什么是词嵌入?为什么我们使用单词嵌入?在进入细节之前。让我们看一些例子:
- 有许多网站要求我们在使用它们时对这些产品发表评论或反馈。像:-亚马逊,IMDB。
- 我们还可以使用几个单词在google上搜索并获取与之相关的结果。
- 有一些站点在博客上放置与博客中的材料相关的标签。
那么他们如何做到这一点。这些东西实际上是文本处理的应用。我们使用文本进行情感分析,将相似的单词聚类,对文档进行分类和标记。
当我们阅读任何报纸时,我们都可以说这是什么新闻,但是计算机将如何处理这些事情?计算机可以匹配字符串,并且可以告诉我们它们是否相同。但是,当您搜索梅西时,我们如何使计算机告诉您有关足球或罗纳尔多的信息?
对于对象或语音识别之类的任务,我们知道成功完成任务所需的所有信息都已编码在数据中(因为人类可以从原始数据中执行这些任务)。但是,自然语言处理系统通常会将单词视为离散的原子符号,因此“猫”可以表示为Id537,“狗” 可以表示为Id143。这些编码是任意的,并且不向系统提供有关各个符号之间可能存在的关系的有用信息。
这里是词嵌入。词嵌入只是文本的数字表示。
有很多不同类型的单词嵌入:
- 基于频率的嵌入
- 基于预测的嵌入
基于频率的嵌入:
计数向量:
计数向量模型从所有文档中学习词汇,然后通过计算每个单词出现的次数来对每个文档进行建模。例如,假设我们有D个文档,T是词汇量中不同单词的数量,那么计数向量矩阵的大小将由D * T给出。让我们用以下两个句子:
文件1:“The cat sat on the hat”
文件2:“The dog ate the cat and the hat”
从这两个文档中,我们的词汇如下:
{the, cat, sat, on, hat, dog, ate, andt}
所以D = 2,T = 8
现在,我们计算每个文档中每个单词出现的次数。在文档1中,“ the”出现两次,而“ cat”,“ sat”,“ on”和“ hat”分别出现一次,因此文档的特征向量为:
{the, cat, sat, on, hat, dog, ate, and }
所以计数向量矩阵是:

现在,一列也可以理解为矩阵M中相应单词的单词向量。例如,上述矩阵中'cat'的单词向量为[1,1],依此类推。这里,各行对应于语料库中的文档和列对应于词典中的标记。上面的矩阵中的第二行可以读为-文档2包含“帽子”:一次,“狗”:一次,“三次”,依此类推。
对于大型文本语料库,存在与矩阵尺寸有关的问题,因此我们可以使用停用词(删除常用词,例如“ a,an,this,that”),也可以根据频率和频率从词汇表中提取一些重要词用作新词汇,或者我们可以同时使用这两种方法。
TF-IDF向量化:
