
Logstash 是一款强大的数据处理工具,它可以实现数据传输,格式处理,格式化输出,还有强大的插件功能,常用于日志处理。
一、原理
- Input
可以从文件中、存储中、数据库中抽取数据,Input有两种选择一个是交给Filter进行过滤、修剪。另一个是直接交给Output - Filter
能够动态地转换和解析数据。可以通过自定义的方式对数据信息过滤、修剪 - Output
提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。

二、安装使用
1.安装
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.0.1.rpm
yum install -y ./logstash-6.0.1.rpm
2.Logstash配置文件
vim /etc/logstash/logstash.yml
path.data: /var/lib/logstash # 数据存放路径
path.config: /etc/logstash/conf.d/*.conf # 其他插件的配置文件,输入输出过滤等等
path.logs: /var/log/logstash # 日志存放路径
3.Logstash中的JVM配置文件
Logstash是一个基于Java开发的程序,需要运行在JVM中,可以通过配置jvm.options来针对JVM进行设定。比如内存的最大最小、垃圾清理机制等等。这里仅仅列举最常用的两个。
JVM的内存分配不能太大不能太小,太大会拖慢操作系统。太小导致无法启动。
vim /etc/logstash/jvm.options # logstash有关JVM的配置
-Xms256m # logstash最大最小使用内存
-Xmx1g
4.最简单的日志收集配置
安装一个httpd用于测试,配置Logstash收集Apache的accless.log日志文件
yum install httpd
echo "Hello world" > /var/www/html/index.html # 安装httpd,创建首页用于测试
vim /etc/logstash/conf.d/test.conf
input {
file { # 使用file作为数据输入
path => ['/var/log/httpd/access_log'] # 设定读入数据的路径
start_position => beginning # 从文件的开始处读取,end从文件末尾开始读取
}
}
output { # 设定输出的位置
stdout {
codec => rubydebug # 输出至屏幕
}
}
5.测试配置文件
logstash是自带的命令但是没有再环境变量中,所以只能使用绝对路径来使用此命令。
/usr/share/logstash/bin/logstash -t -f /etc/logstash/conf.d/test.conf # 测试执行配置文件,-t要在-f前面
Configuration OK # 表示测试OK
6.启动logstash
在当前会话运行logstash后不要关闭这个会话暂时称其为会话1,再打开一个新的窗口为会话2
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/test.conf
启动以后在会话2中使用curl命令进行测试
curl 172.18.68.14
然后在回到之前的会话1可以看到输出的信息
{
"@version" => "1",
"host" => "logstash.shuaiguoxia.com",
"path" => "/var/log/httpd/access_log",
"@timestamp" => 2017-12-10T14:07:07.682Z,
"message" => "172.18.68.14 - - [10/Dec/2017:22:04:44 +0800] "GET / HTTP/1.1" 200 12 "-" "curl/7.29.0""
}
至此最简单的Logstash配置就已经完成了,这里仅仅是将收集到的直接输出没有进行过滤或者修剪。
三、Elasticsearch与Logstash
上面的配置时Logsatsh从日志文件中抽取数据,然后输出至屏幕。那么在生产中往往是将抽取的数据过滤后输出到Elasticsearch中。下面讲解Elasticsearch结合Logstash
Logstash抽取httpd的access.log文件,然后经过过滤(结构化)之后输出给Elasticsearch Cluster,在使用Head插件就可以看到抽取到的数据。(Elasticsearch Cluster与Head插件搭建请查看前两篇文章)
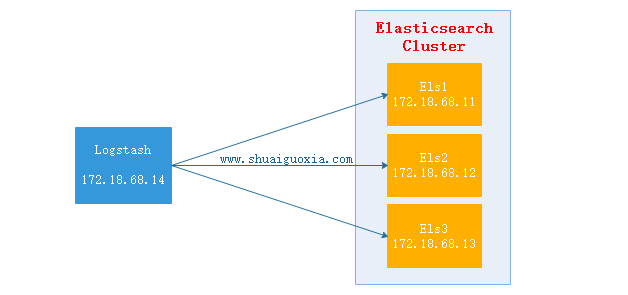
- 配置Logstash
vim /etc/logstash/conf.d/test.conf
input {
file {
path => ['/var/log/httpd/access_log']
start_position => "beginning"
}
}
filter {
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}"
}
remove_field => "message"
}
}
output {
elasticsearch {
hosts => ["http://172.18.68.11:9200","http://172.18.68.12:9200","http://172.18.68.13:9200"]
index => "logstash-%{+YYYY.MM.dd}"
action => "index"
document_type => "apache_logs"
}
}
- 启动Logstash
/usr/share/logstash/bin/logstash -t -f /etc/logstash/conf.d/test.conf # 测试配置文件
Configuration OK
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/test.conf # 启动Logstash
- 测试
每个执行10次172.18.68.14,位Logstash的地址
curl 127.0.0.1
curl 172.18.68.14
- 验证数据
使用浏览器访问172.18.68.11:9100(Elastisearch 安装Head地址,前面文章有讲)
选择今天的日期,就能看到一天内访问的所有数据。
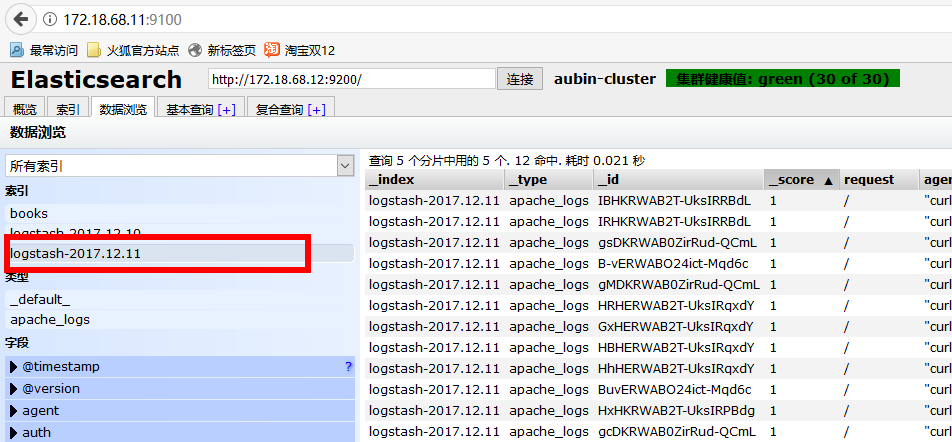
四、监控其他
- 监控Nginx日志
仅仅列了filter配置块,input与output参考上一个配置
filter {
grok {
match => {
"message" => "%{HTTPD_COMBINEDLOG} "%{DATA:realclient}""
}
remove_field => "message"
}
date {
match => ["timestamp","dd/MMM/YYYY:H:m:s Z"]
remove_field => "timestamp"
}
}
- 监控Tomcat
仅仅列了filter配置块,input与output参考上一个配置
filter {
grok {
match => {
"message" => "%{HTTPD_COMMONLOG}"
}
remove_field => "message"
}
date {
match => ["timestamp","dd/MMM/YYYY:H:m:s Z"]
remove_field => "timestamp"
}
}
五、Filebeat
现在已经搭建成在节点安装Logstash并发送到Elasticsearch中去,但是Logstash是基于Java开发需要运行在JVM中,所以是一个重量级采集工具,仅仅对于一个日志采集节点来说使用Logstash太过重量级,那么就可以使用一个轻量级日志收集工具Filebeat来收集日志信息,Filebeat同一交给Logstash进行过滤后再Elasticsearch。这些在接下来的文章在进行讲解,先放一张架构图吧。
