作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。
输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
1)代码
import requests,os
from bs4 import BeautifulSoup
from time import time
import threading
# 保存图片
def saveImg(url, path):
print(url)
r = requests.get(url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
# 获得网页的所有img标签
def getImgs(url):
r = requests.get(url)
r.encoding = "UTF-8"
soup = BeautifulSoup(r.text,"html.parser")
imgs = soup.findAll("img")
return imgs
# 单线程
def oneThread():
for img in imgs:
imgurl = img['src']
pos = imgurl.rindex("/")
imgpath = path1 + imgurl[pos+1:]
saveImg(imgurl,imgpath)
# 多线程
def multiThreads():
threads = []
for img in imgs:
imgurl = img['src']
# 取最后一个/之后的字符串作为文件名
pos = imgurl.rindex("/")
imgpath = path2 + imgurl[pos+1:]
T = threading.Thread(target=saveImg,args=(imgurl,imgpath))
T.setDaemon(False)
T.start()
threads.append(T)
for t in threads:
t.join()
url = "http://www.weather.com.cn"
imgs = getImgs(url)
path1 = "C:/image/work3/imgs1/"
path2 = "C:/image/work3/imgs2/"
t1 = time()
# 执行其中一个,注释另外一个
oneThread()
# multiThreads()
t2 = time()
print("共耗时:"+str(t2-t1)+"s")
图片
单线程
多线程

保存后的图片
2)心得体会
第一次使用python多线程,速度还挺快,有催人跑的意思。
作业②:
要求:使用scrapy框架复现作业①。
输出信息:
同作业①
1)代码
mySpider.py
import scrapy
from saveImage.items import ImageItem
class MySpider(scrapy.Spider):
name = "mySpider"
def start_requests(self):
url = "http://www.weather.com.cn"
yield scrapy.Request(url,self.parse)
def parse(self,response):
try:
data = response.body.decode()
selector = scrapy.Selector(text=data)
# 获得所有img标签的src属性
urls = selector.xpath("//img/@src").extract()
for url in urls:
item = ImageItem()
item['imgurl'] = url
yield item
except Exception as err:
print(err)
pipelines.py
from itemadapter import ItemAdapter
import requests
def saveImg(url, path):
print(url)
r = requests.get(url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
class SaveimagePipeline:
path = "C:/image/work3/imgs3/"
def process_item(self, item, spider):
try:
imgurl = item['imgurl']
print(imgurl)
pos = imgurl.rindex("/")
imgpath = self.path + (imgurl[pos+1:])
saveImg(imgurl,imgpath)
except Exception as e:
print(e)
return item
run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=False".split())
图片

2)心得体会
第一次使用scrapy框架,照着书稍微改改,受益匪浅。
作业③:
要求:使用scrapy框架爬取股票相关信息。
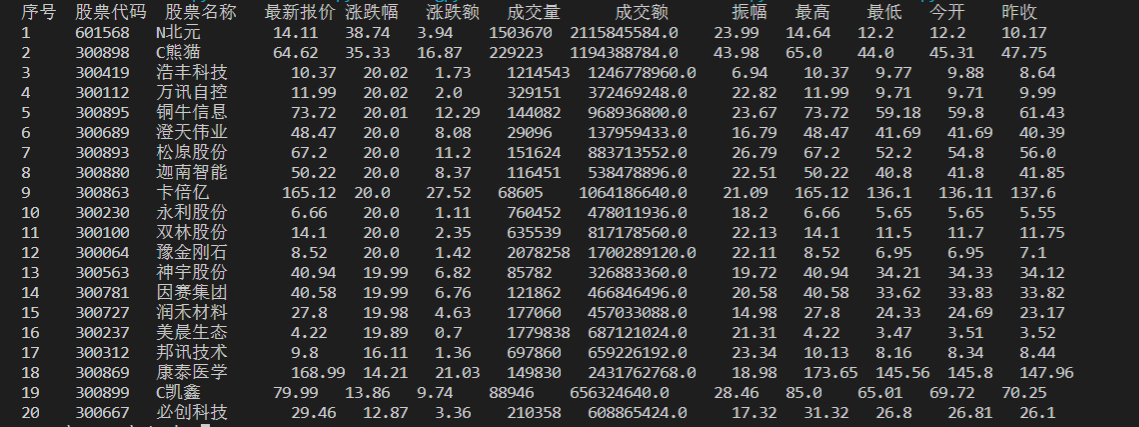
输出信息:
| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 成交额 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
| 1 | 688093 | N世华 | 28.47 | 62.22% | 10.92 | 26.13万 | 7.6亿 | 22.34 | 32.0 | 28.08 | 30.2 | 17.55 |
| 2 | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
1)代码
items.py
import scrapy
class StockItem(scrapy.Item):
# define the fields for your item here like:
rank = scrapy.Field()
number = scrapy.Field()
name = scrapy.Field()
price = scrapy.Field()
udRange = scrapy.Field()
udValue = scrapy.Field()
tradeNumber = scrapy.Field()
tradeValue = scrapy.Field()
Range = scrapy.Field()
mmax = scrapy.Field()
mmin = scrapy.Field()
today = scrapy.Field()
yesterday = scrapy.Field()
mySpider.py
import scrapy
import json,re
from stock.items import StockItem
class MySpider(scrapy.Spider):
name = "mySpider"
# 指定爬取页数,得到start_urls
page = 1
start_urls = ['http://10.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112403133057173384801_1603199819974&pn='+str(i+1)+
'&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23' for i in range(page)]
def parse(self,response):
try:
data = response.body.decode()
# print(data)
# 找到第一个[的位置,因为前面有一个{,会对匹配造成影响
text = data[data.index("["):]
# 匹配所有{},每支股票信息都包含在一个{}里
datas = re.findall("{.*?}", text)
for i in range(len(datas)):
# 将数据解析成字典
data = json.loads(datas[i])
item = StockItem()
item['rank'] = i+1
item['number'] = data['f12']
item['name'] = data['f14']
item['price'] = data['f2']
item['udRange'] = data['f3']
item['udValue'] = data['f4']
item['tradeNumber'] = data['f5']
item['tradeValue'] = data['f6']
item['Range'] = data['f7']
item['mmax'] = data['f15']
item['mmin'] = data['f16']
item['today'] = data['f17']
item['yesterday'] = data['f18']
yield item
except Exception as e:
print(e)
pipelines.py
from itemadapter import ItemAdapter
class StockPipeline:
count = 0
def process_item(self, item, spider):
# 控制输出表头信息
if StockPipeline.count == 0:
StockPipeline.count += 1
print("{:<3} {:<5} {:<6} {:<4} {:<5} {:<5} {:<8} {:<9} {:<4} {:<5} {:<4} {:<5} {:<5}".format(
"序号", "股票代码", "股票名称", "最新报价", "涨跌幅", "涨跌额", "成交量", "成交额", "振幅", "最高", "最低", "今开", "昨收"))
temp = "{:<5} {:<8} {:<10} {:<7} {:<7} {:<7} {:<8} {:<15} {:<7} {:<7} {:<7} {:<7} {:<6}"
print(temp.format(item['rank'], item['number'], item['name'], item['price'], item['udRange'], item['udValue'],
item['tradeNumber'], item['tradeValue'], item['Range'], item['mmax'], item['mmin'], item['today'], item['yesterday']))
return item
run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=False".split())
图片
2)心得体会
经过实验2熟悉scrapy框架后,感觉好多了,不过遇到一个问题,请求数据接口时response.body一直为空,后面经过舍友提醒,才知道得将ROBOTSTXT_OBEY参数修改为False。
