作业①:
要求:
- 用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
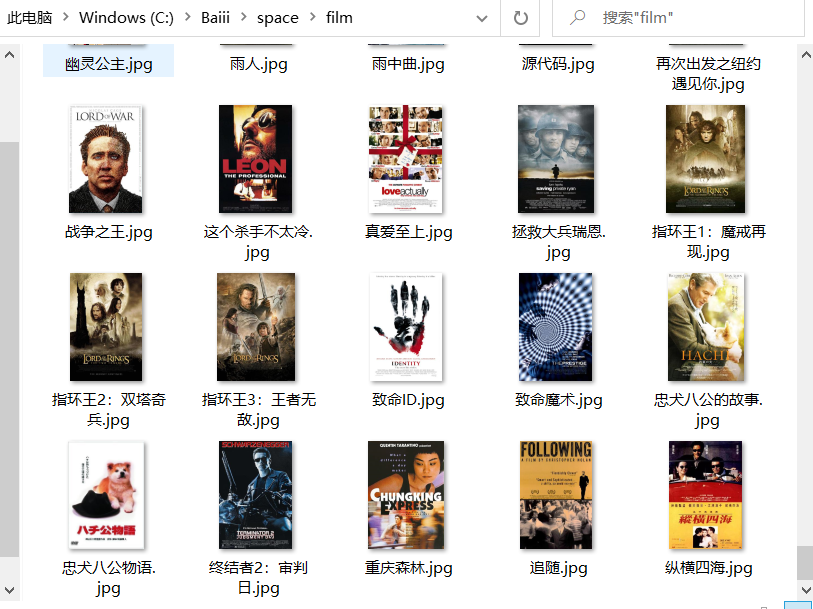
- 每部电影的图片,采用多线程的方法爬取,图片名字为电影名
- 了解正则的使用方法
输出信息:
| 排名 | 电影名称 | 导演 | 主演 | 上映时间 | 国家 | 电影类型 | 评分 | 评价人数 | 引用 | 文件路径 |
| 1 | 肖申克的救赎 | 弗兰克·德拉邦特 | 蒂姆·罗宾斯 | 1994 | 美国 | 犯罪 剧情 | 9.7 | 2192734 | 希望让人自由。 | 肖申克的救赎.jpg |
| 2 | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
1)代码:
import requests
from bs4 import BeautifulSoup
import threading
import os
def saveImg(url, path):
r = requests.get(url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36"
}
# 所要爬取的10页url
urls = ["https://movie.douban.com/top250?start="+str(i*25) for i in range(10)]
if not os.path.exists("../film"):
os.mkdir("../film")
print("排名 电影名称 导演 主演 上映时间 国家 电影类型 评分 评价人数 引用文件路径")
for url in urls:
r = requests.get(url, headers=headers)
r.encoding = "UTF-8"
soup = BeautifulSoup(r.text, "html.parser")
# 每一个电影信息都在一个div里,得到25个div
divs = soup.select("div[class='item']")
for div in divs:
rank = div.select("div[class='pic']")[0].text.strip()
name = div.select("span[class='title']")[0].text
# 导演,主演,上映时间,国家,类型的信息都在data里面,其它的可以直接得到
# 下面我打一个连五鞭
data = div.select("div[class='bd'] p")[0].text.strip()
""" data的信息类似于
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...
1994 / 美国 / 犯罪 剧情 """
# 导演取data的第一个空格的后一位,到第二个空格之间的数据
director = data[4:data.index(" ", 4)]
score = div.select("span[class='rating_num']")[0].text
# people得到的数据是20000人评价,过滤掉多余的信息
people = div.select("div[class='star'] span")[-1].text
people = people[:people.index('人')]
# quote不一定有,如果没有就令其等于无
try:
quote = div.select("span[class='inq']")[0].text
except:
quote = "无"
# 通过data[data.index("
"):].strip()得到第二行数据,有的电影有多个年份
# 国家和类型都是空格隔开,可以先得到它们,剩下的就都是年份信息了
kkk = [info.strip()
for info in data[data.index("
"):].strip().split("/")]
country = kkk[-2]
filmType = kkk[-1]
year = ""
for k in kkk[:-2]:
year += k
# 获取主演和导演一样的道理,不过主演不一定有,没有就令其等于无
index1 = data.find("主演")
mainRole = data[index1+4:data.index(" ", index1+4)].strip() if index1 >= 0 else "无"
# 获取电影图片,使用多线程下载
imgurl = div.find("img")["src"]
savePath = "../film/"+name+".jpg"
print(rank, "/", name, "/", director, "/", mainRole, "/", year, "/",
country, "/", filmType, "/", score, "/", people, "/", quote, "/", savePath)
T = threading.Thread(target=saveImg, args=(imgurl, savePath))
T.start()
2)图片

2.心得体会
复习了requests和bs4库的使用,以及多线程的使用,soup.find和soup.select方法已经快忘了,这也算是本门课的helloworld的了,可不能娶了媳妇忘了娘啊。还有就是数据不是很规则,有的电影没主演,有的没引用,怎么去处理这些问题也是很关键的
作业②:
要求:
- 熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
- 爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
输出信息:MYSQL的输出信息如下

1)代码:
创建表
CREATE TABLE college(
sNo VARCHAR(5),
schoolName VARCHAR(15),
city VARCHAR(5),
officalUrl VARCHAR(30),
info VARCHAR(300),
mFile VARCHAR(20)
)DEFAULT CHARACTER SET = utf8;
items.py
import scrapy
class CollegerankItem(scrapy.Item):
sNo = scrapy.Field()
schoolName = scrapy.Field()
city = scrapy.Field()
officalUrl = scrapy.Field()
info = scrapy.Field()
mFile = scrapy.Field()
mySpiders.py
import scrapy
import requests
from collegeRank.items import CollegerankItem
from bs4 import BeautifulSoup
class MySpider(scrapy.Spider):
name = "mySpider"
# 第一个是排行榜网站,第二个作为拼接url访问每所学校的信息
url = "https://www.shanghairanking.cn/rankings/bcur/2020"
website = "https://www.shanghairanking.cn"
def start_requests(self):
yield scrapy.Request(self.url,self.parse)
def parse(self,response):
data = response.body.decode()
selector = scrapy.Selector(text=data)
# 一学校对应一tr,第一个是多余的
trList = selector.xpath("//table[@class='rk-table']//tr")
for tr in trList[1:]:
rank = tr.xpath("./td[1]/text()").extract_first().strip()
name = tr.xpath("./td[2]/a/text()").extract_first().strip()
city = tr.xpath("./td[3]/text()").extract_first().strip()
