P205 MapReduce的两种运行机制
第一种:经典的MR运行机制 - MR 1
可以通过一个简单的方法调用来运行MR作业:Job对象上的submit()。也可以调用waitForCompletion(),用于提交以前没有提交的作业,并等待其完成。
Hadoop执行MR的方法依赖于两个配置设置
mapred.job.tracker - 决定执行MR程序的方式
如果设置为local默认值,表示使用本地的作业运行器,在单个JVM上运行整个作业,用于小数据集测试
如果设置为主机端口对,那么被解释为一个jobtracker地址,运行器会将作业提交给该地址的jobtracker。
第二种:全新的MR运行机制 - MR 2 - YARN(yet another resource negotiator)
对于节点数超出4000的大型集群,MR1面临拓展性瓶颈。这使得YARN应运而生。
通过 mapreduce.framework.name 属性进行设置
设置为local表示本地的作业运行器
设置为classic表示MR1运行模式
设置为yarn表示启用yarn运行机制
P206 剖析经典的MR1 作业运行机制
这个运行机制下包含有4个独立的实体:
1、请求发出者 - 客户端
2、作业调度者 - jobtracker
3、作业执行者 - tasktracker
4、资源提供者 - 分布式文件系统HDFS
工作流程原理如下:

步骤:
1、客户端提交作业(步骤1-4)
请求作业ID -> 将作业所需资源复制到以作业ID命名的文件目录下 -> 告知jobtracker准备执行作业
2、作业初始化(步骤5-6)
jobtracker将提交的作业放入内部队列中,交给作业调度器进行调度,并创建一个表示正在运行作业的对象进行作业初始化。
在这个过程中会创建4种任务交给jobtracker去分配和执行:
① map任务 - 任务个数由步骤6计算好的输入分片决定,有多少输入分片就创建多少map任务
② reduce任务-由mapred.reduce.tasks决定任务数量
③ 作业创建任务 - 在map任务运行前运行代码创建作业 - 运行在tasktracker中 - 为作业创建输出路径和临时工作空间
④ 作业清理任务 - 所有reduce任务完成奇偶进行作业清理工作 - 运行在tasktracker中 - 清除作业运行过程中创建的临时目录
3、jobtracker 分配任务(步骤7)
tasktracker通过运行一个简单循环来和jobtracker定期保持心跳,以此判断tasktracker是否存活,同时充当两者之间的消息通道。
tasktracker会表示他是否已经准备好运行新的任务,如果是,则jobtracker会为他分配一个任务。
在jobtracker为tasktracker指定任务之前,jobtracker需要先选定一个作业,才能将作业中的一个任务指派给tasktracker。
对于map任务,jobtracker会考虑tasktracker的网络位置,选择距离其输入分片文件最近的tasktracker,减少带宽消耗。最理想的是数据本地化。
而对于reduce任务,jobtracker直接从待运行的reduce任务列表中选取下一个来执行,不用考虑数据的本地化。
4、tasktracker 执行任务(步骤8-10)
第一步:从HDFS把所需资源复制到执行任务本地磁盘。
第二步:tasktracker为任务新建一个本地工作目录,将文件拷贝到目录下
第三步:tasktracker新建一个TaskRunner实例来运行任务(TaskRunner通过启用JVM来运行每个任务)
5、进度和状态的更新
MR作业是长时间运行的批量作业,因此一个作业和它下面的每个任务都有一个状态,包括:
① 作业和任务的状态 - 运行?失败?完成?
