一 简介
Shuffle,简而言之,就是对数据进行重新分区,其中会涉及大量的网络io和磁盘io,为什么需要shuffle,以词频统计reduceByKey过程为例,
serverA:partition1: (hello, 1), (word, 1)
serverB:partition2: (hello, 2)
shuffle之后:
serverA:partition1: (hello, 1), (hello, 2)
serverB:partition2: (word, 1)
最后才能得到结果:
(hello, 3), (word, 1)
shuffle过程借用网上的图
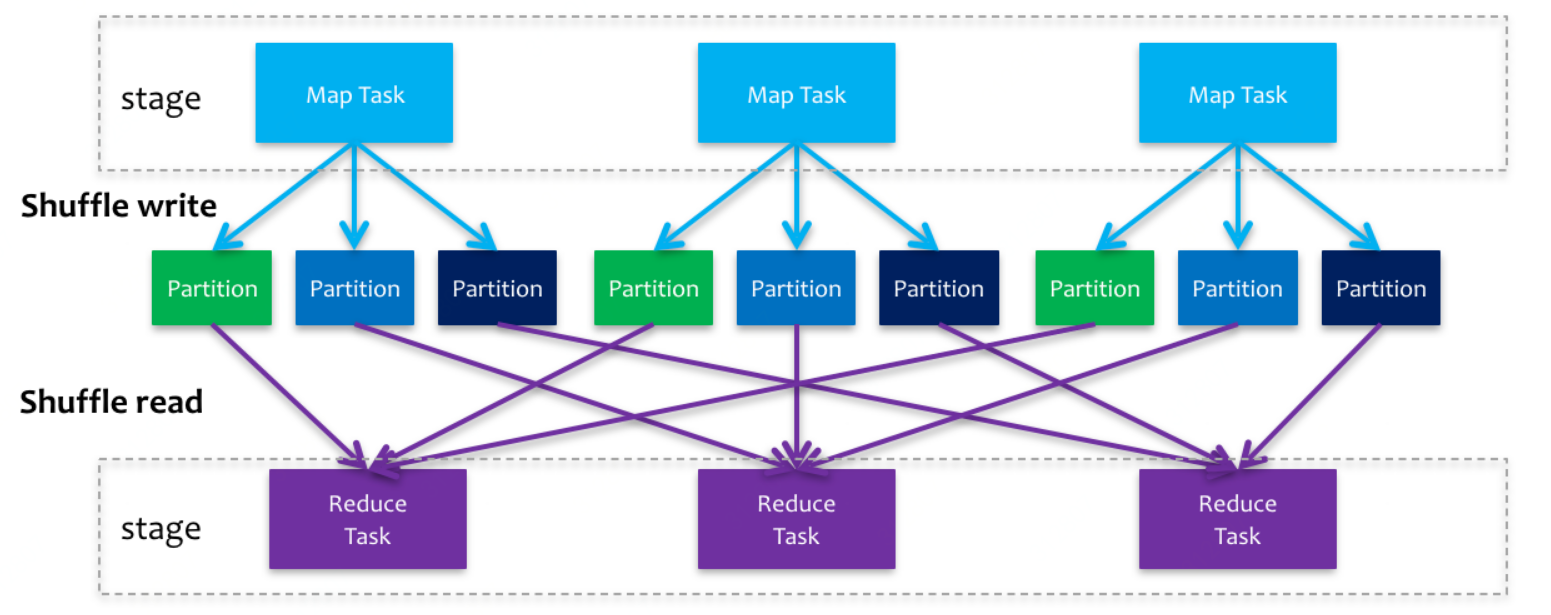
下面是官方描述,官方文档详见 https://spark.apache.org/docs/latest/rdd-programming-guide.html#shuffle-operations
Certain operations within Spark trigger an event known as the shuffle. The shuffle is Spark’s mechanism for re-distributing data so that it’s grouped differently across partitions. This typically involves copying data across executors and machines, making the shuffle a complex and costly operation.
To understand what happens during the shuffle we can consider the example of the reduceByKey operation. The reduceByKey operation generates a new RDD where all values for a single key are combined into a tuple - the key and the result of executing a reduce function against all values associated with that key. The challenge is that not all values for a single key necessarily reside on the same partition, or even the same machine, but they must be co-located to compute the result.
