本人很喜欢高达,于是乎在网上找了高达的图片
这个网站不让右键保存图片,只能一张一张点开然后点下载
于是开始爬:
首先滤清思路
'''
1: 分析:图片发现图片在
https://up.enterdesk.com/edpic_source/87/9f/d0/879fd07ff61db705c7351a5e4feaa672.jpg
https://up.enterdesk.com/edpic_source/78/c5/64/78c564e2856a6c4b5d0b1823350918e7.jpg
https://up.enterdesk.com/edpic_source/3a/28/07/3a2807b5cf0de9f3ee0c33360965f477.jpg
所有的图片都在https://up.enterdesk.com/edpic_source/xxxxxxxx中.jpg
2: 分析网页:获取图片的url # 就他喵的10个图片
3: 将获取的url 放在列表中,循环列表,获取相应给0.5秒反应时间,.获取图片存入在文件夹
'''
1:
通过观察
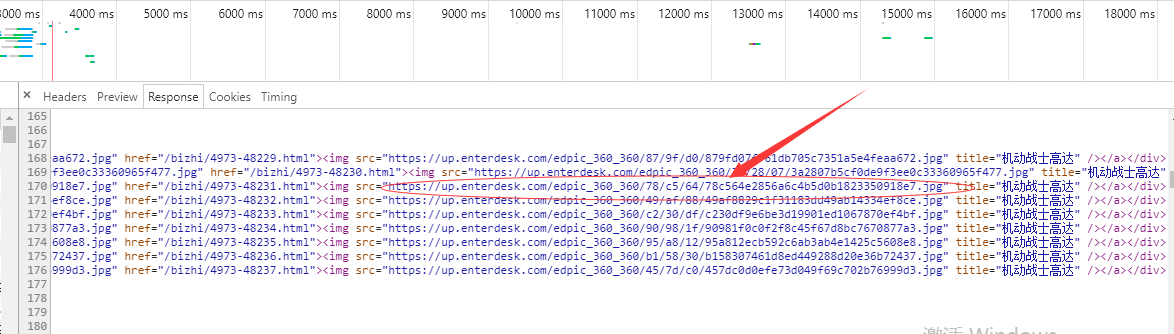
可以得知图片的url 的位置
先获取响应:
利用re模块获取
def get_urls(self,staus_url): #获取url地址,参数提供基本网页参数 res =requests.get(staus_url,headers =self.header) # 获取相应 piace_url =res.text panent =re.compile('<img src="(.*?)" title="机动战士高达" /></a></div>',re.S) text =re.findall(panent,piace_url) self.get_url_list.append(text) l=self.clean_text(self.get_url_list) self.get_url_list =l return self.get_url_list
2:
下载每个图片
def get_piace(self,num,url): res = requests.get(url,headers =self.header) connect =res.content with open('f:/piace/'+str(num)+'.jpg','wb') as f: f.write(connect) print('高达图片'+str(num)+'写入成功')
3:
得知有高清图片后,分析网页找到规律,清晰图片
def clean_text(self,list): new_list =[] for url in list[0]: url =url.replace('edpic_360_360','edpic_source') new_list.append(url) return new_list
4:
保存图片
整体代码
# -*- coding: utf-8 -*- # @Time : 2018/12/31 16:29 # @Author : Endless-cloud # @Site : # @File : 爬取高达图片.py # @Software: PyCharm import requests import re from bs4 import BeautifulSoup import time import os import _md5 ''' 1: 分析:图片发现图片在 https://up.enterdesk.com/edpic_source/87/9f/d0/879fd07ff61db705c7351a5e4feaa672.jpg https://up.enterdesk.com/edpic_source/78/c5/64/78c564e2856a6c4b5d0b1823350918e7.jpg https://up.enterdesk.com/edpic_source/3a/28/07/3a2807b5cf0de9f3ee0c33360965f477.jpg 所有的图片都在https://up.enterdesk.com/edpic_source/xxxxxxxx中.jpg 2: 分析网页:获取图片的url # 就他喵的10个图片 3: 将获取的url 放在列表中,循环列表,获取相应给0.5秒反应时间,.获取图片存入在文件夹 文件名字以md5加密输出 ''' class gaoda_speader(object): def __init__(self): #基本信息 self.get_url_list =[] # 存放获取到的url地址 self.header ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' } self.num = len(self.get_url_list) #存放获取到的图片总数.以便于起名字 def get_urls(self,staus_url): #获取url地址,参数提供基本网页参数 res =requests.get(staus_url,headers =self.header) # 获取相应 piace_url =res.text panent =re.compile('<img src="(.*?)" title="机动战士高达" /></a></div>',re.S) text =re.findall(panent,piace_url) self.get_url_list.append(text) l=self.clean_text(self.get_url_list) self.get_url_list =l return self.get_url_list def clean_text(self,list): new_list =[] for url in list[0]: url =url.replace('edpic_360_360','edpic_source') new_list.append(url) return new_list def get_piace(self,num,url): res = requests.get(url,headers =self.header) connect =res.content with open('f:/piace/'+str(num)+'.jpg','wb') as f: f.write(connect) print('高达图片'+str(num)+'写入成功') def go_run(self): staus ='https://www.enterdesk.com/bizhi/4973-48230.html' self.get_urls(staus) # print(self.get_url_list) for i in self.get_url_list: self.get_piace(self.num,i) self.num+=1 if __name__ == '__main__': gaoda_speader=gaoda_speader() gaoda_speader.go_run() print('保存成功')
图片很大,最好用线程下载,等线程用的比较清晰后,在出线程版本(...大概用过几次,..感觉不难.不过最好
jia上time模块,和ip代理,这样可以 避免被封)