② map和reduce的进度
③ 作业计数器的值
④ 状态消息或描述
客户端可以使用Job类的getStatus()方法来得到一个JobStatus实例,包含有作业的所有状态信息。
6、作业的完成
当jobtracker收到作业的最后一个任务已完成的通知后(通常是作业清理任务),便将作业的状态设置为“成功”。
P213 剖析 YARN(MR2)升级的作业运行机制
针对节点数大于4000的集群而设计的新一代的MR,将jobtracker的职能划分为多个独立的实体,改善MR1面临的扩展瓶颈问题。
YARN设计为两个独立的守护进程:
1、管理集群资源的资源管理器
2、管理集群任务运行的应用管理器
基本思路:应用管理器与资源管理器协商集群的计算资源:容器。
在容器上运行特定的应用程序进程。
容器由集群节点上运行的节点管理器监视,以确保应用程序使用的资源不会超过分配给他的资源。
YARN 运行机制比MR1包含更多的实体:
1、请求发出者 - 提交MR作业的客户端
2、资源分配者 - YARN资源管理器 - 负责协调集群上计算资源和容器的分配(强调分配)
3、监控观察者 - YARN节点管理器 - 负责启动和监视集群中机器上的计算容器(强调监视管理)
4、任务协调者 - 应用程序 master - 负责协调运行MR作业的任务,master和任务都在容器中运行(强调协调)
5、资源提供者 - 分布式文件系统 HDFS
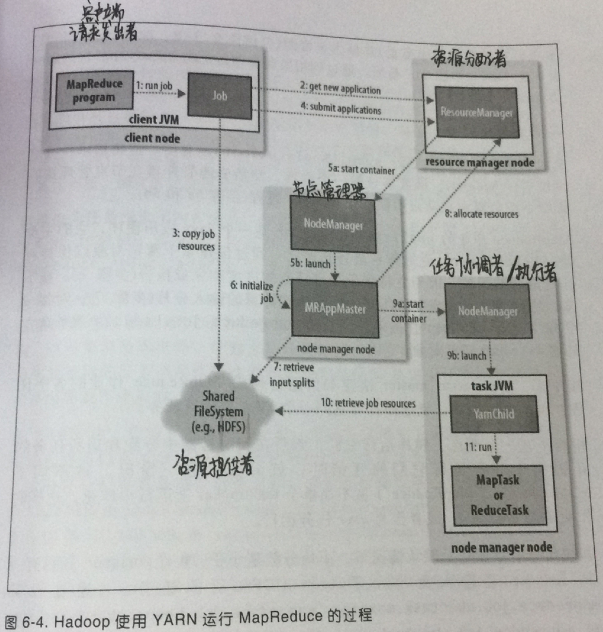
作业运行流程如图:
步骤:
1、作业提交(步骤1-4)
提交的过程和MR1非常相似,区别在于是从资源管理器而不是jobtracker获取作业ID(在yarn中命名为应用程序ID)
客户端检查作业的输出说明,计算作业的输入分片并将作业资源复制到HDFS,最后,调用资源管理器的submitApplication()方法提交作业。
2、初始化作业(步骤5-7)
提交application后,将请求传递给调度器以分配一个容器,然后资源管理器在节点管理器的管理下在容器中启动应用程序的master进程。(5a5b)
master的主类是MRAppMaster,他对作业进行初始化。
通过创建多个簿记对象保持对作业进度的跟踪,簿记对象将接收来自任务的进度和完成报告。(步骤6)
然后,接受客户端创建的输入分片,对每一个分片创建一个map任务对象以及由mapreduce.job.reduces属性配置的多个reduce任务对象。(步骤7)
在任何任务运行前,需要由 master 先建立作业的输出目录。
3、分配任务(步骤8)
master为作业中的map和reduce任务向资源管理器请求容器(步骤8)。
理想情况下,先将任务分配到数据本地化的节点,如果不行,再优先分配到机架本地化的节点,以节省贷款资源。
任务内存分配:默认分配1024MB(1GB)内存,如需要设置,就配置mapreduce.,map.memory.mb和mapreduce.reduce.memory.mb
4、执行任务(步骤9-11)
① 一旦为任务分配了容器,master就通过与节点管理器通信来启动容器(9a9b)
②在运行任务前,现将任务需要的资源本地化。(步骤10)
③ 最后,任务由主类为YarnChild的Java程序执行。
5、进度和状态更新
任务通过umbilical每3s向application master汇报进度和状态(包括计数器)
相比下,MR1通过tasktracker到jobtracker来实现进度更新
6、完成作业
客户端每5s调用Job的waitForCompletion()来查询作业是否完成,查询间隔可通过mapreduce.client.completion.pollinterval设置
作业完成后,master 和任务容器清理其工作状态。
P220 一些常用任务参数配置
mapred.task.timeout - 配置任务失败超时时间
mapreduce.map.max.attempts - 配置map任务重试次数 默认4次 超过4次 标记任务为失败
mapreduce.reduce.max.attempts - 配置reduce任务重试次数 超过4次 标记任务为失败
mapred.max.map.failures.percent - 配置允许map任务失败的最大百分比
mapred.max.reduce.failures.percent - 配置允许map任务失败的最大百分比
如果map和reduce任务执行都超过这个百分比,整个作业都宣告失败
mapred.tasktracker.expiry.interval - 配置tasktracker和jobtracker保持心跳的时间间隔,以毫秒为单位。
P230 配置调优