In Spark, data is generally not distributed across partitions to be in the necessary place for a specific operation. During computations, a single task will operate on a single partition - thus, to organize all the data for a single reduceByKey reduce task to execute, Spark needs to perform an all-to-all operation. It must read from all partitions to find all the values for all keys, and then bring together values across partitions to compute the final result for each key - this is called the shuffle.
Operations which can cause a shuffle include repartition operations like repartition and coalesce, ‘ByKey operations (except for counting) like groupByKey and reduceByKey, and join operations like cogroup and join.
The Shuffle is an expensive operation since it involves disk I/O, data serialization, and network I/O. To organize data for the shuffle, Spark generates sets of tasks - map tasks to organize the data, and a set of reduce tasks to aggregate it. This nomenclature comes from MapReduce and does not directly relate to Spark’s map and reduce operations.
二 原理及代码解析
Spark中的shuffle实现还是比较复杂的,下面从reduceByKey的shuffle实现来看代码:
org.apache.spark.rdd.PairRDDFunctions
/** * Merge the values for each key using an associative and commutative reduce function. This will * also perform the merging locally on each mapper before sending results to a reducer, similarly * to a "combiner" in MapReduce. Output will be hash-partitioned with the existing partitioner/ * parallelism level. */ def reduceByKey(func: (V, V) => V): RDD[(K, V)] = self.withScope { reduceByKey(defaultPartitioner(self), func) } /** * Merge the values for each key using an associative and commutative reduce function. This will * also perform the merging locally on each mapper before sending results to a reducer, similarly * to a "combiner" in MapReduce. */ def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope { combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner) } def combineByKeyWithClassTag[C]( createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, partitioner: Partitioner, mapSideCombine: Boolean = true, serializer: Serializer = null)(implicit ct: ClassTag[C]): RDD[(K, C)] = self.withScope { require(mergeCombiners != null, "mergeCombiners must be defined") // required as of Spark 0.9.0 if (keyClass.isArray) { if (mapSideCombine) { throw new SparkException("Cannot use map-side combining with array keys.") } if (partitioner.isInstanceOf[HashPartitioner]) { throw new SparkException("HashPartitioner cannot partition array keys.") } } val aggregator = new Aggregator[K, V, C]( self.context.clean(createCombiner), self.context.clean(mergeValue), self.context.clean(mergeCombiners)) if (self.partitioner == Some(partitioner)) { self.mapPartitions(iter => { val context = TaskContext.get() new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context)) }, preservesPartitioning = true) } else { new ShuffledRDD[K, V, C](self, partitioner) .setSerializer(serializer) .setAggregator(aggregator) .setMapSideCombine(mapSideCombine) } }
调用reduceByKey返回了一个ShuffledRDD,下面看ShuffledRDD:
org.apache.spark.rdd.ShuffledRDD
class ShuffledRDD[K: ClassTag, V: ClassTag, C: ClassTag]( @transient var prev: RDD[_ <: Product2[K, V]], part: Partitioner) extends RDD[(K, C)](prev.context, Nil) { ... override def getDependencies: Seq[Dependency[_]] = { val serializer = userSpecifiedSerializer.getOrElse { val serializerManager = SparkEnv.get.serializerManager if (mapSideCombine) { serializerManager.getSerializer(implicitly[ClassTag[K]], implicitly[ClassTag[C]]) } else { serializerManager.getSerializer(implicitly[ClassTag[K]], implicitly[ClassTag[V]]) } } List(new ShuffleDependency(prev, part, serializer, keyOrdering, aggregator, mapSideCombine)) } override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = { val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]] SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context) .read() .asInstanceOf[Iterator[(K, C)]] }
