写在前面
能把一件事情说的那么清楚明白,感谢廖雪峰的官方网站。
1.为什么要用混入类?(小白入门)
继承是面向对象编程的一个重要的方式,因为通过继承,子类就可以扩展父类的功能。
step1:
回忆一下Animal类层次的设计,假设我们要实现以下4种动物:
- Dog - 狗狗;
- Bat - 蝙蝠;
- Parrot - 鹦鹉;
- Ostrich - 鸵鸟。
step2:
如果按照哺乳动物和鸟类归类,我们可以设计出这样的类的层次:
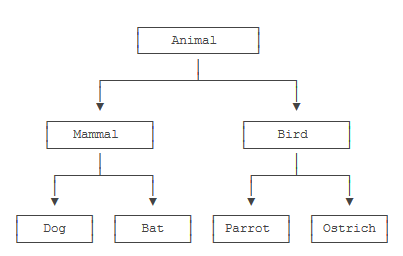
step3:
但是如果按照“能跑”和“能飞”来归类,我们就应该设计出这样的类的层次:
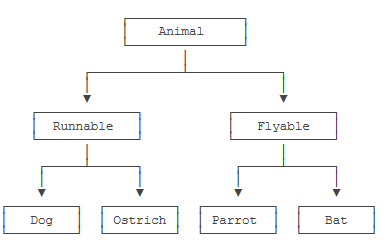
step4:
如果要把上面的两种分类都包含进来,我们就得设计更多的层次:
- 哺乳类:能跑的哺乳类,能飞的哺乳类;
- 鸟类:能跑的鸟类,能飞的鸟类。
这么一来,类的层次就复杂了:
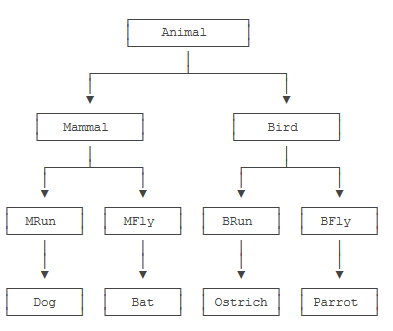
step5:
如果要再增加“宠物类”和“非宠物类”,这么搞下去,类的数量会呈指数增长,很明显这样设计是不行的。
step6:
正确的做法是采用多重继承。首先,主要的类层次仍按照哺乳类和鸟类设计:

2.MixIn混入类的的定义
在设计类的继承关系时,通常,主线都是单一继承下来的,例如,Ostrich继承自Bird。但是,如果需要“混入”额外的功能,通过多重继承就可以实现,比如,让Ostrich除了继承自Bird外,再同时继承Runnable。这种设计通常称之为MixIn。
MixIn的目的就是给一个类增加多个功能,这样,在设计类的时候,我们优先考虑通过多重继承来组合多个MixIn的功能,而不是设计多层次的复杂的继承关系。
Mix-in:混入类是一种Python程序设计中的技术,作用是在运行期间动态改变类的基类或类的方法,从而使得类的表现可以发生变化。可以用在一个通用类接口中。
混入类是为代码重用而生的。从概念上讲,混入不定义新类型,只是打包方法,便于重用。混入类应该提供某方面的特定行为,只实现少量关系非常紧密的方法并且混入类绝对不能实例化。
3.使用MixIn混入类有什么好处?
避免设计多层次的复杂的继承关系,混入类是为代码重用而生,使得代码结构简单清晰
4.MixIn继承关系
整个体系非常清晰,各个类的职责也非常明确,且类的职责从命名就可以读出。例如 ContextMixin 及其子类负责获取渲染模板所需的模板变量;MultipleObjectMixin 负责从数据库获取模型对应的多条数据;View 负责处理 HTTP 请求(如 get 请求,post 请求);TemplateResponseMixin 及其子类负责渲染模板。各个类组合在一起就构成了功能完整的 ListView。由此看出Django设计者充分采纳了一个类只负责一件事的设计理念(即单一责任原则),而且命名也是遵循一套统一的规范(...Mixin 后缀)。
继承关系