在大型文本语料库中,某些单词会非常出现(例如英语中的“ the”,“ a”,“ is”),因此几乎没有关于文档实际内容的有意义的信息。如果我们将直接计数数据直接提供给分类器,那么那些非常频繁的术语会掩盖稀有但更有趣的术语的出现频率。
为了将计数特征重新加权为适合分类器使用的浮点值,通常使用tf–idf变换。此方法不仅考虑单个文档中单词的出现,还考虑整个语料库中的单词。让我们以商业文章为准,与其他任何文章相比,本文将包含更多与商业相关的术语,例如股票市场,价格,股票等。但是每篇文章中都会频繁出现“一个”一词。因此,此方法将惩罚这些类型的高频单词。
Tf表示术语频率,而tf–idf表示术语频率乘以文档频率的倒数。
TF =(术语t在文档中出现的次数)/(文档中术语的次数)
IDF = log(N / n),其中,N是文档总数,n是出现术语t的文档数。
TF-IDF(t,文档)= TF(t,文档)* IDF(t)
具有固定上下文窗口的共现矩阵
单词共现矩阵描述单词如何一起出现,进而捕获单词之间的关系。单词共现矩阵的计算仅是通过计算给定语料库中两个或多个单词如何一起出现。作为单词共现的示例,请考虑由以下文档组成的语料库:
一分钱明智和英镑愚蠢
节省的一分钱就是赚到的一分钱
让count(w(next)| w(current))表示单词w(next)跟在单词w(current)之后多少次,我们可以将单词“ a”和“ penny”的共现统计总结为:

上表显示,在我们的语料库中,“ a”后面跟着“ penny”两次,而“赚取”,“保存”和“ wise”一词在“ penny”后面一次。因此,“赚取”是出现在“便士”之后的三分之一。上面所示的计数称为二元频率 ; 它只会查看当前单词中的下一个单词。给定一个N个单词的语料库,我们需要一个NxN大小的表来表示所有可能的单词对的双字组频率。由于大多数频率等于零,因此该表非常稀疏。实际上,共现计数被转换为概率。这导致每个行的行条目在共现矩阵中总计为一。
但是,请记住,这个共现矩阵不是通常使用的单词矢量表示。取而代之的是,使用PCA,SVD等技术将该同现矩阵分解为因子,这些因子的组合形成词向量表示。
让我更清楚地说明这一点。例如,您对上述大小为NXN的矩阵执行PCA。您将获得V主成分。您可以从这些V分量中选择k个分量。因此,新矩阵将为NX k的形式。
并且,单个单词而不是以N维表示,而是以k维表示,同时仍然捕获几乎相同的语义。k通常约为数百。
因此,PCA在后面所做的就是将共现矩阵分解为三个矩阵U,S和V,其中U和V都是正交矩阵。重要的是,U和S的点积表示单词矢量表示,而V表示单词上下文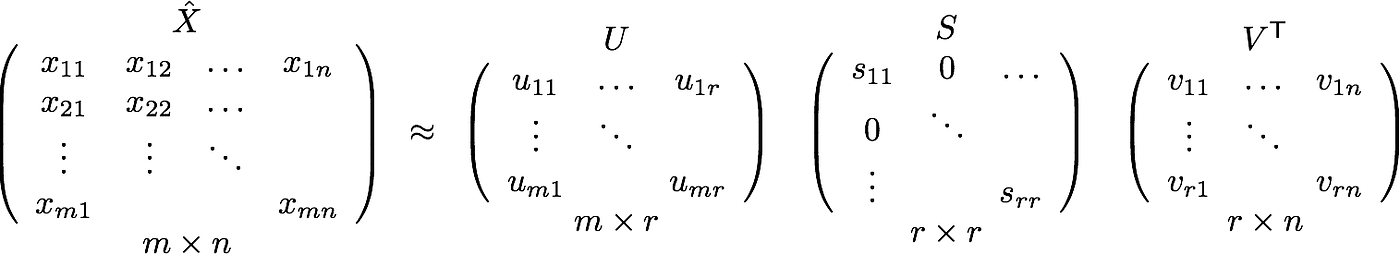