ShuffledRDD类看似简单,但是需要深度解析,下面分两个部分说明:
1 ShuffledRDD.getDependencies方法
ShuffledRDD的getDependencies会返回ShuffleDependency,先看ShuffleDependency
org.apache.spark.ShuffleDependency
val shuffleId: Int = _rdd.context.newShuffleId() val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle( shuffleId, _rdd.partitions.length, this)
每次创建一个ShuffleDependency时都会创建一个shuffleId,同时调用ShuffleManager.registerShuffle得到一个ShuffleHandle,这个稍后再看;
下面看DAGScheduler对ShuffleDependencies的处理
org.apache.spark.scheduler.DAGScheduler
/** * Get or create the list of parent stages for a given RDD. The new Stages will be created with * the provided firstJobId. */ private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = { getShuffleDependencies(rdd).map { shuffleDep => getOrCreateShuffleMapStage(shuffleDep, firstJobId) }.toList } /** Submits stage, but first recursively submits any missing parents. */ private def submitStage(stage: Stage) { ... submitMissingTasks(stage, jobId.get) ... private def submitMissingTasks(stage: Stage, jobId: Int) { val tasks: Seq[Task[_]] = try { stage match { case stage: ShuffleMapStage => partitionsToCompute.map { id => val locs = taskIdToLocations(id) val part = stage.rdd.partitions(id) new ShuffleMapTask(stage.id, stage.latestInfo.attemptId, taskBinary, part, locs, stage.latestInfo.taskMetrics, properties, Option(jobId), Option(sc.applicationId), sc.applicationAttemptId) }
ShuffleDependency在DAGScheduler.createShuffleMapStage会被转化为ShuffleMapStage,然后ShuffleMapStage会被拆分为ShuffleMapTask执行;
下面看ShuffleMapTask
org.apache.spark.scheduler.ShuffleMapTask
override def runTask(context: TaskContext): MapStatus = { // Deserialize the RDD using the broadcast variable. val threadMXBean = ManagementFactory.getThreadMXBean val deserializeStartTime = System.currentTimeMillis() val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) { threadMXBean.getCurrentThreadCpuTime } else 0L val ser = SparkEnv.get.closureSerializer.newInstance() val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])]( ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader) _executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime _executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) { threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime } else 0L var writer: ShuffleWriter[Any, Any] = null try { val manager = SparkEnv.get.shuffleManager writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context) writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]]) writer.stop(success = true).get } catch { case e: Exception => try { if (writer != null) { writer.stop(success = false) } } catch { case e: Exception => log.debug("Could not stop writer", e) } throw e } }
可以看到task执行时会调用ShuffleManager.getWriter写数据,写数据过程稍后会提到;
2 ShuffledRDD.compute方法
ShuffledRDD的compute方法覆盖RDD的compute方法,将计算过程改为将ShuffleDependency传入ShuffleManager.getReader.read,要注意的是在调用compute之前,所有dependency的stage都已经执行完了,即数据已经调用ShuffleManager.getWriter写入了(至于为什么,详见 https://www.cnblogs.com/barneywill/p/10152497.html),所以这里ShuffleManager.getReader可以读到数据
ShuffleManager是spark shuffle的核心接口
org.apache.spark.shuffle.ShuffleManager
/** * Register a shuffle with the manager and obtain a handle for it to pass to tasks. */ def registerShuffle[K, V, C]( shuffleId: Int, numMaps: Int, dependency: ShuffleDependency[K, V, C]): ShuffleHandle /** Get a writer for a given partition. Called on executors by map tasks. */ def getWriter[K, V](handle: ShuffleHandle, mapId: Int, context: TaskContext): ShuffleWriter[K, V] /** * Get a reader for a range of reduce partitions (startPartition to endPartition-1, inclusive). * Called on executors by reduce tasks. */ def getReader[K, C]( handle: ShuffleHandle, startPartition: Int, endPartition: Int, context: TaskContext): ShuffleReader[K, C]
下面是实现类:
org.apache.spark.shuffle.sort.SortShuffleManager
