一 PV 推到出 QPS
你想建设一个能承受500万PV/每天的网站吗? 500万PV是什么概念?服务器每秒要处理多少个请求才能应对?如果计算呢??
PV是什么:PV是page view的简写。PV是指页面的访问次数,每打开或刷新一次页面,就算做一个pv。
计算模型:
每台服务器每秒处理请求的数量=((80%*总PV量)/(24小时*60分*60秒*40%)) / 服务器数量 。
其中关键的参数是80%、40%。表示一天中有80%的请求发生在一天的40%的时间内。24小时的40%是9.6小时,有80%的请求发生一天的9.6个小时当中(很适合互联网的应用,白天请求多,晚上请求少)。
简单计算的结果:
((80%*500万)/(24小时*60分*60秒*40%))/1 = 115.7个请求/秒
((80%*100万)/(24小时*60分*60秒*40%))/1 = 23.1个请求/秒
(2)初步结论:
现在我们在做压力测试时,就有了标准,如果你的服务器一秒能处理115.7个请求,就可以承受500万PV/每天。如果你的服务器一秒能处理23.1个请求,就可以承受100万PV/每天。
留足余量:
以上请求数量是均匀的分布在白天的9.6个小时中,但实际情况并不会这么均匀的分布,会有高峰有低谷。为了应对高峰时段,应该留一些余地,最少也要x2倍,x3倍也不为过。
115.7个请求/秒?*2倍=231.4个请求/秒
115.7个请求/秒?*3倍=347.1个请求/秒
23.1个请求/秒?*2倍=46.2个请求/秒
23.1个请求/秒?*3倍=69.3个请求/秒
(3)最终结论:
如果你的服务器一秒能处理231.4--347.1个请求/秒,就可以应对平均500万PV/每天。
如果你的服务器一秒能处理46.2--69.3个请求,就可以应对平均100万PV/每天。
这里所谓的每秒N个请求,就是QPS。
(4)实际经验:
1、根据实际经验,采用两台常规配置的机架式服务器,配置是很常见的配置,例如一个4核CPU+4G内存+服务器SAS硬盘。
2、个人武断的认为在服务器CPU领域Intel的CPU要优于AMD的CPU,有反对的就反对吧,我都说我武断了(请看CPU性能比较),不要太相信AMD的广告,比较CPU性能简单办法就是比价格,不要比频率与核心数,价格相差不多的性能也相差不多。
3、硬盘的性能很重要,尤其是数据库服务器。一般的服务器都配1.5万转的SAS硬盘,高级一点的可以配SSD固态硬盘,性能会更好。最最最最重要的指标是“随机读写性能”而不是“顺序读写性能”。(本例还是配置最常见的1.5万转的SAS硬盘吧)
4、一台服务器跑Tomcat运行j2ee程序,一台服务器跑MySql数据库,程序写的中等水平(这个真的不好量化),是论坛类型的应用(总有回帖,不太容易做缓存,也无法静态化)。
5、以上软硬件情况下,是可以承受100万PV/每天的。(已留有余量应对突然的访问高峰)
注意机房的网络带宽:
有人说以上条件我都满足了,但实际性能还是达不到目标。这时请注意你对外的网络的带宽,在国内服务器便宜但带宽很贵,很可能你在机房是与大家共享一条100M的光纤,实际每个人可分到2M左右带宽。再好一点5M,再好一点双线机房10M独享,这已经很贵了(北京价格)。
一天总流量:每个页面20k字节*100万个页面/1024=19531M字节=19G字节,
19531M/9.6小时=2034M/小时=578K字节/s。如果请求是均匀分布的,需要5M(640K字节)带宽(5Mb=640KB
