1、查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断select * from people
where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最小的记录
delete from people
where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1)
3、查找表中多余的重复记录(多个字段)
select * from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
4、删除表中多余的重复记录(多个字段),只留有rowid最小的记录
delete from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
5、查找表中多余的重复记录(多个字段),不包含rowid最小的记录
select * from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
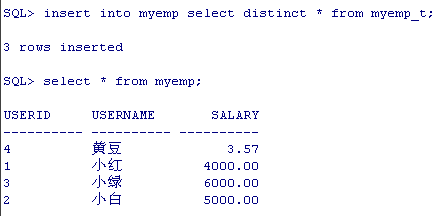
先看表myemp

查出有重复数据的记录

查出没有重复数据的记录

查出不重复的记录

或者
select * from myemp e where rowid = (select max(rowid) from myemp e2 where e.userid = e2.userid and e.username = e2.username and e.salary = e2.salary)
如何删除重复数据
1、 当有大量重复数据存在并且在列userid,username,salary上有索引的情况下
delete myemp where rowid not in (select max(rowid) from myemp group by userid,username,salary);
2、 适用于少量重复数据的情况(当有大量数据时,效率很低)
delete myemp e where rowid <> (select max(rowid) from myemp e2 where e.userid = e2.userid and e.username = e2.username and e.salary = e2.salary);
3、 exception方法,适合大量重复数据的情况
首先建立exception表
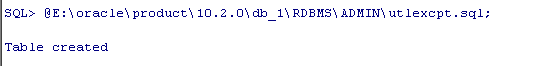
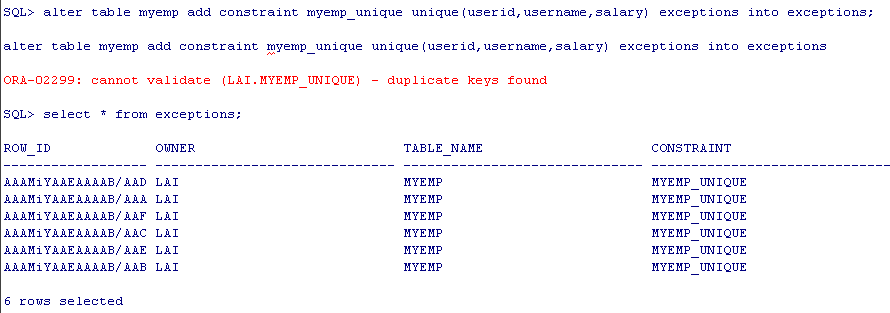
然后添加约束,将错误记录到表exceptions中
建立重复数据临时表

删除有重复的所有数据

将临时表中的非重复数据重新插入原表