href = tr.xpath("./td[2]/a/@href").extract_first().strip()
# 访问每所学校相应的页面
r = requests.get(self.website+href)
r.encoding = "UTF-8"
soup = BeautifulSoup(r.text,"html.parser")
officialUrl = soup.find("div",{"class":"univ-website"}).a.text
# 100名之后的学校都没有简介了
try:
info = soup.find("div",{"class":"univ-introduce"}).text
except:
info = ""
# logo的网址
logo = soup.find("td",{"class":"univ-logo"}).img["src"]
mFile = "../logo/"+str(rank)+".jpg"
self.saveImg(logo,mFile)
item = CollegerankItem()
item["sNo"] = rank
item["schoolName"] = name
item["city"] = city
item["officalUrl"] = officialUrl
item["info"] = info
item["mFile"] = mFile
print(rank)
yield item
def saveImg(self,url,path):
r = requests.get(url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
pipelines.py
from itemadapter import ItemAdapter
import pymysql
class CollegerankPipeline:
# 爬虫开始连接数据库
def open_spider(self, spider):
print("opened")
try:
self.db = pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="root",db="crawler",charset="utf8")
self.cursor = self.db.cursor()
self.opened = True
self.count = 0
except Exception as e:
print(e)
self.opened = False
# 爬虫结束提交事务,释放资源
def close_spider(self, spider):
if self.opened:
self.db.commit()
self.db.close()
self.opened = False
print("closed")
def process_item(self, item, spider):
try:
if self.opened:# 插入数据
self.cursor.execute("insert into college values (%s,%s,%s,%s,%s,%s)", (item["sNo"],item["schoolName"],item["city"],item["officalUrl"],item["info"],item["mFile"]))
except Exception as e:
print(e)
return item
2)图片:
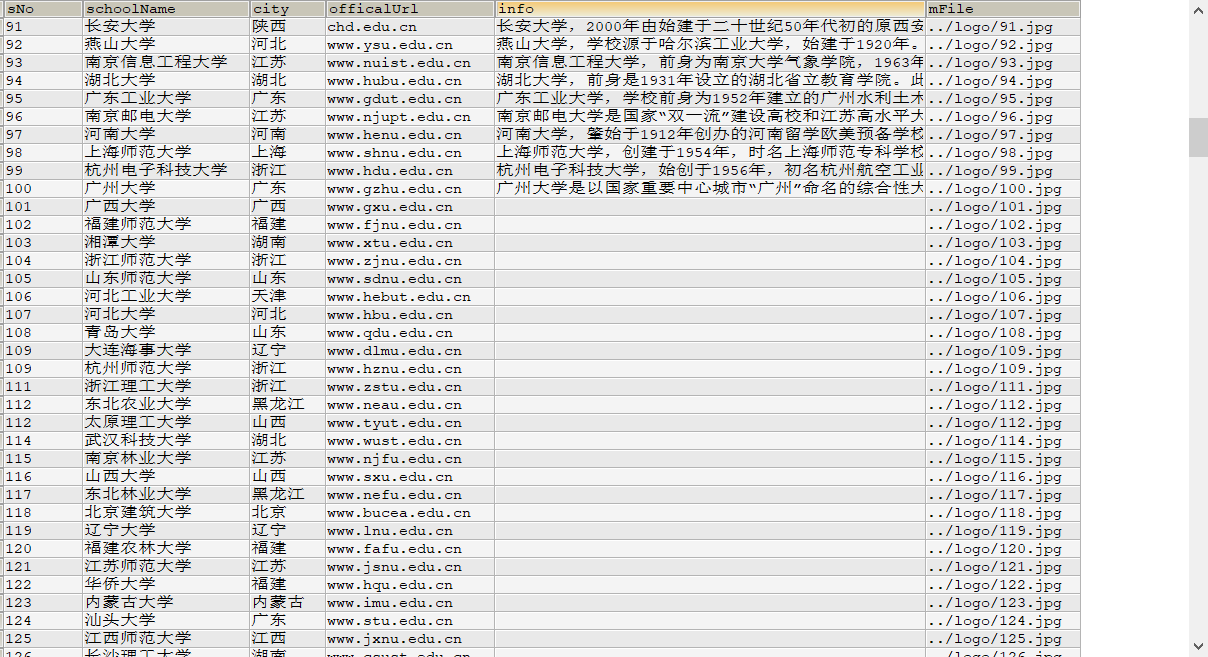
2.心得体会
重温scrapy框架的流程,温故而知新,可以为师矣,过程是挺顺利的,就是获取学校更详细的信息,需要访问其它url,我使用的是requests库,虽然获取单所学校的信息速度是挺快的,但总共有500多所学校,还是要等一会儿的,不知道有什么加速的方法吗
作业③:
要求:
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。
- 使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
- 其中模拟登录账号环节需要录制gif图。
输出信息:MYSQL数据库存储和输出格式如下
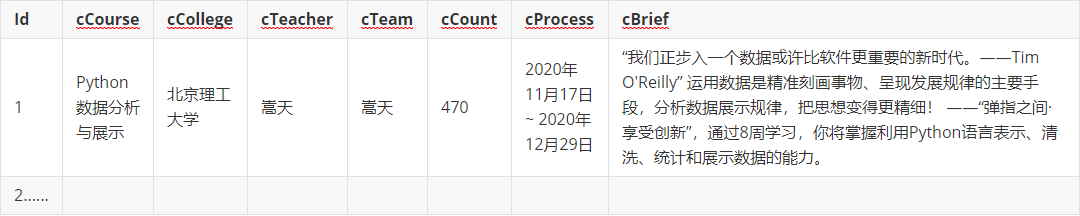
1)代码:
创建表
CREATE TABLE myCourse(
Id INT PRIMARY KEY,
cCourse VARCHAR(20),
cCollege VARCHAR(20),
cTeam VARCHAR(50),
cCount VARCHAR(10),
cProcess VARCHAR(30),
cBrief VARCHAR(200)
)DEFAULT CHARACTER SET = utf8;
main.py
from selenium import webdriver
from time import sleep
import pymysql,re
url = "https://www.icourse163.org"
driver = webdriver.Chrome()
driver.get(url)
sleep(1)
# 一步步 点击,输入,点击
driver.find_element_by_xpath("//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div").click()
sleep(1)