同现矩阵的优点
- 它保留了单词之间的语义关系。即男人和女人往往比男人和苹果更接近。
- 它以SVD为核心,比现有方法产生更准确的单词向量表示。
- 它使用因式分解,这是一个明确定义的问题,可以有效解决。
- 它必须计算一次,并且可以在计算后随时使用。从这个意义上讲,它比其他方法更快。
共现矩阵的缺点
- 需要大量内存来存储共现矩阵。
但是,可以通过将矩阵分解到系统外(例如在Hadoop集群等中)来解决此问题,并可以将其保存下来。
基于频率的方法的应用:
基于频率的方法易于理解,并且具有许多应用,例如文本分类,情感分析等等。因为它们从文本中提取了肯定和否定的单词,所以我们可以借助任何好的机器学习算法轻松地对它们进行分类。
基于预测的方法:
连续词袋(CBOW):
CBOW正在学习根据上下文预测单词。对于给定的目标单词,上下文可以是单个单词或多个单词。
让我们以“猫跳过水坑”为例进行说明。
因此,一种方法是将{“ The”,“ cat”,“ over”,“ the”,“ puddle”}视为上下文,并从这些单词中预测或生成中心单词“ jumped”。我们将这种类型的模型称为连续词袋(CBOW)模型。
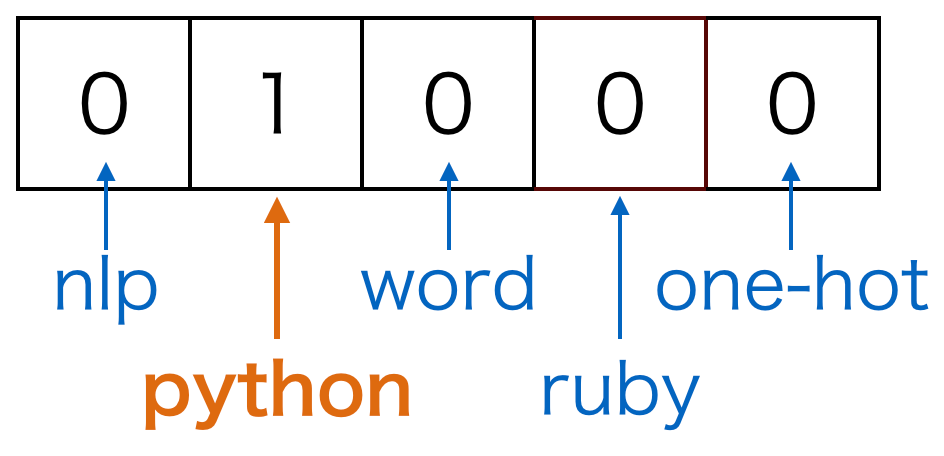
在开始使用CBOW进行详细介绍之前,让我们先谈谈单词的一种热表示形式:一种将单词表示为矢量的方法是一种热表示形式。一热表示是一种表示方法,其中向量中只有一个元素为1,其他元素为0。通过为每个维度设置1或0,它表示“该单词或不单词”。
比方说,例如,我们将“ python”一词表示为一键表示。在此,作为一组单词的词汇是五个单词(nlp,python,word,ruby,one-hot)。然后,以下向量表示单词“ python”:
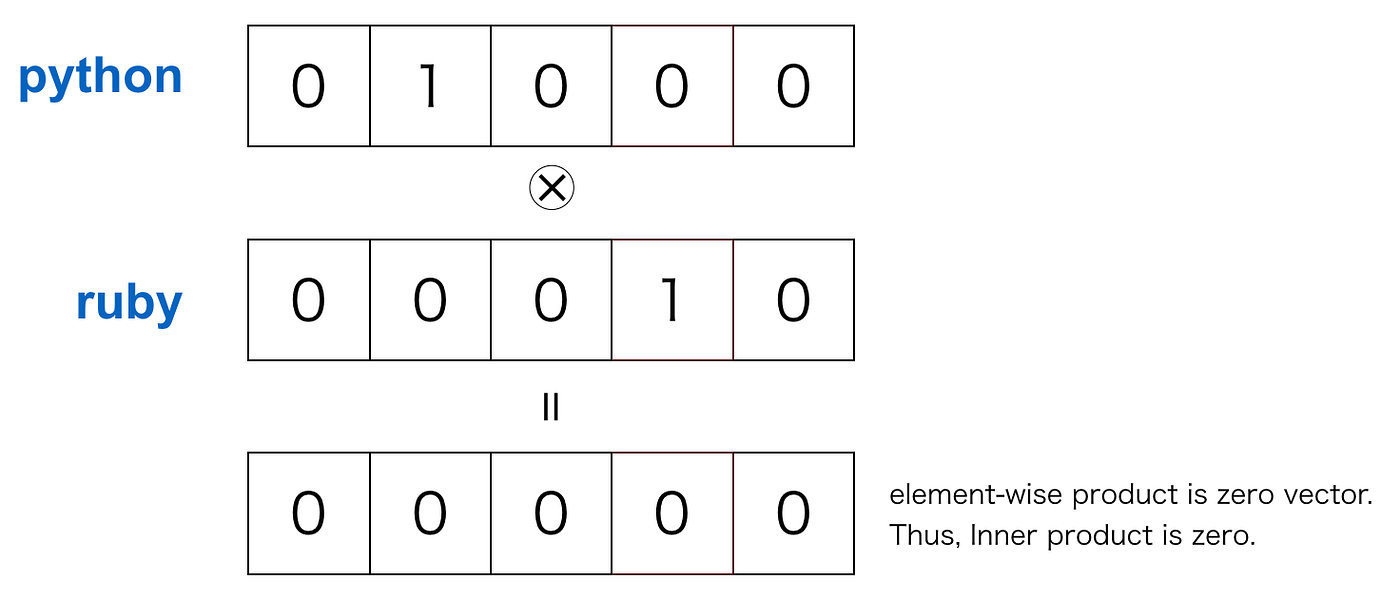
尽管一键式表示很简单,但是也有不足之处:用向量之间的算术不可能获得有意义的结果。假设我们采用一个内积来计算单词之间的相似度。在一次热表示中,不同词在不同位置为1,其他元素为0。因此,在不同词之间取点积的结果为0。这不是有用的结果。
另一个弱点是向量往往会变得非常高维。由于将一个维度分配给一个单词,因此随着词汇量的增加,它成为非常高的维度。
我们按以下步骤细分该模型的工作方式:
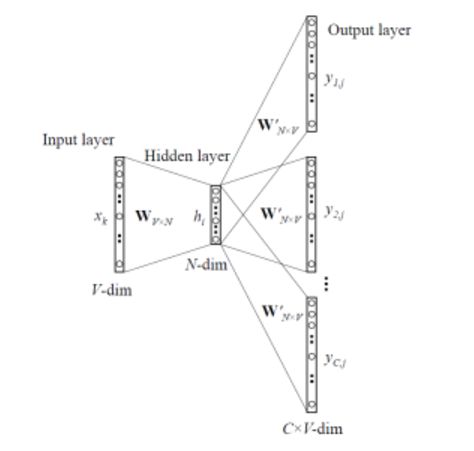
Wi =输入层和隐藏层之间的权重矩阵,大小为[V * N]
Wj =隐藏层和大小为[N * V]的输出层之间的权重矩阵