注意大小写,b是位,B是字节,差了8倍),但所有请求不可能是均匀分布的,当有高峰时5M带宽一定不够,X2倍就是10M带宽。10M带宽基本可以满足要求。以上是假设每个页面20k字节,基本不包含图片,要是包含图片就更大了,10M带宽也不能满足要求了
Throughput(吞吐量):按照常规理解网络吞吐量表示在单位时间内通过网卡数据量之和,其中即包括本机网卡发送出去的数据量也包括本机网卡接收到的数据量。 一个100Mb(位)的双工网卡,最大发送数据的速度是12.5M字节/s, 最大接收数据的速度是12.5M字节/s, 可以同时收发数据。
并发用户数 是同时执行操作的用户(线程数)
响应时间 从请求发出到收到响应花费的时间
QPS(Queries Per Second) 每秒处理的查询数(如果是数据库,就相当于读取)
TPS(Transactions Per Second) 每秒处理的事务数(如果是数据库,就相当于写入、修改)
IOPS 每秒磁盘进行的I/O操作次数
二 ip地址分类和网络区分
IP地址分类/IP地址10开头和172开头和192开头的区别/判断是否同一网段
简单来说在公司或企业内部看到的就基本都是内网IP,ABC三类IP地址里的常见IP段。
每个IP地址都包含两部分,即网络号和主机号。
InterNIC将IP地址分为五类:
A类保留给ZF或大型企业,
B类分配给中等规模的公司,
C类分配给小公司或个人,
D类用于组播,
E类用于实验,
注:各类可容纳的地址数目不同。
A、B、C三类IP地址的特征:当将IP地址写成二进制形式时,
A类地址的第一位总是O,如,10.0.0.1==00001010-00000000-00000000-00000001
==》1.0.0.0-127.255.255.255,默认子网掩码为255.0.0.0,最多可容纳16777215台计算机
B类地址的前两位总是10,如,172.16.0.1==10101100-00010000-00000000-00000001
==》128.0.0.0-191.255.255.255,默认子网掩码为255.255.0.0,最多可容纳65535台计算机
C类地址的前三位总是110。如,192.168.0.1==11000000-10101000-00000000-00000001
==》192.0.0.0-223.255.255.255,默认子网掩码是255.255.255.0,最多可容纳254台计算机
IP地址中保留地址:主机部分全为0的IP地址保留用于网络地址,主机部分全为1的IP地址保留为广播地址,224--255部分保留作为组播和实 验目的。 同时注意IP地址分配时不能使用最末位为0和255的地址,因为这是广播地址,普通计算机上不能使用,但可用于网关和路由器上。
专用IP地址: 就是我们在3类地址中常见到内网的IP段。
10.0.0.0--10.255.255.255
172.16.0.0--172.31.255.255
192.168.0.0--192.168.255.255
内网的计算机以NAT(网络地址转换)协议,通过一个公共的网关访问Internet。内网的计算机可向Internet上的其他计算机发送连接请求,但Internet上其他的计算机无法向内网的计算机发送连接请求。
主机地址种类
概述
通过IP地址的引导位(最高位)来区分不同类别的IP地址:
注:n为网络编号位,h为主机编号位
A类地址
A类地址:0nnnnnnn.hhhhhhhh.hhhhhhhh.hhhhhhhh
