原文地址:
https://mp.weixin.qq.com/s?__biz=MzAwNTQ4MTQ4NQ==&mid=306076506&idx=1&sn=75e68dcc2efcd0c50589e3983b6b6adc&chksm=0cd10e383ba6872e234d49b1b30fdf0236046893afd86b221dae243e734e89b1569b380dd70a&mpshare=1&scene=23&srcid=0619vldqxhu5uslv3Reh2a8s#rd
Spark Streaming 无法找到数据块问题
最近一个Spark Streaming项目停止了几个小时,发现后设置为自动重启。结果,Spark Streaming频繁重启,平均十分钟左右就要重启一次。
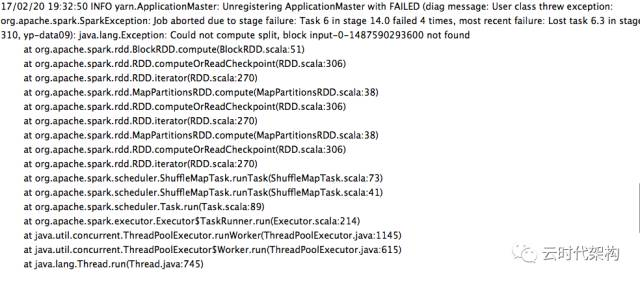
异常信息为:org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.namenode.LeaseExpiredException): No lease on /user/ypdata/checkpoint/temp (inode 120825098): File does not exist. [Lease.Holder: DFSClient_NONMAPREDUCE_1085161746_1, pendingcreates: 1]
问题定位:
这个项目采用的Spark Streaming + kafka的模式,spark streaming实时从kafka拉取数据。
频繁重启,间隔很确定的话,就怀疑是OOM导致的,因为数据在kafka端堆积,启动spark streaming后,会不停去kafka取数据(采用了high level的模式,没有控制速率),spark采用的模式是MEMROY_ONLY_SER模式,超过了driver-memory和executor-memory后,spark会自动丢弃放不下的数据,那么当需要计算该数据时自然报错说找不到数据块。
直到堆积的数据都在kafka消费完毕。 后来的现象也证实了这一点,重启了十几次,过了两个小时后,恢复正常。
解决方案:
但是随着数据量的越来越多,这种情况还是会出现,而且无法解决。
1. 采用kafka low-level的api,控制消费速率,保护spark。 牺牲了实时性。
2.加大spark的driver-memory和executor-memory,同时支持序列化到磁盘。