/** * Register a shuffle with the manager and obtain a handle for it to pass to tasks. */ override def registerShuffle[K, V, C]( shuffleId: Int, numMaps: Int, dependency: ShuffleDependency[K, V, C]): ShuffleHandle = { if (SortShuffleWriter.shouldBypassMergeSort(SparkEnv.get.conf, dependency)) { // If there are fewer than spark.shuffle.sort.bypassMergeThreshold partitions and we don't // need map-side aggregation, then write numPartitions files directly and just concatenate // them at the end. This avoids doing serialization and deserialization twice to merge // together the spilled files, which would happen with the normal code path. The downside is // having multiple files open at a time and thus more memory allocated to buffers. new BypassMergeSortShuffleHandle[K, V]( shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]]) } else if (SortShuffleManager.canUseSerializedShuffle(dependency)) { // Otherwise, try to buffer map outputs in a serialized form, since this is more efficient: new SerializedShuffleHandle[K, V]( shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]]) } else { // Otherwise, buffer map outputs in a deserialized form: new BaseShuffleHandle(shuffleId, numMaps, dependency) } } /** * Get a reader for a range of reduce partitions (startPartition to endPartition-1, inclusive). * Called on executors by reduce tasks. */ override def getReader[K, C]( handle: ShuffleHandle, startPartition: Int, endPartition: Int, context: TaskContext): ShuffleReader[K, C] = { new BlockStoreShuffleReader( handle.asInstanceOf[BaseShuffleHandle[K, _, C]], startPartition, endPartition, context) } /** Get a writer for a given partition. Called on executors by map tasks. */ override def getWriter[K, V]( handle: ShuffleHandle, mapId: Int, context: TaskContext): ShuffleWriter[K, V] = { numMapsForShuffle.putIfAbsent( handle.shuffleId, handle.asInstanceOf[BaseShuffleHandle[_, _, _]].numMaps) val env = SparkEnv.get handle match { case unsafeShuffleHandle: SerializedShuffleHandle[K @unchecked, V @unchecked] => new UnsafeShuffleWriter( env.blockManager, shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver], context.taskMemoryManager(), unsafeShuffleHandle, mapId, context, env.conf) case bypassMergeSortHandle: BypassMergeSortShuffleHandle[K @unchecked, V @unchecked] => new BypassMergeSortShuffleWriter( env.blockManager, shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver], bypassMergeSortHandle, mapId, context, env.conf) case other: BaseShuffleHandle[K @unchecked, V @unchecked, _] => new SortShuffleWriter(shuffleBlockResolver, other, mapId, context) } }
ShuffleManager过程比较复杂,继续分开解析:
2.1 ShuffleManager.getWriter方法
先看getWriter后是怎样写数据的,以BypassMergeSortShuffleWriter为例
org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter
@Override public void write(Iterator<Product2<K, V>> records) throws IOException { assert (partitionWriters == null); if (!records.hasNext()) { partitionLengths = new long[numPartitions]; shuffleBlockResolver.writeIndexFileAndCommit(shuffleId, mapId, partitionLengths, null); mapStatus = MapStatus$.MODULE$.apply(blockManager.shuffleServerId(), partitionLengths); return; } final SerializerInstance serInstance = serializer.newInstance(); final long openStartTime = System.nanoTime(); partitionWriters = new DiskBlockObjectWriter[numPartitions]; partitionWriterSegments = new FileSegment[numPartitions]; for (int i = 0; i < numPartitions; i++) { final Tuple2<TempShuffleBlockId, File> tempShuffleBlockIdPlusFile = blockManager.diskBlockManager().createTempShuffleBlock(); final File file = tempShuffleBlockIdPlusFile._2(); final BlockId blockId = tempShuffleBlockIdPlusFile._1(); partitionWriters[i] = blockManager.getDiskWriter(blockId, file, serInstance, fileBufferSize, writeMetrics); } // Creating the file to write to and creating a disk writer both involve interacting with // the disk, and can take a long time in aggregate when we open many files, so should be // included in the