开始非常不理解from https://www.jianshu.com/p/18ec820fe706 找到了一个比较完整的借鉴,然后编写自己的煎蛋pipeline
首先在items里创建
image_urls = scrapy.Field() # images = scrapy.Field() #这两个是必须的 image_paths = scrapy.Field() #这个是因为在pipeline中设置了image_paths,所以这里要有,但不是必须的
然后在settings里面打开pipeline
ITEM_PIPELINES = {'jiandan.pipelines.JianPipeline': 1} #这里是打开pipeline
IMAGES_STORE =r'F:jiandan' #这里是存储位置,绝对路径;
然后在pipeline里编写jianpipeline
import scrapy from scrapy.pipelines.images import ImagesPipeline from scrapy.exceptions import DropItem class JianPipeline(ImagesPipeline): def get_media_requests(self, item, info): for image_url in item['image_urls']: yield scrapy.Request(image_url) def item_completed(self, results, item, info): image_paths = [x['path'] for ok, x in results if ok] if not image_paths: raise DropItem("Item contains no images") item['image_paths'] = image_paths #在这里写了image_paths,所以要在items里面声明item
return item
#此段完全摘抄自别人的代码,然后在自己里面用,
在spider主程序中只要生成item就好了,别的不用管
yield JiandanItem({ 'image_urls':urls , #只要生成这个image_urls,pipeline会自动下载这里面的链接
})
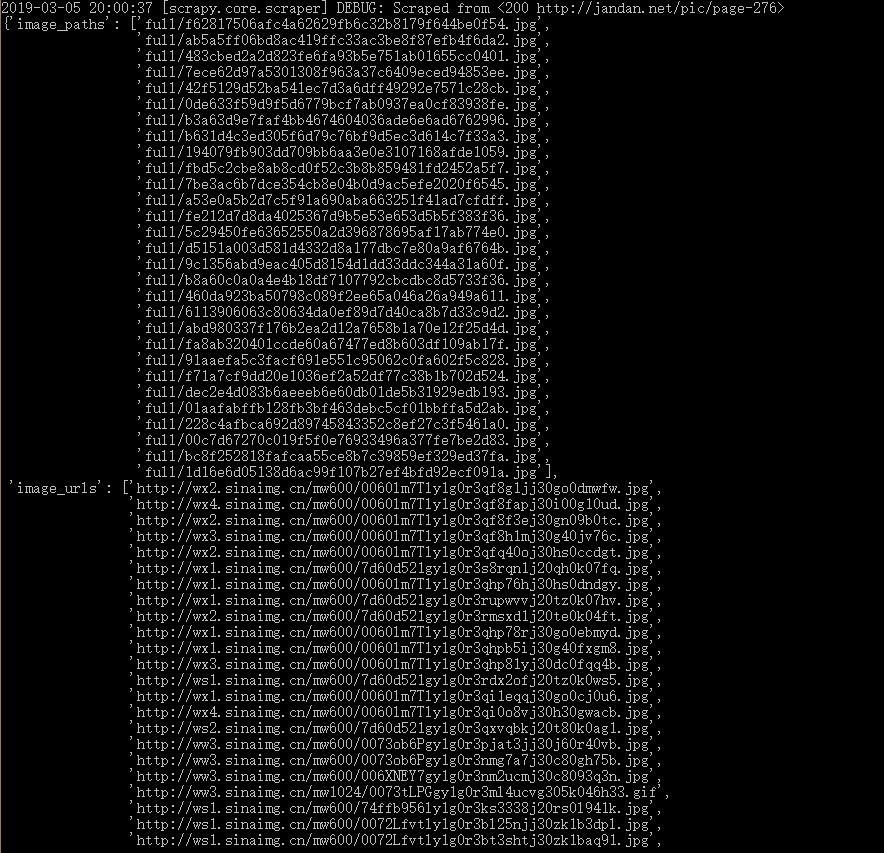
上面为实际运行情况
但是imagepipeline不能下载gif图片
******************************************************************************************************************************
改成filepipeline,更改path,这里传递的只是一个path,name,
def file_path(self, request, response=None, info=None): path = super().file_path(request, response=None, info=None) file_store = os.path.join(settings.FILES_STORE,'images') if not os.path.exists(file_store): os.mkdir(file_store) file_name = os.path.join(file_store,path) # file_guid = request.url.split('/')[-1] # filename = u'full/{0[name]}/{0[albumname]}/{1}'.format(item, file_guid) return file_name