分组排序是干什么的?
在Hadoop的Reduce阶段中的reduce方法中默认每一组数据调用该方法,那么什么是一组数据呢?
如果Reduce阶段输入的key相同那么就认为是一组数据
简单的说,在开发中,往往将数据封装到bean对象中,又因为bean对象中有多个字段,如果我们这些字段不完全相同
那么就不是相同的key也就不能成为一组数据,就导致了多次调用reduce方法
这种情况下,我们使用分组排序(辅助排序),就是把bean对象中的某一个字段进行比较,如果这个字段相同,我们就认为是相同的key。
关于分组排序(辅助排序)使用的注意事项
1、我们需要自定义一个类继承WritableComparator类(是继承不是实现)
2、重写compareTo方法
3、在我们的自定义类中,需要添加构造器

传入三个参数:
1)传入一个对象
2)配置信息,可以写空
3)要传入true,为什要写true,进入super的源码看一下
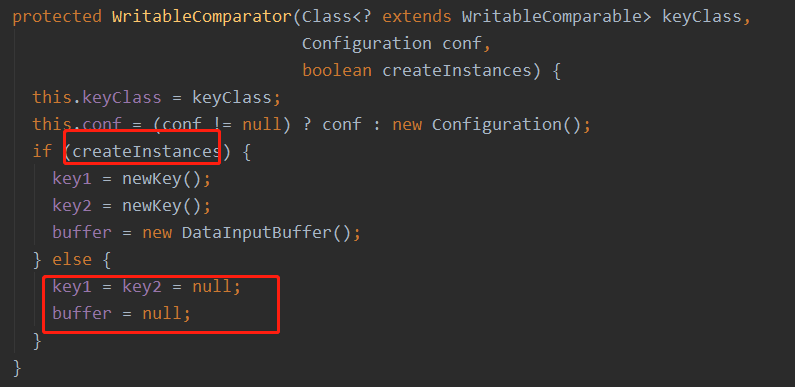
在父类的源码中,第三个参数决定是否创建key的对象,如果不是createInstances不是true就没有这个对象,那么程序就会报空指针异常。
4、在Deiver中设置分组比较器为自定义的类