- 对于大小的输入上下文,我们生成一个热词向量(x(c-m),...,x(c-1),x(c + 1),...,x(c + m))米 其中x(c)是我们要预测的中心词或目标词。我们有一个大小为[1 * V]的C(= 2m)个热词向量。所以我们的输入层大小是[C * V]
- 然后,我们将它们与矩阵Wi相乘,得到大小为[1 * N]的嵌入词。
- 现在我们取这2m [1 * N]个向量的平均值。
- 现在我们通过将隐藏层输入乘以矩阵Wj来计算隐藏层输出。现在我们得到一个大小为[1 * V]的得分向量。让我们将其命名为z。
- 用yˆ = softmax(z)将分数变成概率
- 我们希望生成的概率yˆ与真实概率y相匹配,真实概率y恰好也是实际单词的一个热门向量。
- 计算输出和目标之间的误差,并传播回去以重新调整权重。
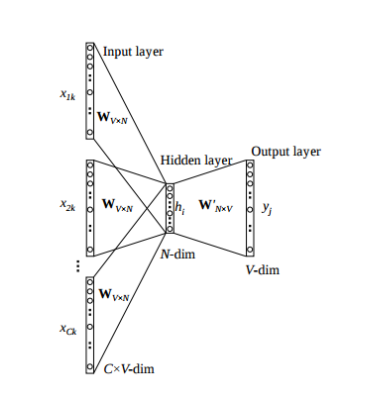
CBOW架构
使用的损失函数是交叉熵。
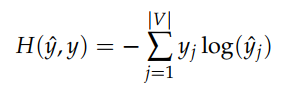
交叉熵公式
然后我们使用梯度下降法或任何优质的优化程序来训练该网络。训练后,隐藏层和输出层之间的权重(Wj)被用作单词的单词向量表示。其中每列代表大小为[1 * N]的字向量。
跳过图模型:
另一种方法是创建一个模型,以使给定中心单词“跳跃”,该模型将能够预测或生成周围的单词“ The”,“ cat”,“ over”,“ the”,“ puddle”。在这里,我们将“跳转”一词称为上下文。我们称这类模型为SkipGram模型。
跳过语法模型可逆转目标词和上下文词的使用。跳过gram提取一个单词并从中预测上下文单词。
跳过图模型
我们按以下步骤细分该模型的工作方式:
Wi =输入层和隐藏层之间的权重矩阵,大小为[V * N]
Wj =隐藏层和大小为[N * V]的输出层之间的权重矩阵
- 我们为输入中心词生成一个热词向量x(c)。其中(x(cm),...,x(c-1),x(c + 1),...,x(c + m))是我们要预测的上下文词。因此我们的输入层大小为[1 * V]
- 然后,我们将它们与矩阵Wi相乘,得到大小为[1 * N]的嵌入词。
- 现在我们通过将隐藏层输入乘以矩阵Wj来计算隐藏层输出。现在我们得到大小为[1 * V]的C(= 2m)分数矢量。让我们将其命名为z(i)。
- 通过yˆ(i)= softmax(z(i))将分数转化为概率
- 我们希望生成的概率yˆ(i)与真实概率y(i)相匹配,这也恰好是实际单词的一个热门向量。
- 计算输出和目标之间的误差,并传播回去以重新调整权重。
可以问所有yˆ都一样,那么它们将如何提供帮助?
是的,yˆ都相同,但是它们的目标向量不同,因此它们都给出了不同的误差向量,并且对所有误差向量进行逐个元素求和以获得最终误差向量。之后,我们使用反向传播算法和梯度下降来学习模型。