A类地址具有7位网络编号,因此可定义126个A类网络{2^7-2(网络编号不能是全0或全1 注1)-1(127为环回地址 注2)}每个网络可以拥有的主机数为16777214{2^24-2(主机位不能是全0或全1)}
十进制表示范围:1.0.0.1-126.255.255.254,任何一个0到127间的网络地址均是一个A类地址。
B类地址
B类地址:10nnnnnn.nnnnnnnn.hhhhhhhh.hhhhhhhh
B类地址具有14位网络编号,因此可定义16382个B类网络{2^14-2}
每个网络可以拥有的主机数为65534{2^16-2}
十进制表示范围:129.0.0.1-191.255.255.254,任何一个128到191间的网络地址是一个B类地址。
C类地址
C类地址:110nnnnn.nnnnnnnn.nnnnnnnn.hhhhhhhh
C类地址具有21位网络编号,因此可定义2097152个C类地址{2^21-2}
每个网络可以拥有的主机数为254{2^8-2}
十进制表示范围:192.0.0.1-223.255.255.254,任何一个192到223间的网络地址是一个C类地址。
D类地址
D类地址:1110xxxx.xxxxxxxx.xxxxxxxx.xxxxxxxx
D类地址用于组播,前面4位1110引导,后面28位为组播地址ID。
十进制表示范围:224.0.0.0-239.255.255.255
E类地址
E类地址:总是以1111四位引导
E类地址用于研究用
十进制表示范围:240-
IP地址由InterNIC(因特网信息中心)统一分配,以保证IP地址的唯一性,但有一类IP地址是不用申请可直接用于企业内部网的,这就是 Private Address,Private Address不会被INTERNET上的任何路由器转发,欲接入INTERNET必须要通过NAT/PAT转换,以公有IP的形式接入。
这些私为地址为:
10.0.0.0-10.255.255.255(一个A类地址)
172.16.0.0-172.31.255.255(16个B类地址)
192.168.0.0-192.168.255.255(256个C类地址)
任何一个第一个八位组在224到239间的网络地址是一个组播地址
任何一个专用I P网络均可以使用包括:
1个A类地址( 10.0.0.0 )、
16个B类地址(从172.16.0.0到172.31.0.0 )
256个C类地址(从192.168.0.0到192.168.255.0 )
三 观察者模式对于消息的推和拉的处理
观察者模式,指的是定义一种对象间的一对多的关系,当一个对象的状态发生变化的时候,所有依赖于它的对象都将得到通知并更新自己。
“推”的方式是指,Subject维护一份观察者的列表,每当有更新发生,Subject会把更新消息主动推送到各个Observer去。
“拉”的方式是指,各个Observer维护各自所关心的Subject列表,自行决定在合适的时间去Subject获取相应的更新数据。
“推”的好处包括:
1、高效。如果没有更新发生,不会有任何更新消息推送的动作,即每次消息推送都发生在确确实实的更新事件之后,都是有意义的。
2、实时。事件发生后的第一时间即可触发通知操作。
3、可以由Subject确立通知的时间,可以避开一些繁忙时间。
4、可以表达出不同事件发生的先后顺序。
“拉”的好处包括:
1、如果观察者众多,Subject来维护订阅者的列表,可能困难,或者臃肿,把订阅关系解脱到Observer去完成。
