refer:https://blog.yongli1992.com/2015/02/08/python-scrapy-module/
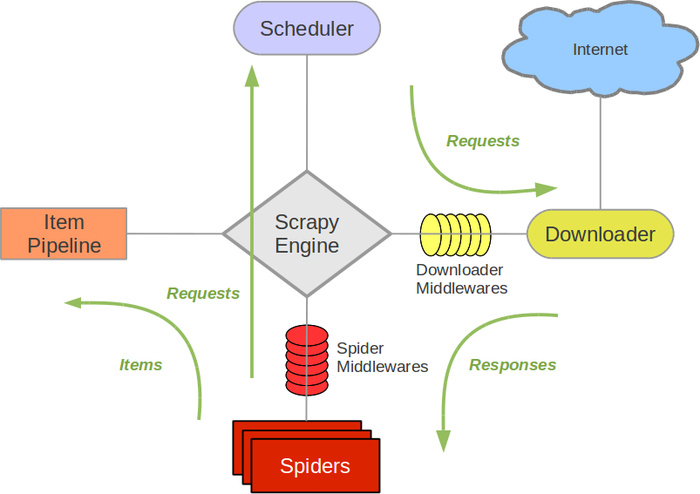
这里是一张Scrapy架构图的展示。Scrapy Engine负责整个程序的运行。Scheduler负责调度要访问的网址。Downloader负责从网络获取响应。Spider负责分析响应,从响应中解析出我们要的数据,同时也负责找出接下来要访问的后续网址。Item是将我们需要抓取的数据做一个结构化的定义并实现为一个类。Pipeline负责对抓取到的item做后续处理,包括过滤,持久化存储等任务。
绿色箭头表示网络请求与响应的流动。Spider将需要访问的(初始+后续)请求提交给调度器,调度器再将请求分发给Downloader,downloader完成下载后,通过回调函数的形式交由Spider进一步处理,Spider抽取出需要的数据,实例化一个item对象,将数据赋值为item的具体属性。item接下来将经过pipeline,由pipeline实现后续处理。
在一个较为简单的应用中,真正需要我们实现的部分只有定义item,实现spider,实现pipeline。(还有settings也应该修改的)