前言:很久没有写一些东西了,这次把一些以前写好的贴上来,可能其中有些不对或者不准确的地方请朋友指正,这里先谢谢大家了。2012-5-13 by whuai QQ:329570985 欢迎指正!
1.表空间文件
Innodb存储引擎在存储设计上模仿了Oracle的存储结构,其数据是按照表空间进行存储的,默认情况下,在Innodb存储引擎会初始化一个名为ibdata1的表空间文件,同时这个文件会存储所有表的数据,包括系统表SYS_TABLES、SYS_COLUMNS、SYS_INDEXES、SYS_FIELDS等。
Innodb存储引擎的设计很灵活,可以通过参数innodb_file_per_table来设置每一个表都对应一个自己的独立表空间文件,而不是存储到公共的ibdata1文件中,独立的表空间文件中只存储对应表的B树数据、索引和插入缓冲等信息,其余信息还是存储在默认表空间中的。
Innodb存储引擎的表空间文件的组织结构也是通过段、簇、页面构成的,下面分别做介绍。
1.段
段是表空间文件中的主要组织结构,它是物理上的管理物理空间的一个逻辑概念,它是构成索引、表、回滚段的基本元素,创建一个索引(B树)时会同时创建两个段,分别是内节点段和叶子段,内节点段用来管理(存储)B树中非叶子节点(页面)的数据,叶子段用来管理(存储)B树中叶子节点的数据。
2.簇
簇是构成段的基本元素,一个段是由若干个簇构成的,一个簇是物理上连续分配的一段空间,每一个段至少会有一个簇,在创建一个段的时候会创建一个默认的簇,如果数据在存储时一个簇已经不足以放得到更多的数据,此时需要从这个段中分配一个新的簇,来存放新的数据,段对多个簇的管理后面会做更详细的介绍。
3.页面
页面是数据库中文件管理的最小无素,也是文件中空间分配的最小单位,也是构成簇的基本元素,一个簇中可以包括多个页面(默认为64个页面),这个页面数通常被叫做“簇的大小”,这些页面都是归这个簇管理的,这些页面在逻辑上(页面号都是从小到大连续的)及物理上都是连续的,在向表中插入数据的时如果一个页面已经被写完,则系统会从当前簇中分配一个新的空闲页面出来使用,如果当前簇中的64个页面都被分配完,系统会从当前页面所在段中分配一个新的簇,然后再从这个簇中分配一个新的页面都使用,依此类推。更简单的说,表空间文件就是被划分成相等长度的块,每一个块就是一个页面,一个页面默认为16KB。
下面是段、簇、页面之间的一个简单的关系图:
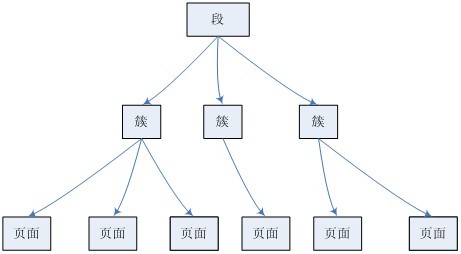
图1.1 段、簇及页面的关系
2.段、簇、页组织结构
上面已经提到,段是由多个簇组成,簇是由默认64个页面组成,但在具体实现上它们是如何组织,如果实现的呢?下面就主要从innodb的源代码角度来讨论它们的组织方式。
一个表空间可以有多个文件,每个文件都有各自的编号,那么创建一个表空间都至少有一个文件,这个文件被称为“0号文件”,上面已经提到,一个文件是被切割为等长(默认16KB)的块,这个块通常被称为页面,那么在“0号文件”的第一个页面(page_no为0)中存储了这个表空间中所有的段簇页管理的入口,从这个页面偏移为FIL_PAGE_DATA(38)的位置开始存储了表空间描述信息,描述信息中包括如下主要信息:
FSP_SPACE_ID:当前表空间ID号,每一个表空间都有一个唯一的ID号,在创建时分配。
FSP_SIZE:当前表空间总的页面数,一个表空间可以有多个文件,这个值表示这个表空间中所有文件按照页面(默认16KB)大小划分的页面数。
FSP_FREE:表空间中所有的段中的簇都是由表空间统一管理的,这个地址是一个链表头指针,表空间中所有的空闲簇都以链表的形式存储到这个链表中。
FSP_FREE_FRAG:一个簇可以管很多页面(默认值64个页),如果这个簇中已经有被使用(分配)的页面,则这个簇就被称为半满簇,那么这个地址就是存储所有半满簇的链表头指针。
FSP_FULL_FRAG:根据上面已经叙述过的,如果一个簇中所有的页面都已经被分配(使用)了,则这个簇就被称为满簇,这个地址就是用来存储所有满簇的链表头指针。
FSP_FRAG_N_USED:这个值表示上面FSP_FREE_FRAG链表中,所有已经被使用过的页面数,在分配页面时,每从FSP_FREE_FRAG链表中分配一个空闲页,这个值都会加1并写入到文件中。
FSP_SEG_ID:在表空间中,每一个段都有一个唯一分配的ID号,这个值表示的是下一个段的ID号,在每次使用之后这个值都会自加,这样保证所有的ID号都是不相同的。
