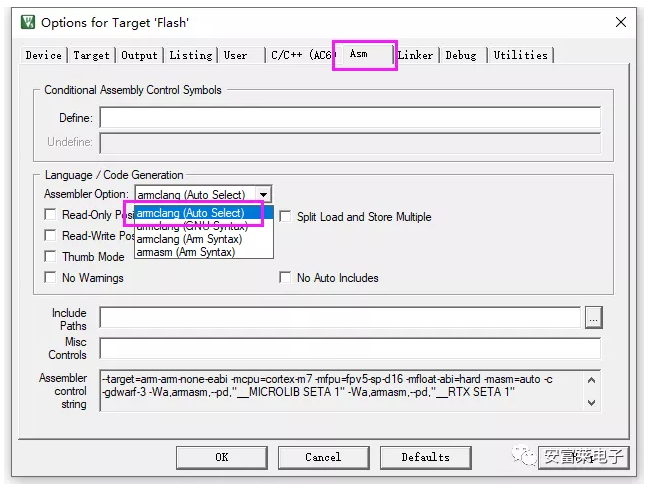
这次新版升级的用户体验略差,究其根本原因是没有考虑M7内核的单精度浮点和双精度浮点使用RTX5的情况。
URL:http://www.armbbs.cn/forum.php?mod=viewthread&tid=108052