2、Observer可以不理会它不关心的变更事件,只需要去获取自己感兴趣的事件即可。
3、Observer可以自行决定获取更新事件的时间。
4、拉的形式可以让Subject更好地控制各个Observer每次查询更新的访问权限。
----------------------------------------------------------------------------------------------------------------------------------
补充:
事实上“推”和“拉”可以比较的内容太多了,比如:
客户端通常是不稳定的,服务端是稳定的,如果消息由客户端主动发起去获取,它很容易找到服务端的地址,可以比较容易地做到权限控制(集中在服务端一处),服务端也可以比较容易地跟踪客户端的位置和状态,反之则不行;
互联网页面的访问就是一个最好的“拉”的模式的例子;
通常我们希望把压力分散到各个客户端上去,服务端只做最核心的事情,只提供内容,不管理分发列表;
……
还有一个idea是关于“推”和“拉”结合的形式,例如,服务端只负责通知某一些数据已经准备好,至于是否需要获取和什么时候客户端来获取这些数据,完全由客户端自行确定。
四 虚拟内存(linux的swap)
1 技术介绍
程序均需经由内存执行,若执行的程序占用内存很大或很多,则会导致内存消耗殆尽。为解决该问题,Windows中运用了虚拟内存[2] 技术,即匀出一部分硬盘空间来充当内存使用。当内存耗尽时,电脑就会自动调用硬盘来充当内存,以缓解内存的紧张。若计算机运行程序或操作所需的随机存储器(RAM)不足时,则 Windows 会用虚拟存储器进行补偿。它将计算机的RAM和硬盘上的临时空间组合。当RAM运行速率缓慢时,它便将数据从RAM移动到称为“分页文件”的空间中。将数据移入分页文件可释放RAM,以便完成工作。 一般而言,计算机的RAM容量越大,程序运行得越快。若计算机的速率由于RAM可用空间匮乏而减缓,则可尝试通过增加虚拟内存来进行补偿。但是,计算机从RAM读取数据的速率要比从硬盘读取数据的速率快,因而扩增RAM容量(可加内存条)是最佳选择。
2 工作原理
3 虚实地址
五 http和https
1 引言
http: 超文本传输协议http协议被用于在web浏览器和网站服务器之间传递信息,http协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了web浏览器和网站服务器之间的 传输报文,就可以读懂其中的信息。因此http协议不适合传输一些银行卡号,密码等敏感信息
https: https是以安全为目标的http通道,简单来说就是http的安全版,即http下加入ssl(secure sockets layer)层,https的安全基础是ssl。https协议的主要作用可以分为两种: 一种是建立一个信息安全通道,来保证数据传输的安全; 另一种就是确认网站的真实性.
2 http和https的区别
1 https协议需要到ca申请证书,一般免费证书较少,因此需要一定费用
2 http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议
3 http和https使用的是完全不同的连接方式,用的端口不一样,前者是80,后者是443
4 http的连接很简单,是无状态的; https协议是由ssl + http协议构建的可进行加密传输,身份认证的网络协议,比http协议安全
3 通信过程
