1.准备两台虚拟机,配置hosts文件
vim /etc/hosts

加入两台虚拟机的ip 和主机名(两台分别都要配置)
2.配置ssh免密通信
ssh-keygen
ssh-copy-id 主机名
ssh 主机名(测试是否免密成功
3.配置hdfs-site.xfs文件
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
4.配置slaves文件
加入两台主机名
5.若有虚拟机是克隆来的,需清除/dfs内文件

cd dfs
rm -rf *
6.格式化
hadoop namenode -format
7.启动
start-all.sh
访问192.168.0.177:50070
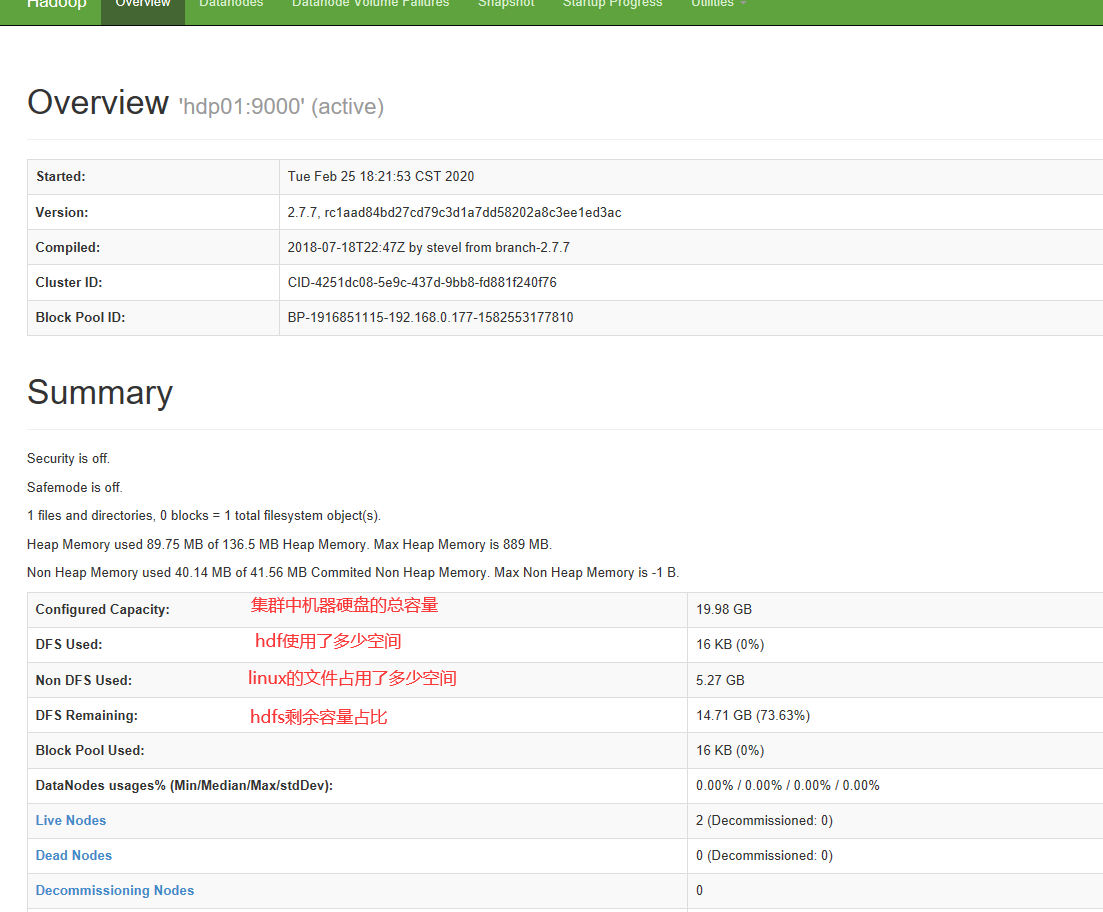
部署后看到有两个节点
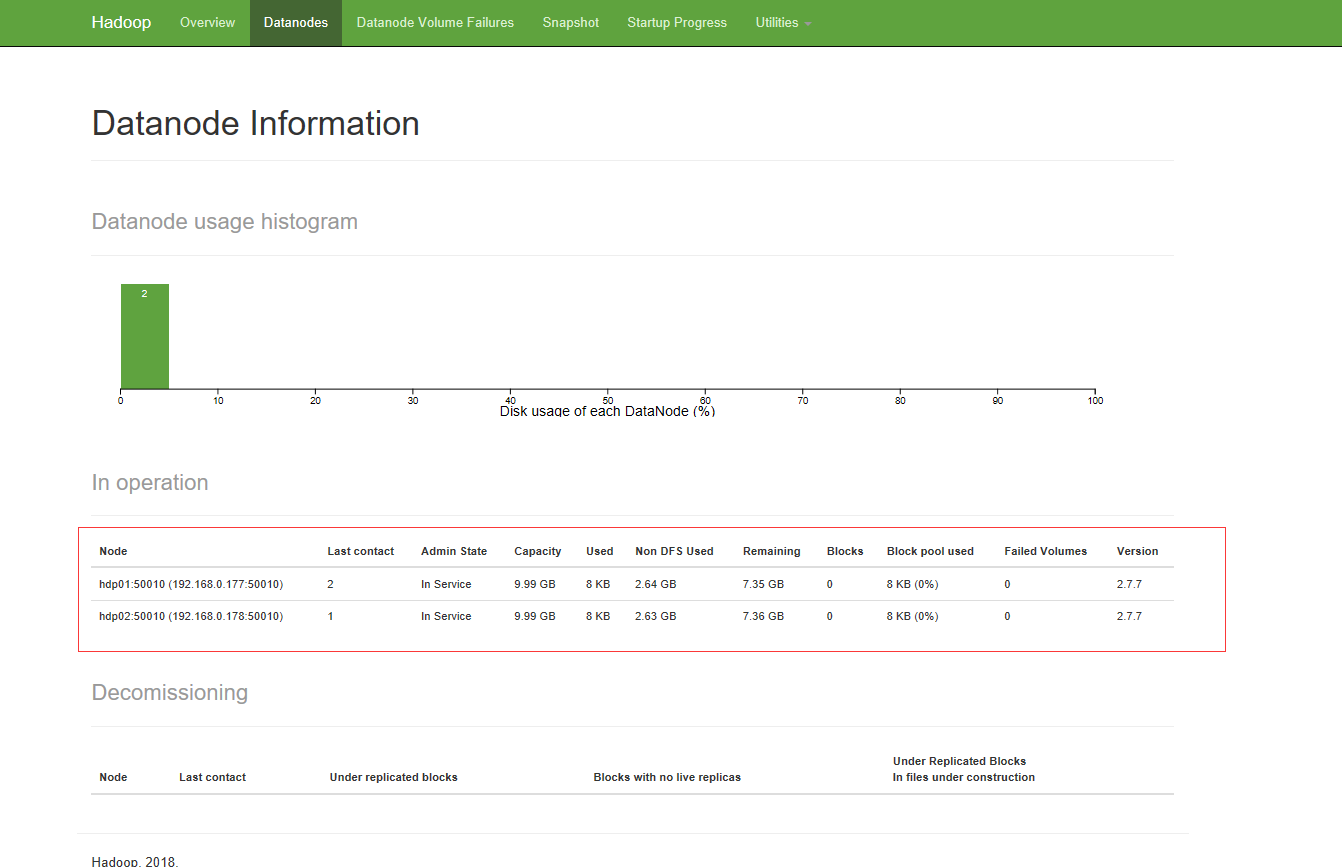
8.指令
start-all.sh 一次性打开5个软件 namenode datanode secondarynamenode resourcemanager nodemanager
stop-all.sh 一次性关闭5个软件
start-dfs.sh 一次性打开3个软件 namenode datanode secondarynamenode HDFS开启服务
stop-dfs.sh 一次性关闭3个软件 namenode datanode secondarynamenode HDFS关闭服务
start-yarn.sh 一次性打开2个软件 resourcemanager nodemanager MapReduce使用的
stop-yarn.sh 一次性关闭2个软件 resourcemanager nodemanager MapReduce使用的
hadoop-daemon.sh start 开启其中一个软件 namenode datanode secondarynamenode
hadoop-daemon.sh stop 关闭其中一个软件