C 代码中嵌入汇编
而 C 中嵌入汇编代码由 gcc 编译器实现的,实现也非常简单,使用由编译器提供的 asm 或者 __asm__ 关键字即可,这两者没有任何区别,然后将需要执行的汇编指令使用("")包含起来即可,对应的汇编指令就会被执行。
我们来看看下面的嵌入汇编代码:
void func(void) { ... asm("mov r1,r0"); __asm__("mov r2,r1"); ... }
代码非常简单,将寄存器 r0 的值赋值给 r1,然后赋值给 r2。这是最简单的汇编指令,但是,通常情况下,这样的汇编代码没有产生输入输出的行为,也就对函数的执行不能做出正向的贡献。
事实上,在子程序的调用时,这种代码可能是有用的,因为在 arm 中 r0~r3 被用来传递参数和返回值。
之所以说正向的贡献是因为这种操作可能产生负面的影响,因为 r0~r2 寄存器很可能正在被程序的其它部分使用而在这里被意外地修改。
而更多地情况是,C 函数中调用汇编函数,是需要汇编指令进行一些特定的操作,然后在 C 函数中使用相应的操作结果,实现 C 和嵌入汇编代码的"交互",这就需要使用到嵌入汇编的另一种表达形式:
asm(code : output operand list : input operand list : clobber list);这种嵌入汇编的形式一共分为四个部分:
- code
- [attr]output operand list
- [attr]input operand list
- clobber list
output operand list:表示输出的操作数,通常是一个或者多个 C 函数中的变量。
input operand list:表示输入的操作数,通常是一个或者多个 C 函数中的变量,attr 部分表示操作数的属性,以字符串的形式提供,是必须的参数。
code:汇编的操作代码,一条或者多条指令,如果是多条指令,需要在指令间使用 隔开。与通用的汇编代码有一些不同:因为支持 C 变量的操作,所以在操作由第二、三部分提供的操作数时,使用 %n 来替代操作数。
clobber list:被破坏的列表,这部分我们放到后面讨论。
看下面的示例:
void func(void) { int val1 = 111,val2 = 222; asm("mov %0,%1" :"+r"(val1) :"r"(val2) :); printf("val1 = %d ",val1); }
先说结论:func 函数的输出结果为:
val1 = 222显然,val1 的值原本是 111,val2 的值为 222,嵌入汇编指令部分实现了将 val2 的值赋值给 val1.
由上面对指令语法的描述进行分析:
- 输出操作数为 val1,属性为 "=r"。
- 输入操作数为 val2,属性为 "r"
- code 部分为 mov %1,%0, %0 表示输入输出列表中的第一个操作数,%1 表示操作数列表中提供的第二个操作数,以此类推,这条汇编指令很明显就是将第二个操作数(val2)赋值给第一个操作数(val1),所以最后的结果为 val1 = 222. 。
code 中的操作数命名顺序为输出操作书列表递增,输入操作数列表递增,比如增加一个操作数的代码为:int val1 = 111,val2 = 222,val3=333; asm("mov %0,%2" :"+r"(val1) :"r"(val2),"r"(val3) :);
操作数属性值
在上述的示例中,输入操作数和输出操作数都会使用到 attr 字段,即操作数的属性,下面是其属性对应的列表:
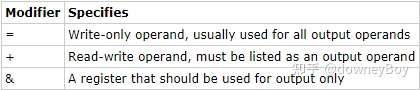
- "=" 表示只写,通常用于所有输出操作数的属性
- "+" 表示读写,只能被列为输出操作数的属性,否则编译会报错。
在输出操作数中,必须指定其中一个。
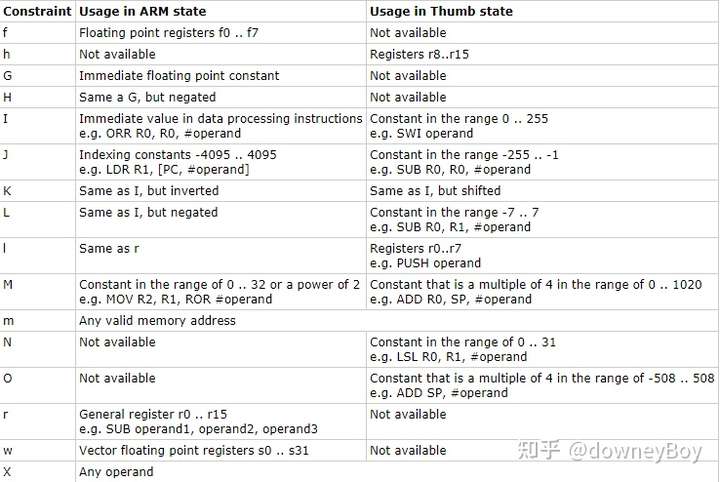
从图中可以看出,除了最常应用到的 "r" 属性(使用通用寄存器处理操作数),还有其他的很多特性,包括使用浮点寄存器 ("f"),或者使用立即数("I")等等,对于 arm 和 thumb 指令集也有较大的区别。
clobber list
接下来我们来讨论 asm 表达式的第四部分,也就是 clobber list,clobber 的意思为破坏,在这里的意思是:这段汇编指令将会破坏哪些寄存器的值。
这个问题看起来有点奇怪,嵌入汇编代码和 C 代码都是由 gcc 统一编译的,难道 gcc 不能分析出汇编代码中使用了哪些寄存器,而非要人为来指定?
答案还真就是这样,在目前的 gcc 设计中,编译分为4个过程:预编译、编译、汇编、链接。
其中,编译就是将 C 代码编译成汇编代码,而通用的汇编代码在这个过程是不会处理的,也就是说,嵌入汇编代码的解析只涉及到输入输出操作数的替换,对于不包含输入输出操作数的部分不会解析,所以在编译阶段,编译器不会知道嵌入汇编代码中静态地使用到哪些寄存器,而是自顾自地编译 C 代码,从而导致 C 代码和嵌入汇编代码操作到同一个寄存器,而出现错误。
比如下面的代码:
other
volatile表示告诉编译器不要做优化,保持asm code原样。
一条asm指令后面加 用来隔开两条asm指令
from:
https://zhuanlan.zhihu.com/p/362897071
获取ARM register value in C code
unsigned long ttbr0_el1_val; unsigned long ttbr1_el1_val; asm ("mrs %0, ttbr0_el1" : "=r" (ttbr0_el1_val)); asm ("mrs %0, ttbr1_el1" : "=r" (ttbr1_el1_val)); pr_info("ttbr0_el1_val is %#lx. ", ttbr0_el1_val); pr_info("ttbr1_el1_val is %#lx. ", ttbr1_el1_val);
.long/.string
.long表示在这个地址开辟一个long型的空间
.string表示在这个地址将源string存储到这个位置,会自动加上/0字符串结束符
#define __BUGVERBOSE_LOCATION(file, line) .pushsection .rodata.str,"aMS",@progbits,1; 14472: .string file; .popsection; .long 14472b - 14470b; .short line;
asm里label相减
如上面的14472b - 14470b,这个表示label所表示的地址相减