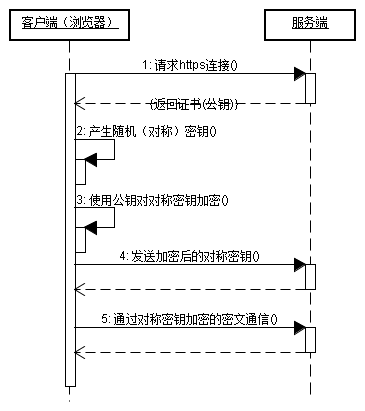
客户端在使用HTTPS方式与Web服务器通信时有以下几个步骤,如图所示。
(1)客户使用https的URL访问Web服务器,要求与Web服务器建立SSL连接。
(2)Web服务器收到客户端请求后,会将网站的证书信息(证书中包含公钥)传送一份给客户端。
(3)客户端的浏览器与Web服务器开始协商SSL连接的安全等级,也就是信息加密的等级。
(4)客户端的浏览器根据双方同意的安全等级,建立会话密钥,然后利用网站的公钥将会话密钥加密,并传送给网站。
(5)Web服务器利用自己的私钥解密出会话密钥。
(6)Web服务器利用会话密钥加密与客户端之间的通信。
4 https的优缺点
优点:
(1) 使用HTTPS协议可认证用户和服务器,确保数据发送到正确的客户机和服务器
(2) HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全,可防止数据在传输过程中不被窃取、改变,确保数据的完整性。它是现行架构下最安全的解决方案,虽然不是绝对安全,但它大幅增加了中间人攻击的成本。
缺点:
(1) https协议握手阶段比较费时,会使页面的加载时间延长近50%。
(2) https连接缓存不如http高效,会增加数据开销和功耗,甚至已有的安全措施也会因此受到影响
(3) ssl证书需要钱,功能越强大费用越高,个人网站小型网站没必要用
(4) 加密范围比较有限,在黑客攻击,拒绝服务攻击,服务器劫持等方面起不到什么作用。最关键的,SSL证书的信用链体系并不安全,特别是在某些国家可以控制CA根证书的情况下,中间人攻击一样可行。
六 网络连接的建立过程

当我们在浏览器输入网址并回车后,一切从这里开始
1 DNS域名解析
将域名解析成对应的服务器ip地址这项工作,是由DNS服务器完成的
客户端收到你输入的域名地址后,它首先去找本地的hosts文件,检查在该文件中是否有相应的域名,ip对应关系。如果有,则向其IP地址发送请求,若没有,再去找DNS服务器。一般用户很少去编辑修改hosts文件
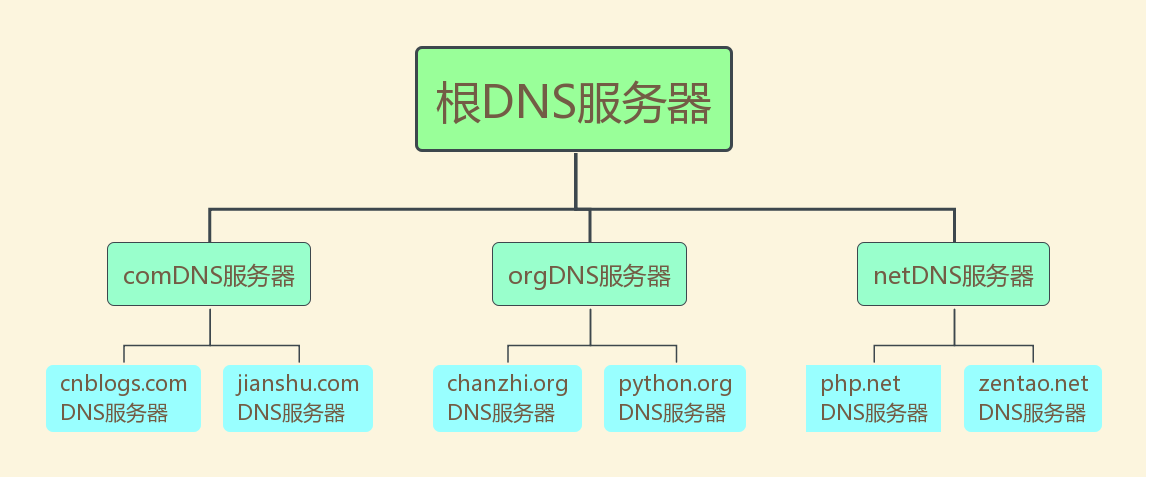
DNS服务器层次结构

浏览器客户端向本地DNS服务器发送一个含有域名www.cnblogs.com的DNS查询报文。本地DNS服务器把查询报文转发到根DNS服务器,根DNS服务器注意到其com后缀,于是向本地DNS服务器返回comDNS服务器的IP地址。本地DNS服务器再次向comDNS服务器发送查询请求,comDNS服务器注意到其www.cnblogs.com后缀并用负责该域名的权威DNS服务器的IP地址作为回应。最后,本地DNS服务器将含有www.cnblogs.com的IP地址的响应报文发送给客户端。
从客户端到本地服务器属于递归查询,而DNS服务器之间的交互属于迭代查询。
正常情况下,本地DNS服务器的缓存中已有comDNS服务器的地址,因此请求根域名服务器这一步不是必需的。
2 建立TCP连接
费了一顿周折终于拿到服务器IP了,下一步自然就是链接到该服务器。对于客户端与服务器的TCP链接,必然要说的就是『三次握手』。
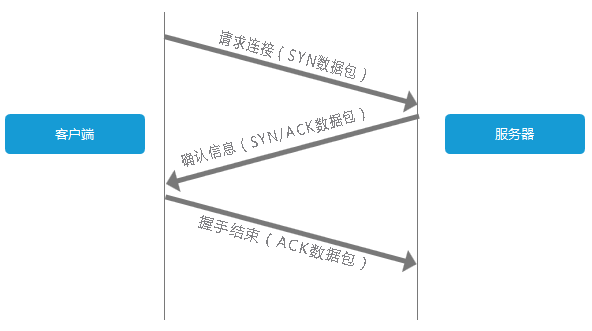
客户端发送一个带有SYN标志的数据包给服务端,服务端收到后,回传一个带有SYN/ACK标志的数据包以示传达确认信息,最后客户端再回传一个带ACK标志的数据包,代表握手结束,连接成功。
上图也可以这么理解:
客户端:“你好,在家不,有你快递。”
