1. 应用K-means算法进行图片压缩
读取一张图片
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
观察压缩图片的文件大小,占内存大小
首先来看一下完整代码:
from sklearn.datasets import load_sample_image from matplotlib import pyplot as plt from sklearn.cluster import KMeans import numpy as np import sys #读取一张sklearn.datasets里的图片china.jpg china = load_sample_image('china.jpg') plt.show() #观察china图片的大小和内存 print("china图片原大小:",china.size) print("china图片原内存:",sys.getsizeof(china)) #根据图片的分辨率,可适当降低分辨率 img=china[::4,::4] #降低分辨率 x=img.reshape(-1,3) #生成行数未知,列数为3 #将图片中所有的颜色值做聚类,然后获取每个像素的颜色类别,每个类别的颜色。 n_colors=64 model=KMeans(n_colors) labels=model.fit_predict(x) #每个点颜色分类,训练x colors=model.cluster_centers_#找聚类点 new_img=colors[labels].reshape(img.shape) #形成新的图片 plt.imshow(new_img.astype(np.uint8)) plt.show() #观察新图片的大小与所占用内存的大小。 print("压缩后大小:",new_img.size) print("压缩后内存:",sys.getsizeof(new_img))
一开始最困难的一件事就是安装图像数据库,尝试了各种办法都安装不了PIL,查了才知道PIL库最多支持到python2的版本,我使用的是python3.7版本所以安装不了PIL。然后查了csdn知道3.7版本可以直接安装Pillow库,这个库里包涵了PIL,所以安装后就解决了。(ps:因为最新的7.1.1版本用不了,所以我安装的是低版本的Pillow库)

原图片:

经过k-means聚类后新图片:

图片各种信息:

2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。
本案例主要是研究汽车价格与已行驶里程数的关系:
详细代码:
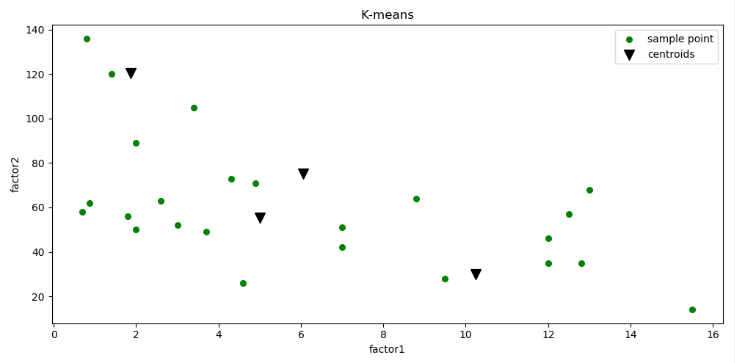
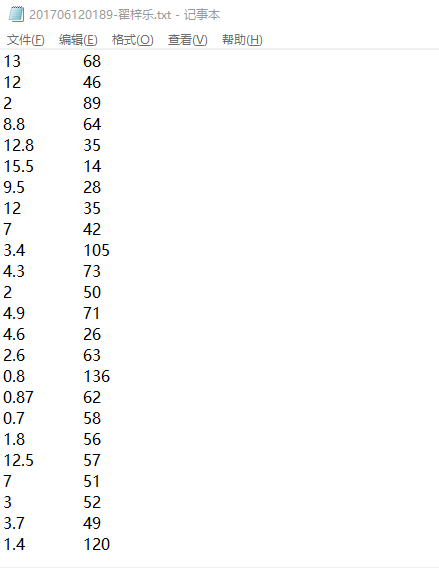
# KMeans聚类分析 import numpy as np import matplotlib.pyplot as plt def load_dataset(file_name): data_mat = [] with open(file_name) as fr: lines = fr.readlines() for line in lines: cur_line = line.strip().split(" ") flt_line = list(map(lambda x:float(x), cur_line)) data_mat.append(flt_line) return np.array(data_mat) data_set = load_dataset(r"./data/201706120189-翟梓乐.txt") #从文本文件中读入数据到矩阵 print(data_set) def dist_eclud(vecA, vecB): #欧几里得距离函数 vec_square = [] for element in vecA - vecB: element = element ** 2 vec_square.append(element) return sum(vec_square) ** 0.5 def rand_cent(data_set, k): #构建k个随机质心 n = data_set.shape[1] centroids = np.zeros((k, n)) for j in range(n): min_j = float(min(data_set[:,j])) range_j = float(max(data_set[:,j])) - min_j centroids[:,j] = (min_j + range_j * np.random.rand(k, 1))[:,0] return centroids def Kmeans(data_set, k): #定义K-means函数实现算法 m = data_set.shape[0] cluster_assment = np.zeros((m, 2)) centroids = rand_cent(data_set, k) cluster_changed = True while cluster_changed: cluster_changed = False for i in range(m): min_dist = np.inf; min_index = -1 for j in range(k): dist_ji = dist_eclud(centroids[j,:], data_set[i,:]) if dist_ji < min_dist: min_dist = dist_ji; min_index = j if cluster_assment[i,0] != min_index: cluster_changed = True cluster_assment[i,:] = min_index, min_dist**2 for cent in range(k): pts_inclust = data_set[np.nonzero(list(map(lambda x:x==cent, cluster_assment[:,0])))] centroids[cent,:] = np.mean(pts_inclust, axis=0) return centroids, cluster_assment my_centroids, my_cluster_assment = Kmeans(data_set, 4) print(my_centroids) # 建立图形 point_x = data_set[:,0] point_y = data_set[:,1] cent_x = my_centroids[:,0] cent_y = my_centroids[:,1] fig, ax = plt.subplots(figsize=(10,5)) ax.scatter(point_x, point_y, s=30, c="green", marker="o", label="sample point") ax.scatter(cent_x, cent_y, s=100, c="black", marker="v", label="centroids") ax.legend() ax.set_xlabel("factor1") ax.set_ylabel("factor2") plt.title('K-means') plt.show() plt.savefig(“julei.png”)
从售卖二手车网站爬取的资料(已经过数据处理),分别是同一类车型的价格和已行驶里程数据:
用k-means算法来分析他们之间的关系:
由图可以看出,在二手车交易中汽车价格越低行驶里程数就会越高,也可以说二手车的已行驶里程数会影响车的价格,所以行驶里程与价格有着很大的关系: