1.初识Scrapy
Scrapy是为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或者存储历史数据等一系列的程序中。
2.选择一个网站
当需要从某个网站获取信息时,但该网站未提供API或者能通过程序获取信息的机制时,Scapy可以助你一臂之力。
3.定义想抓去的数据
在Scrapy中,通过Scrapy Items来完成的
import scrapy
class Torrent(scrapy.Item):
url=scrapy.Field()
name=scrapy.Field()
description=scrapy.Field()
size=scrapy.Field()
4.编写提取数据的Spider
编写一个spider来定义初始URL,针对后续链接的规则以及从页面中提取数据的规则
使用XPath来从页面的HTML源码中选择需要提取的数据
结合自己的内容给出spider代码,eg:
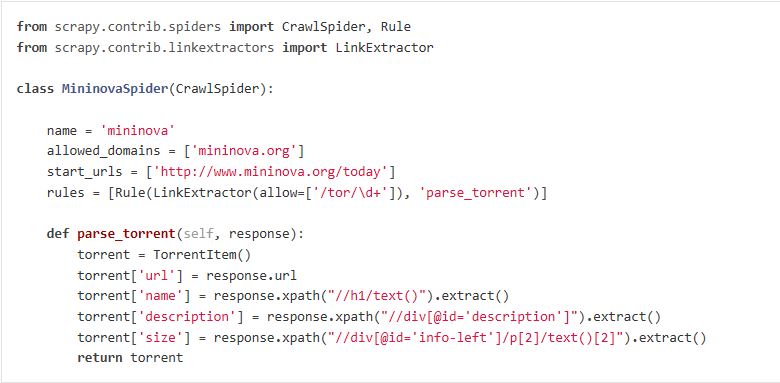
5.执行spider,获取数据
运行spider来获取网站的数据,并以JSON格式存入到文件中:
scrapy crawl mininova -o scraped_data.json
命令中使用了feed导出 来导出JSON文件,可以修改到处格式或者存储后端,同时也可以编写管道将item存储到数据库中。
6.查看提取到数据
执行结束后,查看scraped_data.json,将看到提取到的item
7.还有什么?
- Scrapy提供了很多强大的特性来使得爬取更为简单高效,例如:
- HTML,XML源数据选择及提取的内置支持
- 提供了一系列的spider之间共享的可复用的过滤器,对智能处理爬取数据提供了内置支持
- 通过feed导出提供了多格式(JSON,CSV,XML),多存储后端(FTP,S3,本地文件系统)的内置支持
- 提供了media pipeline,可以自动下载爬取到的数据中的图片(或者其他资源)
- 高扩展性,可以通过使用signals,设计好的API(中间件,exetensions,pipelines)来定制实现您的功能。
- 内置的中间件及扩展为下列功能提供了支持:
- cookies and session处理
- HTTP压缩
- HTTP认证
- HTTP缓存
- user-agent模拟
- robots.txt
- 爬取深度限制
- 其他
- 针对非英语系统中不标准或者错误的编码声明,提供了自动检测及健壮的编码支持
- 支持根据模板生成爬虫。在加速爬虫创建的同时,保持在大型项目中的代码更为一致
- 针对多爬虫性能评估,失败检测,提供了可扩展的状态收集工具
- 提供交互式shell终端,为测试XPath表达式,编写和调试爬虫提供了极大的方便
- 提供System service,简化在生产环境的部署及运行
- 内置Telnet终端,通过在Scrapy进程中钩入Python终端,可以查看并调试爬虫
- Logging在爬虫过程中捕捉错误提供了方便
- 支持Sitemaps爬取
- 具有缓存的DNS解析器