CBOW和跳过图的优缺点:
- 概率是自然的,这些方法(通常)应该比确定性方法表现更好。
- 这些内存不足。它们不需要像共存矩阵那样需要巨大的RAM需求,而在共存矩阵中它需要存储三个巨大的矩阵。
- 尽管CBOW(根据上下文预测目标)和skip-gram(根据目标预测上下文词)只是彼此颠倒的方法,但它们各有优缺点。由于CBOW可以使用许多上下文单词来预测1个目标单词,因此它实际上可以平滑分布。这本质上类似于正则化,并且当我们的输入数据不太大时可以提供非常好的性能。但是,skip-gram模型的粒度更细,因此当我们拥有大量数据集时(大数据始终是最佳的正则化方法),我们能够提取更多信息,并且本质上具有更准确的嵌入。带有负子采样的跳过图通常胜过其他所有方法。
词嵌入的应用(Word2Vec):
在基于NLP的各种任务中,深度学习中使用的这些词嵌入已超过了较早的基于ML的模型。在各种NLP应用中,它们被广泛使用。例如。自动摘要,机器翻译,命名实体解析,情感分析,聊天机器人,信息检索,语音识别,问题解答等。
我们可以使用例如t-SNE降维技术将学习的矢量投影到2维,从而可视化学习的矢量。当我们检查这些可视化效果时,很明显,这些向量捕获了一些有关单词及其彼此之间关系的通用且实际上非常有用的语义信息。有趣的是,当我们首先发现诱导向量空间中的某些方向专门针对某些语义关系时,例如单词之间的男女关系,动词时态以及甚至国家-首都关系,如下图所示。

这就解释了为什么这些向量还可以用作许多规范的NLP预测任务的特征,例如词性标记或命名实体识别。

Word2Vec的t-SNE
我们可以看到所有相似的词都在一起。我们可以从Word2Vec的单词嵌入中执行一些惊人的任务。
- 查找两个词之间的相似度。
model.similarity('woman','man')0.73723527 - 寻找一个奇怪的。
model.doesnt_match('breakfast cereal dinner lunch';.split())'cereal' - 女人+国王男人=女王之类的惊人事物
model.most_similar(positive=['woman','king'],negative=['man'],topn=1)queen: 0.508 - 模型下文本的概率
model.score(['The fox jumped over the lazy dog'.split()])0.21

单词嵌入是一个活跃的研究领域,试图找出比现有单词更好的单词表示。但是,随着时间的流逝,它们的数量越来越大,越来越复杂。本文旨在简化这些嵌入模型的某些工作,而又不承担数学上的开销。