一、&#x和ASCII的关系
以下是常用的,在博客园的插入代码块&#+数字后浏览器也会自动把这些字符数字控制符给显示出来;
  -> 空格 (ASCII码_可显示字符: 32十进制) ( -> ( (ASCII码_可显示字符: 40十进制) ) -> ) (ASCII码_可显示字符: 41十进制) - -> - (ASCII码_可显示字符: 45十进制) : -> : (ASCII码_可显示字符: 58十进制) . -> . (ASCII码_可显示字符: 46十进制) -> 换行符 (ASCII码_控制字符: 10十进制)
Reference: http://ascii.911cha.com/
将这一堆“乱码”保存成网页后,通过浏览器打开又可以正常显示。它的学名叫实体编码 entity code.
在 HTML 中,某些字符是预留的,例如小于号「<」、大于号「>」等,浏览器会将它们视作标签。如果想要在HTML中显示这些预留字符,我们就要用到字符实体(character entities)。我们比较熟悉的字符实体有空格「 」,小于号「<」,大于号「>」等。这样的格式比较语义化,容易记忆,但其实字符实体有其他的格式:
&name;
&#dddd;
&#xhhhh;
1. 这三种转义方式都称作 character reference,第一种是 character entity reference,「&」符号后接预先定义好的 entity 名称。
2. 后两种是 numeric character reference,数字取值为目标字符的 Unicode code point;以「&#」开头的后接十进制数字,「&#x」开头的后接十六进制数字。
从 HTML4 开始,numeric character reference 以 Unicode 为准,与文档编码无关。「你好」二字分别是 Unicode 字符 U+4F60 和 U+597D,十六进制表示的 code point 数值「4F60」和「597D」,同时也就是十进制的「20320」和「22909」。所以
在HTML中输入
都会显示为“你好”。
Reference: https://www.cnblogs.com/philipding/p/10153094.html
二、URL中的中文转义
(1)编写一个测试的网页地址:
路径如为: TEST/你好/index.html,浏览器显示为:

(2)查看该网页的请求头:
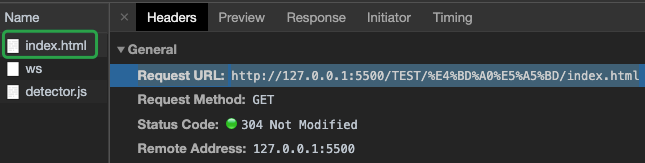
更准确地说是 URI 规范。URL 是 URI 的一种,常见的 URI 通常也都是 URL,一般情况下会混着用两者。关于 URI 规范,具体可见 http://www.ietf.org/rfc/rfc2396.txt 和 http://www.ietf.org/rfc/rfc3986.txt。(后面的为更新的规范)
③URL中的转义表示:
像这样的一串字符"%E4%BD%A0%E5%A5%BD", 其中的每一个部分用【%XX】来表示,其中 XX 表示一个十六进制的数(hexadecimal digits),这样的表示就是所谓的“URL 的转义表示”,也叫“百分号编码”(Percent-Encoding)。如果把其中的百分号 % 去掉,会发现结果是"E4 BD A0 E5 A5 BD",总共 6 个字节,其实就是“主页”两字的 utf-8 编码。
如果你还记得先前说到的 utf-8 的编码模式(参见大神博客: https://xiaogd.net/%e5%ad%97%e7%ac%a6%e9%9b%86%e4%b8%8e%e7%bc%96%e7%a0%81%ef%bc%88%e5%9b%9b%ef%bc%89-unicode/ ),EX XX XX 通常就是常用汉字的模式。
那么现在比较清楚了,URL 路径中的中文需要转义,具体编码用的是 utf-8。包括本文粘贴的地址也是一样.
三、第二中所描述即为"百分比编码"或"URL编码"
百分比编码 是一种拥有8位字符编码的编码机制,这些编码在URL的上下文中具有特定的含义。它有时被称为URL编码。编码由英文字母替换组成:“%” 后跟替换字符的ASCII的十六进制表示。
需要编码的特殊字符有: ':','/','?','#','[',']','@','!','$','&',"'",'(',')','*','+',',',';','=',以及,'%' 本身. 其他的字符虽然可以进行编码但是不需要。
根据上下文, 空白符 ' ' 将会转换为 '+' (必须在HTTP的POST方法中使定义 application/x-www-form-urlencoded 传输方式), 或者将会转换为 '%20' 的 URL。