服务端:“在的,送来就行。”
客户端:“好嘞。”
3 发送http请求
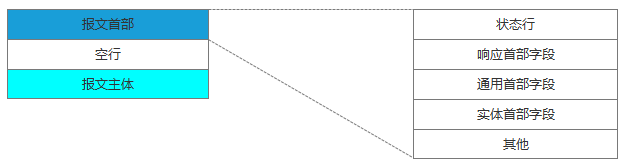
与服务器建立了连接后,就可以向服务器发起请求了。这里我们先看下请求报文的结构(如下图):

在浏览器中查看报文首部(以google浏览器为例):
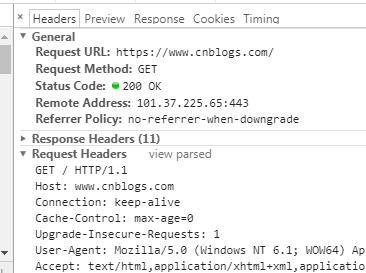
请求行包括请求方法、URI、HTTP版本。首部字段传递重要信息,包括请求首部字段、通用首部字段和实体首部字段。我们可以从报文中看到发出的请求的具体信息。具体每个首部字段的作用,这里不做过多阐述。
4 服务器处理请求
服务器端收到请求后的由web服务器(准确说应该是http服务器)处理请求,诸如Apache、Ngnix、IIS等。web服务器解析用户请求,知道了需要调度哪些资源文件,再通过相应的这些资源文件处理用户请求和参数,并调用数据库信息,最后将结果通过web服务器返回给浏览器客户端。

服务器处理请求
5 返回响应结果
在HTTP里,有请求就会有响应,哪怕是错误信息。这里我们同样看下响应报文的组成结构:
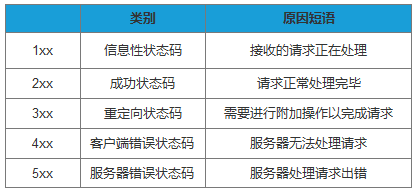
在响应结果中都会有个一个HTTP状态码,比如我们熟知的200、301、404、500等。通过这个状态码我们可以知道服务器端的处理是否正常,并能了解具体的错误。
状态码由3位数字和原因短语组成。根据首位数字,状态码可以分为五类:
6 关闭TCP连接
为了避免服务器与客户端双方的资源占用和损耗,当双方没有请求或响应传递时,任意一方都可以发起关闭请求。与创建TCP连接的3次握手类似,关闭TCP连接,需要4次握手。

上图可以这么理解:
客户端:“兄弟,我这边没数据要传了,咱关闭连接吧。”
服务端:“收到,我看看我这边有木有数据了。”
服务端:“兄弟,我这边也没数据要传你了,咱可以关闭连接了。”
客户端:“好嘞。”
7 浏览器解析HTML
准确地说,浏览器需要加载解析的不仅仅是HTML,还包括CSS、JS。以及还要加载图片、视频等其他媒体资源。
浏览器通过解析HTML,生成DOM树,解析CSS,生成CSS规则树,然后通过DOM树和CSS规则树生成渲染树。渲染树与DOM树不同,渲染树中并没有head、display为none等不必显示的节点。
要注意的是,浏览器的解析过程并非是串连进行的,比如在解析CSS的同时,可以继续加载解析HTML,但在解析执行JS脚本时,会停止解析后续HTML,这就会出现阻塞问题,关于JS阻塞相关问题,这里不过多阐述。
8 浏览器布局渲染
根据渲染树布局,计算CSS样式,即每个节点在页面中的大小和位置等几何信息。HTML默认是流式布局的,CSS和js会打破这种布局,改变DOM的外观样式以及大小和位置。这时就要提到两个重要概念:replaint和reflow。
replaint:屏幕的一部分重画,不影响整体布局,比如某个CSS的背景色变了,但元素的几何尺寸和位置不变。
reflow: 意味着元件的几何尺寸变了,我们需要重新验证并计算渲染树。是渲染树的一部分或全部发生了变化。这就是Reflow,或是Layout
所以我们应该尽量减少reflow和replaint,我想这也是为什么现在很少有用table布局的原因之一。
最后浏览器绘制各个节点,将页面展示给用户。
七 网盘给每个人免费2TB存储空间背后的原理
前段时间在使用百度网盘时,突然发现百度网盘可以免费领取 2TB 空间啦!
