目的意义
爬取某地的酒店价格信息,示例使用selenium在Firefox中的使用。
来源
少部分来源于书。python爬虫开发与项目实战
构造
本次使用简易的方案,模拟浏览器访问,然后输入字段,查找,然后抓取网页中的信息。存储csv中。然后再转换为Excel,并对其中的数据进行二次处理。
代码
整个过程相当于获取网页,下载,然后粗糙的存储过程,最终完成。
不能理解的是,这样是使用了Phantomjs么。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import re
import csv
import time
class goWhere():
def __init__(self):
self.toCity=u'焦作'
self.driver=webdriver.Firefox()
self.driver.get("https://hotel.qunar.com/")
self.get_element()
for i in range(30):
self.get_response()
self.parser_store()
self.get_next_page()
def get_element(self):
self.elem_toCity=self.driver.find_element_by_name(u"toCity")
self.elem_fromDate=self.driver.find_element_by_name(u"fromDate")
self.elem_toDate=self.driver.find_element_by_name(u"toDate")
self.elem_search=self.driver.find_element_by_class_name('search-btn')
self.elem_toCity.clear()
self.elem_toCity.send_keys(self.toCity)
self.elem_search.click()
def get_response(self):
for i in range(5):
try:
WebDriverWait(self.driver,30).until(EC.presence_of_element_located((
By.CLASS_NAME,"item_price")))
break
except Exception as e:
self.driver.refresh()
print(e)
if(i==10):
self.driver.close()
exit()
js="window.scrollTo(0,document.body.scrollHeight);"
self.driver.execute_script(js)
time.sleep(5)
self.all=self.driver.find_elements_by_class_name("b_result_bd")
if(len(self.all)<16 or self.all[0].text==''):
self.driver.refresh()
self.get_response()
def parser_store(self):
pattern=re.compile('(.*s?)')
for each in self.all:
each_text=re.findall(pattern, each.text)
print(each_text)
with open('text.csv','a',encoding='gb18030',newline='') as f:
f_csv=csv.writer(f,)
if len(each_text)==8:
each_text.pop(5)
if len(each_text)==6:
each_text.insert(2,'None')
f_csv.writerow(each_text)
print('finished')
def get_next_page(self):
self.nextBtn=self.driver.find_element_by_class_name('next')
self.nextBtn.click()
if __name__=='__main__':
goWhere()
print('task finish')
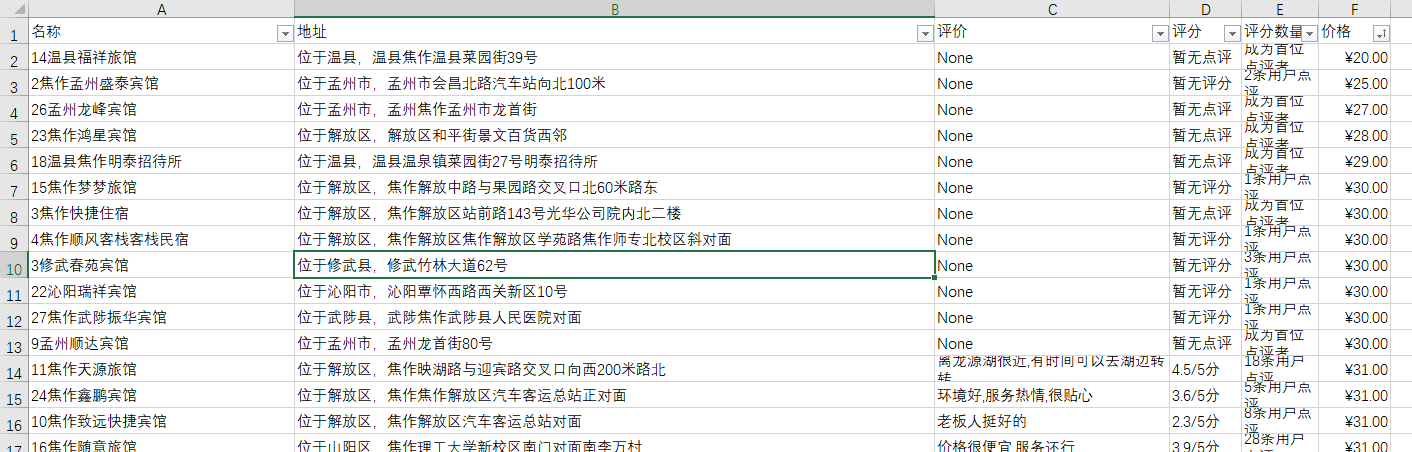
效果举例
二次处理的过程包括处理价格中的??,处理查看地图,处理礼品卡等字段,然后去掉起字,设定价格单元格为人民币格式。
后续
在实际操作过程中,有时网页不容易加载完成,有时加载正常。本次爬取的界面为26个左右共计780余数据。并没有完成数据爬取过程。