FSP_SEG_INODES_FULL:这里需要先介绍一下Inode,Inode是用来管理一个段的,简单说,一个Inode就是代表一个数据段。Inode可以说是一个结构体,它也是像上面一样,按顺序存储到Inode页面中,一个Inode页面可以存储多个Inode节点。如果页面中所有的空间都用来存放已经使用的Inode,则这个页面就称为满Inode页面,否则为半满Inode页面。FSP_SEG_INODES_FULL就是用来存储所有的满Inode页面的链表头指针。
FSP_SEG_INODES_FREE:用来存储所有的半满Inode页面的链表头指针。
Inode节点用来管理一个段,一个Inode中包括以下内容:
FSEG_ID:这个表示这个段的ID号,在创建时唯一分配。
FSEG_NOT_FULL:一个段管理很多簇,这些簇都是属于这个段的,这个地址是用来存储所有半满簇的链表头指针。
FSEG_NOT_FULL_N_USED:这个地址用来存储上面半满簇链表中所有已经使用的页面总数。
FSEG_FREE:这个地址用来存储所有空闲簇的链表头指针。
FSEG_FULL:这个地址用来存储所有满簇的链表头指针。
从上面叙述中知道,表空间控制信息中有满簇链表,半满簇链表,空闲簇链表,而段的Inode信息中也有这些信息,这两个其实是不同的,表空间中的链表管理的是整个表空间中所有的簇,包括满簇、半满簇及空闲簇,而段的Inode信息中管理的是属于自己段中的满簇,半满簇及空闲簇。当段新申请一个簇时,如果段上面没有空闲的簇,此时它会从表空间的簇链表中找,找到后从相应链表中摘下来挂到段空闲簇链表中。
上面一直提到的簇,它是一个段的组成元素,段通过三个链表将不同状态的簇管理起来,链表都是双向链表,在段中,链表头分别是FSEG_FREE、FSEG_FULL、FSEG_NOT_FULL,链表节点就是簇,每个簇上面都有向前指针和向后指针。每一个簇通过一个簇描述符来表示,簇是实际的物理存储空间,簇描述符用来管理一个簇,簇描述符也是一个结构体,其内容如下:
XDES_ID:这个值表示这个簇所属的段的ID号。
XDES_FLST_NODE:这个地址用来存储簇的链表指针,包括向前指针和向后指针,每一个指针都是一个页面地址,包括page、boffset,page表示这个簇描述符在文件中的哪一个页面,它是一个页面号,boffset表示簇描述符在page页面中的偏移地址,表示从这个位置开始就是这个簇的描述符地址。
XDES_STATE:表示当前这个簇的状态,状态包括:XDES_FREE(空闲簇)、XDES_FREE_FRAG(半满簇)、XDES_FULL_FRAG(满簇)、XDES_FSEG(属于一个段)。
XDES_BITMAP:这个地址存储的是一个位图,innodb通过这个来管理一个簇中所有页面的使用情况,每一个页面用两个位来表示,簇大小FSP_EXTENT_SIZE表示的是一个簇的页面数,默认值为64,所以XDES_BITMAP占用的总长度为64*2/8=16个字节,用两个字节来表示一个页面,第一个位表示这个页面是否使用,第二个位现在还没有使用,所以一个簇描述符的大小为XDES_ID(8)+ XDES_FLST_NODE(12)+ XDES_STATE(4)+16(XDES_BITMAP的大小)=40个字节。
簇描述符是存储在簇描述页面中的,在innodb中,一个簇描述页面默认要管理16384(UNIV_PAGE_SIZE)个页面,簇大小默认为(FSP_EXTENT_SIZE)64个,而一个簇描述符的大小为40B,所以一个簇描述页面中可以描述的簇的个数为(UNIV_PAGE_SIZE-页面头长度) / 40,但一般情况下,都不会将簇描述页面存储满,因为在一个表空间中,簇描述页面的存储是每隔16384个页面就有一个是簇描述页面,所以簇描述页面中只需要描述16384个页面即可,每个簇大小为64个页面,所以需要存储的簇描述符个数为16384/64=256个,所以在页面大小为16384中,其实只用了256*40=10240B的空间,其它的空间都是空闲的。
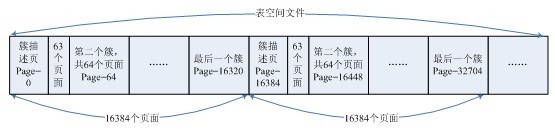
图1.2 表空间簇组织结构