网络硬盘大家可能都或多或少的接触过,不得不说在万物皆云的时代里,这是一种非常好的网络工具,而对我们这种穷到掉渣的免费用户来说,硬盘空间简直就是硬伤,刚开始使用的时候真是为了空间,各种折腾(做他那里所谓的任务),到头来也才扩充了5G左右。现在好了,随随便便、轻轻松松就有了2T的空间。
而这突如其来的2T空间是如何实现的呢?
事实是这样滴!
假如我想要为每个用户提供 1G 的网络存储空间。
如果服务器上有一颗 1000G 的硬盘可以全部为用户提供数据储存,如果每个用户分配 1G 的最大储存空间,那么能分配给多少个用户使用呢?
你一定说是 1000/1=1000 个用户。
但是事实上你这么分配了,你会发现每个用户平时根本不会上传 1G 的东西将容量占的满满的,有多有少,但平均用户平时只上传 50M 的文件,也就是说,如果你将 1000G 的硬盘分给 1000个人使用,但只有效利用了其中的 50M*1000=50G 的空间,剩余 950G 的空间基本都完全浪费了。
那么怎么解决呢?
你可以变通一下,将这 1000G 的空间分配给 20000个用户使用,每个人的上传上限容量还是1G,但每人平时还是平均上传 50M 的数据,那么 20000*50M=1000G,这下子就把宝贵的服务器上的存储空间充分利用了。但你又怕这样分配给 20000个人后,万一某一刻人们突然多上传点数据,那么用户不是就觉察出来你分给人家的 1G 空间是假的了吗?所以可以不分配那么多人,只分配给 19000 人,剩下一些空间做应急之用。
突然发现一下子将可分配的用户数量翻了 19倍啊,了不起。那还有没有办法更加有效的利用一下呢?
如果我有 1000个 以上的服务器,一个服务器上有 1000G 空间,那么我们每个服务器上都要留下 50G 的空白空间以备用户突然上传大数据时导致数据塞满的情况,那么我这 1000个服务器上就空出了 1000台*50G=50000G 的空间被浪费了,多么可惜。所以攻城狮们发明了存储集群,使得一个用户的数据可以被分配在多个服务器上存储,但在用户那看起来只是一个 1G 的连续空间,那么就没必要在每个服务器上预留出应急的空间了,甚至可以充分的将前一个服务器塞满后,在将数据往下一个服务器中塞。这样保证了服务器空间的 最大利用,如果某一刻管理员发现用户都在疯狂上传数据(在一个大规模用户群下,这样的概率少之又少)导致我现有提供的空间不够了,没关系,只需要随手加几块硬盘或者服务器就解决了。
好吧,这下子我们的服务器空间利用高多了,可以将一定量的空间分配给最多的用户使用了。但有没有更好的改进方案呢?