driver.find_element_by_xpath("//div[starts-with(@id,'auto-id')]/div/div/div/div[2]/span").click()
sleep(1)
driver.find_element_by_xpath("//div[starts-with(@id,'auto-id')]/div/div/div/div/div[1]/div/div[1]/div[1]/ul/li[2]").click()
sleep(1)
# 登录的frame和主frame不是同一个,得先切换
driver.switch_to.frame(driver.find_elements_by_tag_name("iframe")[1])
sleep(1)
driver.find_element_by_xpath("//input[@id='phoneipt']").send_keys("13395068352")
sleep(1)
driver.find_element_by_xpath("//input[@placeholder="请输入密码"]").send_keys("981110bl")
sleep(1)
driver.find_element_by_xpath("//a[@id="submitBtn"]").click()
sleep(3)
# 点击头像,进入个人中心
driver.find_element_by_xpath("//*[@id='my-img']").click()
sleep(2)
id = 0
# 连接数据库,获取游标对象
db = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='root', db='crawler', charset='utf8')
cursor = db.cursor()
# 获取已参加课程集合,只有3条,所以没翻页
divs=driver.find_elements_by_xpath('//div[@class="course-panel-body-wrapper"]/div')
for div in divs:
div.click()
sleep(1)
# 点击课程,进入学习课程的页面
driver.switch_to.window(driver.window_handles[-1])
sleep(1)
# 在此页面获取教师团队比较方便
team = driver.find_element_by_xpath('//*[@class="f-fc6 padding-top-5"]').text
sleep(1)
# 点击教师团队上方的课程名,进入熟悉的页面
driver.find_element_by_xpath('//h4[@class="f-fc3 courseTxt"]').click()
sleep(1)
# 切换到最新页面
driver.switch_to.window(driver.window_handles[-1])
sleep(1)
id += 1
# 获取相应的信息
course = driver.find_element_by_xpath('//span[@class="course-title f-ib f-vam"]').text
process = driver.find_element_by_xpath('//div[@class="course-enroll-info_course-info_term-info_term-time"]/span[2]').text
college = driver.find_element_by_xpath('//*[@id="j-teacher"]/div/a/img').get_attribute("alt")
# 一开始的count是 已有 21301 人参加 这样的,使用正则表达式提取数字
count = driver.find_element_by_xpath('//span[@class="course-enroll-info_course-enroll_price-enroll_enroll-count"]').text
count = re.search("d+",count).group(0)
brief = driver.find_element_by_xpath('//*[@id="j-rectxt2"]').text
print(id,course, college, team, process, brief)
cursor.execute('insert into myCourse values("%s","%s","%s","%s","%s","%s","%s")' %
(id, course, college, team, count, process, brief))
db.commit()
sleep(1)
# 关闭新打开的两个页面
driver.close()
driver.switch_to.window(driver.window_handles[-1])
sleep(1)
driver.close()
sleep(1)
driver.switch_to.window(driver.window_handles[0])
driver.quit()
cursor.close()
db.close()
2)图片:
模拟登录


2.心得体会
本实验和上次作业很像,稍微改一改就可以了。实验2,3,以及之前的实验,说明了爬虫的技术不是独立的,是可以混合使用的,之前的scrapy和selenium,本次scrapy和requests,selenium和re,所以得学会融会贯通。还有就是自己写的程序不喜欢添加异常处理,除非忍不住,希望能够改正