shuffle write time. writeMetrics.incWriteTime(System.nanoTime() - openStartTime); while (records.hasNext()) { final Product2<K, V> record = records.next(); final K key = record._1(); partitionWriters[partitioner.getPartition(key)].write(key, record._2()); } for (int i = 0; i < numPartitions; i++) { final DiskBlockObjectWriter writer = partitionWriters[i]; partitionWriterSegments[i] = writer.commitAndGet(); writer.close(); } File output = shuffleBlockResolver.getDataFile(shuffleId, mapId); File tmp = Utils.tempFileWith(output); try { partitionLengths = writePartitionedFile(tmp); shuffleBlockResolver.writeIndexFileAndCommit(shuffleId, mapId, partitionLengths, tmp); } finally { if (tmp.exists() && !tmp.delete()) { logger.error("Error while deleting temp file {}", tmp.getAbsolutePath()); } } mapStatus = MapStatus$.MODULE$.apply(blockManager.shuffleServerId(), partitionLengths); }
注意这里是一个Task的写入文件的过程,这个文件包含shuffleId和mapId;
写入过程为迭代当前partition的所有record,每个record先由新的partitioner(既然是shuffle肯定分区逻辑和之前不同,所以之前的1个partition会被分成多个partition)决定放到哪个partition,然后由partitionWriters(每个partition1个writer)写到相应分区的文件(每个partition1个file),每个partition都写完之后调用writePartitionedFile将所有分区文件合并成1个file,然后调用writeIndexFileAndCommit写索引文件,最后更新MapStatus,记录BlockManagerId和偏移位置信息;
MapStatus包含一个map过程的status,后边Reader读取shuffle数据时还会远程获取该信息,稍后会看到;
org.apache.spark.scheduler.MapStatus
private[spark] object MapStatus { def apply(loc: BlockManagerId, uncompressedSizes: Array[Long]): MapStatus = { if (uncompressedSizes.length > 2000) { HighlyCompressedMapStatus(loc, uncompressedSizes) } else { new CompressedMapStatus(loc, uncompressedSizes) } }
2.2 ShuffleManager.getReader方法
下面看BlockStoreShuffleReader
org.apache.spark.shuffle.BlockStoreShuffleReader
override def read(): Iterator[Product2[K, C]] = { val blockFetcherItr = new ShuffleBlockFetcherIterator( context, blockManager.shuffleClient, blockManager, mapOutputTracker.getMapSizesByExecutorId(handle.shuffleId, startPartition, endPartition), // Note: we use getSizeAsMb when no suffix is provided for backwards compatibility SparkEnv.get.conf.getSizeAsMb("spark.reducer.maxSizeInFlight", "48m") * 1024 * 1024, SparkEnv.get.conf.getInt("spark.reducer.maxReqsInFlight", Int.MaxValue)) // Wrap the streams for compression and encryption based on configuration val wrappedStreams = blockFetcherItr.map { case (blockId, inputStream) => serializerManager.wrapStream(blockId, inputStream) } val serializerInstance = dep.serializer.newInstance() // Create a key/value iterator for each stream val recordIter = wrappedStreams.flatMap { wrappedStream => // Note: the asKeyValueIterator below wraps a key/value iterator inside of a // NextIterator. The NextIterator makes sure that close() is called on the // underlying InputStream when all records have been read. serializerInstance.deserializeStream(wrappedStream).asKeyValueIterator } // Update the context task metrics for each record read. val readMetrics = context.taskMetrics.createTempShuffleReadMetrics() val metricIter = CompletionIterator[(Any, Any), Iterator[(Any, Any)]]( recordIter.map { record => readMetrics.incRecordsRead(1) record }, context.taskMetrics().mergeShuffleReadMetrics()) // An interruptible iterator must be used here in order to support task cancellation val interruptibleIter = new InterruptibleIterator[(Any, Any)](context, metricIter) val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) { if (dep.mapSideCombine) { // We are reading values that are already combined val combinedKeyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, C)]] dep.aggregator.get.combineCombinersByKey(combinedKeyValuesIterator, context) } else { // We don't know the value type, but also don't care -- the dependency *should* // have made sure its compatible w/ this aggregator, which will convert the value // type to the combined type C val keyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, Nothing)]] dep.aggregator.get.combineValuesByKey(keyValuesIterator, context) } } else { require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!") interruptibleIter.asInstanceOf[Iterator[Product2[K, C]]] } // Sort the output if there is a sort ordering defined. dep.keyOrdering match { case Some(keyOrd: Ordering[K]) => // Create an ExternalSorter to sort the data. Note that if spark.shuffle.spill is disabled, // the ExternalSorter won't spill to disk. val sorter = new ExternalSorter[K, C, C](context, ordering = Some(keyOrd), serializer = dep.serializer) sorter.insertAll(aggregatedIter) context.taskMetrics().incMemoryBytesSpilled(sorter.memoryBytesSpilled) context.taskMetrics().incDiskBytesSpilled(sorter.diskBytesSpilled) context.taskMetrics().incPeakExecutionMemory(sorter.peakMemoryUsedBytes) CompletionIterator[Product2[K, C], Iterator[Product2[K, C]]](sorter.iterator, sorter.stop()) case None => aggregatedIter } }
read时先创建ShuffleBlockFetcherIterator,这个类封装shuffle数据读取细节,构造函数中传入当前shuffleId对应的Array[MapStatus],然后这个类会屏蔽所有的读取细节,比如数据在本地磁盘,还是远程服务器;
上边提到最重要的信息是shuffleId对应的Array[MapStatus],这个是如何获取的?看MapOutputTracker
org.apache.spark.MapOutputTracker
protected val mapStatuses: Map[Int, Array[MapStatus]] ... /** * Get or fetch the array of MapStatuses for a given shuffle ID. NOTE: clients MUST synchronize * on this array when reading it, because on the driver, we may be changing it in place. * * (It would be nice to remove this restriction in the future.) */ private def getStatuses(shuffleId: Int): Array[MapStatus] = { val statuses = mapStatuses.get(shuffleId).orNull if (statuses == null) { logInfo("Don't have map outputs for shuffle " + shuffleId + ", fetching them") val startTime = System.currentTimeMillis var fetchedStatuses: Array[MapStatus] = null fetching.synchronized { // Someone else is fetching it; wait for them to be done while (fetching.contains(shuffleId)) { try { fetching.wait() } catch { case e: InterruptedException => } } // Either while we waited the fetch happened successfully, or // someone fetched it in between the get and the fetching.synchronized. fetchedStatuses = mapStatuses.get(shuffleId).orNull if (fetchedStatuses == null) { // We have to do the fetch, get others to wait for us. fetching += shuffleId } } if (fetchedStatuses == null) { // We won the race to fetch the statuses; do so logInfo("Doing the fetch; tracker endpoint = " + trackerEndpoint) // This try-finally prevents hangs due to timeouts: try { val fetchedBytes = askTracker[Array[Byte]](GetMapOutputStatuses(shuffleId)) fetchedStatuses = MapOutputTracker.deserializeMapStatuses(fetchedBytes) logInfo("Got the output locations") mapStatuses.put(shuffleId, fetchedStatuses) } finally { fetching.synchronized { fetching -= shuffleId fetching.notifyAll() } } } logDebug(s"Fetching map output statuses for shuffle $shuffleId took " + s"${System.currentTimeMillis - startTime} ms") if (fetchedStatuses != null) { return fetchedStatuses } else { logError("Missing all output locations for shuffle " + shuffleId) throw new MetadataFetchFailedException( shuffleId, -1, "Missing all output locations for shuffle " + shuffleId) } } else { return statuses } }
MapOutputTracker包含mapStatuses(所有shuffleId的MapStatus情况),初次调用时会初始化数据,过程为远程发送请求消息GetMapOutputStatuses(shuffleId),然后将结果放到mapStatuses;
3 总结
至此整个shuffle流程打通了,过程比较复杂,再重复一遍:
- 调用RDD.reduceByKey
- reduceByKey是transformation,返回ShuffledRDD,ShuffledRDD中会创建并返回ShuffleDependency,这时也创建了shuffleId,同时注册到了ShuffleManager
- spark执行任务时,DAGScheduler将ShuffleDependency转化为ShuffleMapStage,然后将ShuffleMapStage分解为ShuffleMapTask
- ShuffleMapTask会调用ShuffleManager.getWriter写数据,然后会更新MapStatus,写数据的过程是先按照新的分区逻辑写多个分区文件,然后合并成1个并写索引文件;
- reduceByKey下一步,无论是transformation或action(肯定后续有一个action会触发runJob然后才会有上述3和4的计算过程),都会调用RDD.compute获取分区数据,而ShuffledRDD的compute直接返回ShuffleManager.getReader
- ShuffleReader实现类BlockStoreShuffleReader在read时先远程获取当前shuffleId对应的所有MapStatus信息,然后通过ShuffleBlockFetcherIterator读取某个分区的shuffle数据;