5.MixIn混入类的例子一
为了更好地看出继承关系,我们把Runnable和Flyable,Carvorous改为RunnableMixIn和FlyableMixIn,CarvorousMixIn
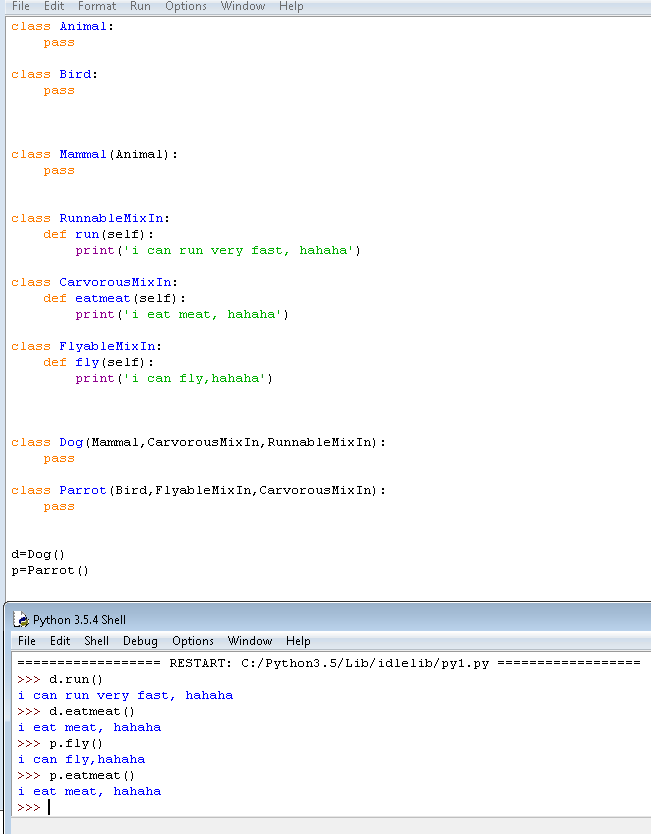
6.MixIn混入类的例子二
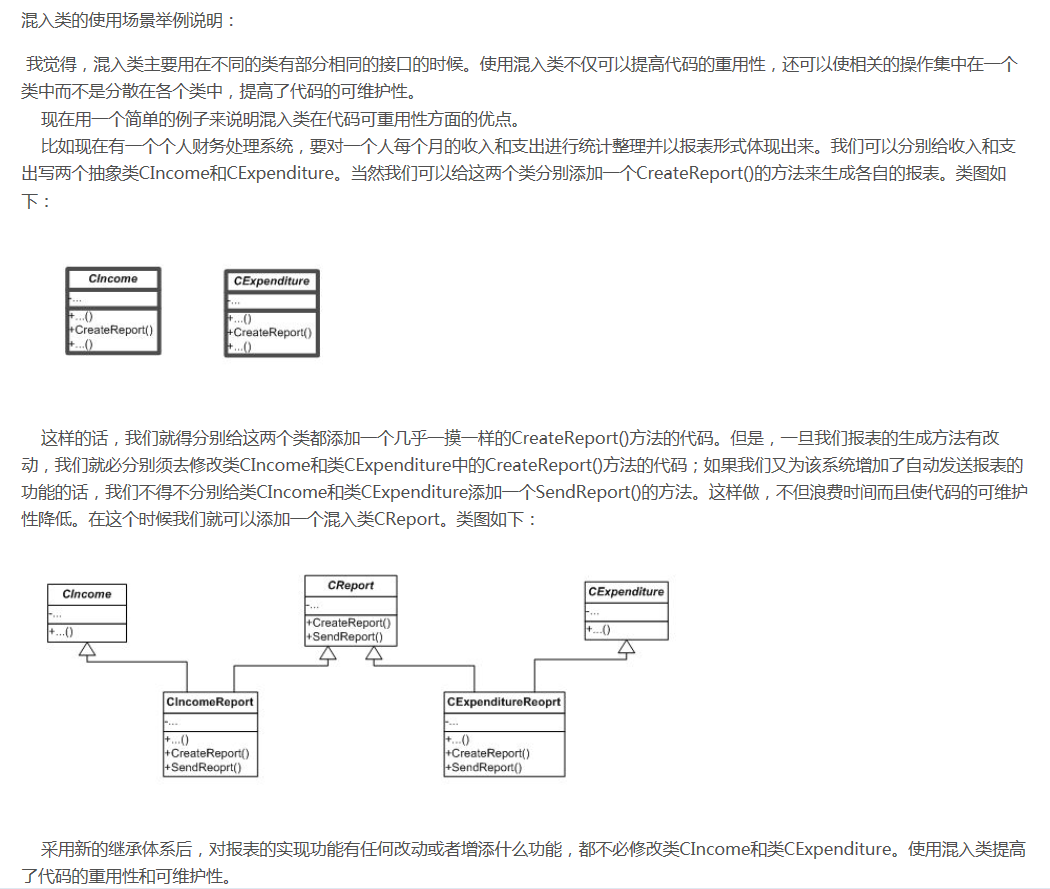

6.MixIn混入类的例子三
Python自带的很多库也使用了MixIn。举个例子,Python自带了TCPServer和UDPServer这两类网络服务,而要同时服务多个用户就必须使用多进程或多线程模型,这两种模型由ForkingMixIn和ThreadingMixIn提供。通过组合,我们就可以创造出合适的服务来。
比如,编写一个多进程模式的TCP服务,定义如下:
class MyTCPServer(TCPServer, ForkingMixIn):
pass
编写一个多线程模式的UDP服务,定义如下:
class MyUDPServer(UDPServer, ThreadingMixIn):
pass
如果你打算搞一个更先进的协程模型,可以编写一个CoroutineMixIn:
class MyTCPServer(TCPServer, CoroutineMixIn):
pass
这样一来,我们不需要复杂而庞大的继承链,只要选择组合不同的类的功能,就可以快速构造出所需的子类。
参考:
https://www.liaoxuefeng.com/wiki/1016959663602400/1017502939956896
https://www.cnblogs.com/ahMay/p/5707844.html
https://cloud.tencent.com/developer/news/221202
https://blog.csdn.net/zp357252539/article/details/82703246
http://python.tedu.cn/know/318527.html