管理员有一天发现,即使每个用户平均下来只存储 50M 的东西,但这 50M 也不是一蹴而就的,是随着1-2年的使用慢慢的达到这个数量的,也就是说,一个新的用户刚刚注册我的网络空间时,不会上传东西,或者只上传一点非常小的东西。那么我为每一个用户都初始分配了 50M 的空间,即使将来2年后他们会填满这 50M ,但这期间的这空间就有很多是浪费的啊。所以聪明的攻城狮说:既然我们可以分布式、集群式存储,一个用户的数据可以分布在多个服务器上,那么我们就假设一开始就给一个新注册的用户提供 0M 的空间,将来他用多少,我就给他提供多少存储空间,这样就彻底的保证硬盘的利用了。但用户的前端还是要显示 1G 的。
工程师的这个点子,使得我在建立网盘初期能用 1台 1000G 的服务器提供了大约 1000000 人来注册和使用,随着注册的人多了,我也有钱了,也可以不断增加服务器以提供他们后期的存储了。同时因为一部分服务器完成了一年多购买,我的购买成本也下来了。
那么…这就结束了吗?
若是邮箱提供商的话,这样的利用率够高了。但网盘就不一样了。
聪明的工程师发现:不同于邮箱,大家的内容和附件绝大多数都是自创的和不同的。但网盘上大家上传的东西很多都是重复的。
比如:张三今天下载了一部《TOKYO HOT》上传到了自己的网盘上,李四在三天后也下载了一模一样的《TOKYO HOT》上传到了网络硬盘上,随着用户的增多,你会发现总共有 1000个人上传了1000份一模一样的文件到你宝贵的服务器空间上,所以工程师想出一个办法,既然是一样的文件,我就只存一份不久好啦,然后在用户的前端显示是没人都有一份不久行啦。当某些用户要删除这个文件的时候,我并不真的删除,只需要在前端显示似乎删除了,但后端一直保留着以供其他拥有此文件的用户下载。直到所有使用此文件的用户都删除了这个文件我再真的将其删除吧。
这样子随着存储的数据越来越多,注册的用户越来越多,其上传的重复数据越来越多。你发现这样的检测重复文件存储的效率越来越大。这样算下来似乎每个人上传的不重复的文件只能平均 1M/用户。这下子你可以提供超过50倍的用户使用您这有限的空间了。
但伴随着使用,你又发现一个规律:
张三上传的《TOKYO HOT N0124》和李四上传的《TH n124》是同一个文件,只不过文件名不一样,难道我就不能识别出他们是一个文件,然后只将其分别给不同的用户保存成不同的文件名不就行啦?确实可行,但这要利用一些识别文件相同性的算法,例如MD5值等。只要两个文件的 MD5 值一样,文件大小一样,我就认为它们是相同的文件,只需要保存一份文件并给不同的用户记作不同的文件名就好了。
有一天你发现,因为每一个文件都需要计算 MD5 值,导致 CPU 负荷很大,而且本来一样的文件非要浪费带宽上传回来才可以检测一致性,能改进一下吗?
聪明的工程师写了个小软件或小插件,美其名曰“上传控件”,将计算 MD5 的工作利用这个软件交给了上传用户的电脑来完成,一旦计算出用户要上传的数据和服务器上已经存储的某个数据是一样的,就干脆不用上传了,直接在用户那里标记上这个文件已经按照 XX 文件名上传成功了。这个过程几乎是瞬间搞定了,并给其起了个高富帅的名字“秒传”!
通过以上这么多步骤,你发现本来你只能给 1000用户 提供网络空间的,这么多改进办法后,在用户端显示 1G 空间不变的情况下,近乎可以为 1000000个用户 提供网络空间了。
这样若是您哪天心情好,对外宣传说:我要将每个用户的存储空间上限提升到 1TB。那么每个用户平均还是只上传 50M 数据,只有极个别的用户上传了突破 1G 原始空间的数据,你会发现所付出的成本近乎是微乎其微的。
辛勤的攻城狮还在为如何更有效率的利用服务器提供的磁盘空间在不屑努力和挖掘着……