打分机制
# es:重要的就是查询,全文检索 # 打分机制的公式:TF-IDF - 一个词条在某篇文档中出现的次数越多,该文档就越相关,分越高,`TF`是词频(term frequency) - 一个词条如果在不同的文档中出现的次数越多,它就越不相关,分越低,`IDF`是逆文档频率
# 方案一 :广播 -只需要启动es,自动加入到集群中,一旦加入进去,自行完成数据copy -只需要启动读个es,自动加入到集群中(集群名字一样,才能加入到集群) # 方案二:单播 -1 在每个es的配置文件中写入配置 cluster.name: my_es1 node.name: node1 network.host: 127.0.0.1 http.port: 9200 transport.tcp.port: 9300 discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9302", "127.0.0.1:9303", "127.0.0.1:9304"] -2 启动es即可,自动加入集群 -3 可以在任意节点查数据,写数据,都是往集群中写,从集群中查 -4 自己实现注册发现,重试 # 保证高可用: -有一个节点挂了,数据还是完整(相对的)
# 假设10个节点,一个集群 # 4个节点挂了,4个节点又上来了,4个节点组成一个集群,选了一个主,6个组成一个集群,选了一个主
脑裂问题出现的原因,如何解决?
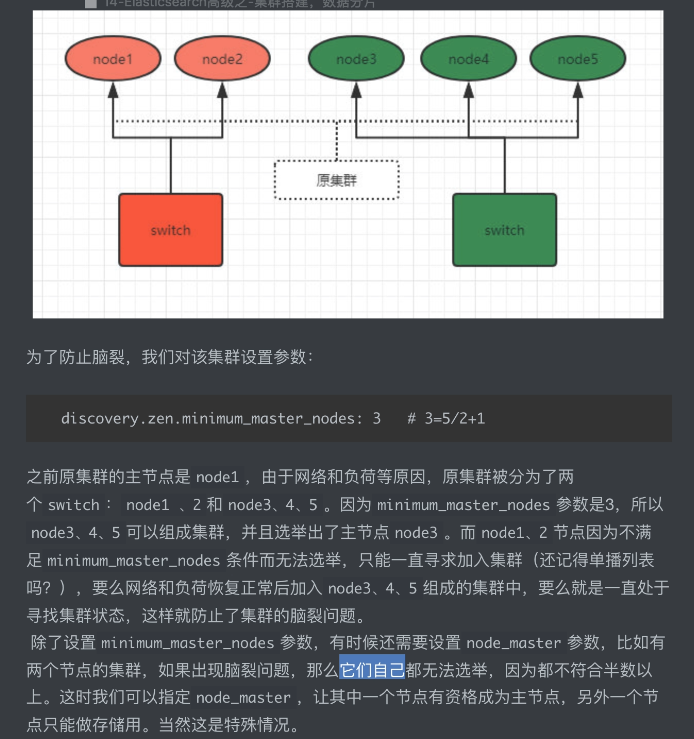
# 通过配置文件: discovery.zen.minimum_master_nodes: 3