从图1.2中可以看出,一个表空间文件以簇为单位被分隔开,同时每16384(默认值)个页面又用一个簇描述页面来描述,在每16384个页面的分隔中,第一个页面都用来做簇描述页面,用来描述后面的16384-64=16320个页面,那么第一个簇(其实是第一个页面)它只是用来做簇描述页面的,它没有被加入到表空间的簇链表中,也没有被加入到段的簇链表中,那么第一个簇的后面63个页面是被空出来的,是未被使用的,真正的空间使用是从第二个簇开始的,直到最后一个簇,所以簇描述页面中实际上只有255个簇描述符。
从上面可以看出来,簇描述页面中存储的簇描述符上面的信息没有体现它管理的页面是哪些,它只有一个位图用来表示它管理的64个页面是否已经被使用,但是从图1.2中发现,每16384个页面就有一个簇描述页,所以第一个描述页的页号为0,第二个为16384,依此类推;同时一个描述页面中所有的描述符描述的页面都是相隔64连续,所以只要知道一个描述符的位置,就可以计算出这个描述符所管理的页面号的范围,所以在描述符中是不需要存储它的页面信息的,通过描述符的地址即可得到。
计算方法概括如下:根据描述符的地址得到描述页的页面号describe_page_no,然后再根据其地址得到这个描述符在描述页中的序号index,然后管理的范围scope为:scope >= describe_page_no + index * FSP_EXTENT_SIZE同时scope < describe_page_no + (index + 1)* FSP_EXTENT_SIZE。
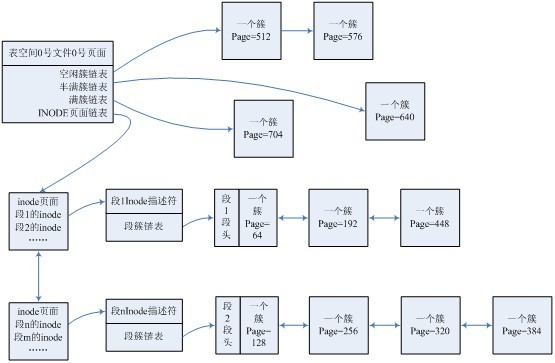
图1.3 段簇页组织结构
图1.3描述了表空间、INODE页面、INODE、段、簇、页面之间的关系,也是innodb文件系统管理架构图。
下面简单叙述一下创建一个段的过程,用来说明文件管理的实现过程。
1.根据表空间ID号得到表空间头信息;
2.从得到的表空间头中分配一个Inode,首先判断FSP_SEG_INODES_FREE链表中是否还有空闲INODE的INODE页面,如果有则从页面的数据存储位置开始扫描,因为每一个INODE的大小是固定的,所以扫描的步长是固定的,找到每一个INODE后判断INODE描述符中的FSEG_ID是否为0,如果是则没有使用,否则已经使用过了,找到第一个为0的则返回,说明已经找到了合适的INODE,如果找到后发现这个INODE是这个页最后一个INODE,则将这个页面从FSP_SEG_INODES_FREE链表中摘下来,同时将这个页面插入到FSP_SEG_INODES_FULL链表中;如果FSP_SEG_INODES_FREE链表中没有空闲的INODE页面,则需要重新分配一个INODE页面,分配后将所有的INODE描述符中的FSEG_ID置为0,表示未使用,然后将这个页面链接到FSP_SEG_INODES_FREE链表中,然后直接从这个页面中分配一个空闲的INODE,过程如上所述;
3.给新分配的INODE指定SEG_ID号,这个ID号要从表空间头的FSP_SEG_ID取出来,这个ID号就是新段的ID号,然后将这个ID号写入到INODE的FSEG_ID中,同时要更新FSP_SEG_ID中的值,更新为ID+1,表示下一个段的ID号;
4.初始化这个INODE信息,将偏移FSEG_NOT_FULL_N_USED处的值置为0;初始化链表FSEG_FREE、FSEG_NOT_FULL、FSEG_FULL;
5.从这个段中分配一个页面,分配页面时首先找到表空间头上的半满簇链表FSP_FREE_FRAG,然后从链表中找一个簇描述符,找到簇描述符之后从它的XDES_BITMAP中找一个状态为XDES_FREE_BIT的页面,返回一个0~63的下标index,再根据簇描述符计算得到这个簇管理的64个页面的首页号page,然后申请到的真正页面号就是page+index,计算方法是首先得到这个描述页的页面号descr_page,然后再得到这个簇描述符在簇描述页面中的序号seq_no,那么簇描述的首页为page=descr_page + seq_no * 64。
6.分配好页面之后,通过系统缓存得到页面号为page+index的页面,这个页面就是这个段的首页面,在一个段的首页上,需要记录这个段对应的INODE的位置,INODE的位置存储在页面头中,分别是FSEG_HDR_OFFSET(INODE在INODE页面中的偏移)、FSEG_HDR_PAGE_NO(INODE所在的INODE页面号)、FSEG_HDR_SPACE(INODE所在的表空间号)。
7.到此为止,一个段就分配完成。以后如果需要在这个段中分配空间,只要找到其首页,然后找到对应的INODE即可分配空间。