pandas对象中的数据可以通过一些内置的方法进行合并:pandas.merge,pandas.concat,实例方法join,combine_first,它们的使用对象和效果都是不同的,下面进行区分和比较。
数据的合并可以在列方向和行方向上进行,即下图所示的两种方式:

pandas.merge和实例方法join实现的是图2列之间的连接,以DataFrame数据结构为例讲解,DataFrame1和DataFrame2必须要在至少一列上内容有重叠,index也好,columns也好,只要是有内容重叠的列即可,指定其中一列或几列作为连接的键,然后按照键,索引DataFrame2其他列上的的数据,添加DataFrame1中。例,以columns内容作为连接键:
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
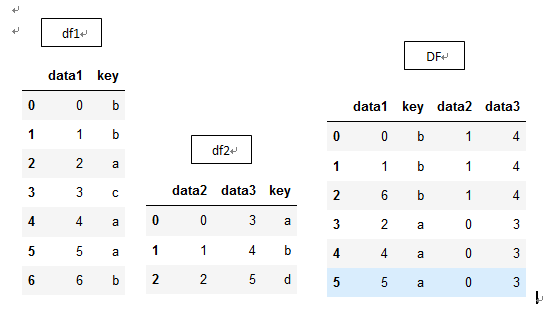
df1 = DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data1': range(7)})
df2 = DataFrame({ 'key': ['a', 'b', 'd'],
'data2': range(3),
'data3':range(3,6)})
DF1=pd.merge(df1, df2)
通过设置merge参数'on','left_on','right_on'可以指定用来连接的列(即关键的重复内容列),也可以将index作为连接键,只要传入left_index=True或right_index=True(或两个都传)来说明索引被用作连接键,例:
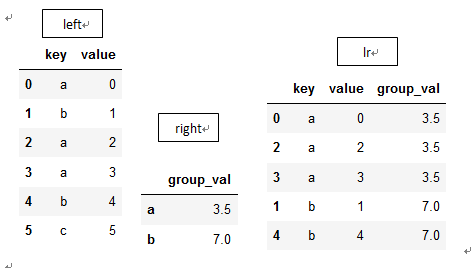
left1 = DataFrame({'key': ['a', 'b', 'a', 'a', 'b', 'c'],
'value': range(6)})
right1 = DataFrame({'group_val': [3.5, 7]}, index=['a', 'b'])
lr=pd.merge(left1, right1, left_on='key', right_index=True)
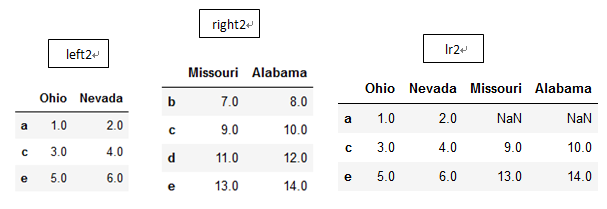
而实例方法join默认通过index来进行连接,例:
left2 = DataFrame([[1., 2.], [3., 4.], [5., 6.]], index=['a', 'c', 'e'], columns=['Ohio', 'Nevada']) right2 = DataFrame([[7., 8.], [9., 10.], [11., 12.], [13, 14]], index=['b', 'c', 'd', 'e'], columns=['Missouri', 'Alabama']) lr2=left2.join(right2, how='outer')
join方法也可以通过列来连接,同样设置参数‘on’即可。
上面介绍的函数实现的均是列之间的连接,要实现行之间的连接,要使用pd.concat方法,例:
s1 = Series([0, 1], index=['a', 'b']) s2 = Series([2, 3, 4], index=['c', 'd', 'e']) s3 = Series([5, 6], index=['f', 'g']) ss=pd.concat([s1, s2, s3]) st=pd.concat([s1,s2,s3],axis=1)
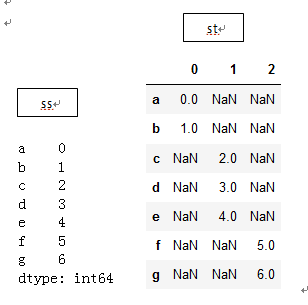
concat默认在axis=0上工作(沿着负y轴的方向),当设置axis=1时(沿着x轴的方向),它同时也可以实现列之间的连接,产生一个DataFrame。
最后一个实例方法combine_first,它实现既不是行之间的连接,也不是列之间的连接,它在为数据“打补丁”:用参数对象中的数据为调用者对象的缺失数据“打补丁”。例:
a = Series([np.nan, 2.5, np.nan, 3.5, 4.5, np.nan],
index=['f', 'e', 'd', 'c', 'b', 'a'])
b = Series(np.arange(len(a), dtype=np.float64),
index=['f', 'e', 'd', 'c', 'b', 'a'])
b[-1] = np.nan
c=b[:-2].combine_first(a[2:])
df1 = DataFrame({'a': [1., np.nan, 5., np.nan],
'b': [np.nan, 2., np.nan, 6.],
'c': range(2, 18, 4)})
df2 = DataFrame({'a': [5., 4., np.nan, 3., 7.],
'b': [np.nan, 3., 4., 6., 8.]})
df=df1.combine_first(df2)

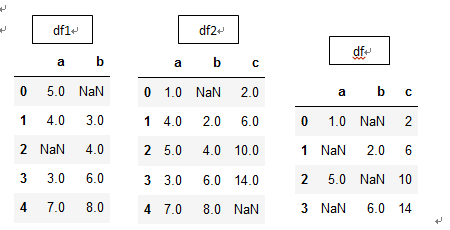
简单总结来说,通过merge和join合并的数据后数据的列变多,通过concat合并后的数据行列都可以变多(axis=1),而combine_first可以用一个数据填充另一个数据的缺失数据。
注:以上所有实验都是默认的“inner”连接方式(交集),可以通过“how”参数改变。