1、概念
ElementwiseProduct使用逐元素乘法将每个输入向量乘以提供的“权重”向量。换句话说,它通过标量乘法器缩放数据集的每一列。这表示输入向量v和变换向量w之间的Hadamard乘积,以产生结果向量。
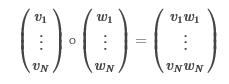
2、code
package com.home.spark.ml import org.apache.spark.SparkConf import org.apache.spark.ml.feature.ElementwiseProduct import org.apache.spark.ml.linalg.Vectors import org.apache.spark.sql.SparkSession /** * ElementwiseProduct使用逐元素乘法将每个输入向量乘以提供的“权重”向量。 * 换句话说,它通过标量乘法器缩放数据集的每一列。这表示输入向量v和变换向量w之间的Hadamard乘积,以产生结果向量。 **/ object Ex_ElementwiseProduct { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf(true).setMaster("local[2]").setAppName("spark ml") val spark = SparkSession.builder().config(conf).getOrCreate() // Create some vector data; also works for sparse vectors val dataFrame = spark.createDataFrame(Seq( ("a", Vectors.dense(1.0, 2.0, 3.0)), ("b", Vectors.dense(4.0, 5.0, 6.0)))).toDF("id", "vector") val transformingVector = Vectors.dense(0.0, 1.0, 2.0) val transformer = new ElementwiseProduct() .setScalingVec(transformingVector) .setInputCol("vector") .setOutputCol("transformedVector") // Batch transform the vectors to create new column: transformer.transform(dataFrame).show() spark.stop() } }
+---+-------------+-----------------+
| id| vector|transformedVector|
+---+-------------+-----------------+
| a|[1.0,2.0,3.0]| [0.0,2.0,6.0]|
| b|[4.0,5.0,6.0]| [0.0,5.0,12.0]|
+---+-------------+-----------------+