1.选一个自己感兴趣的主题。
2.网络上爬取相关的数据。
3.进行文本分析,生成词云。
4.对文本分析结果解释说明。
5.写一篇完整的博客,附上源代码、数据爬取及分析结果,形成一个可展示的成果。
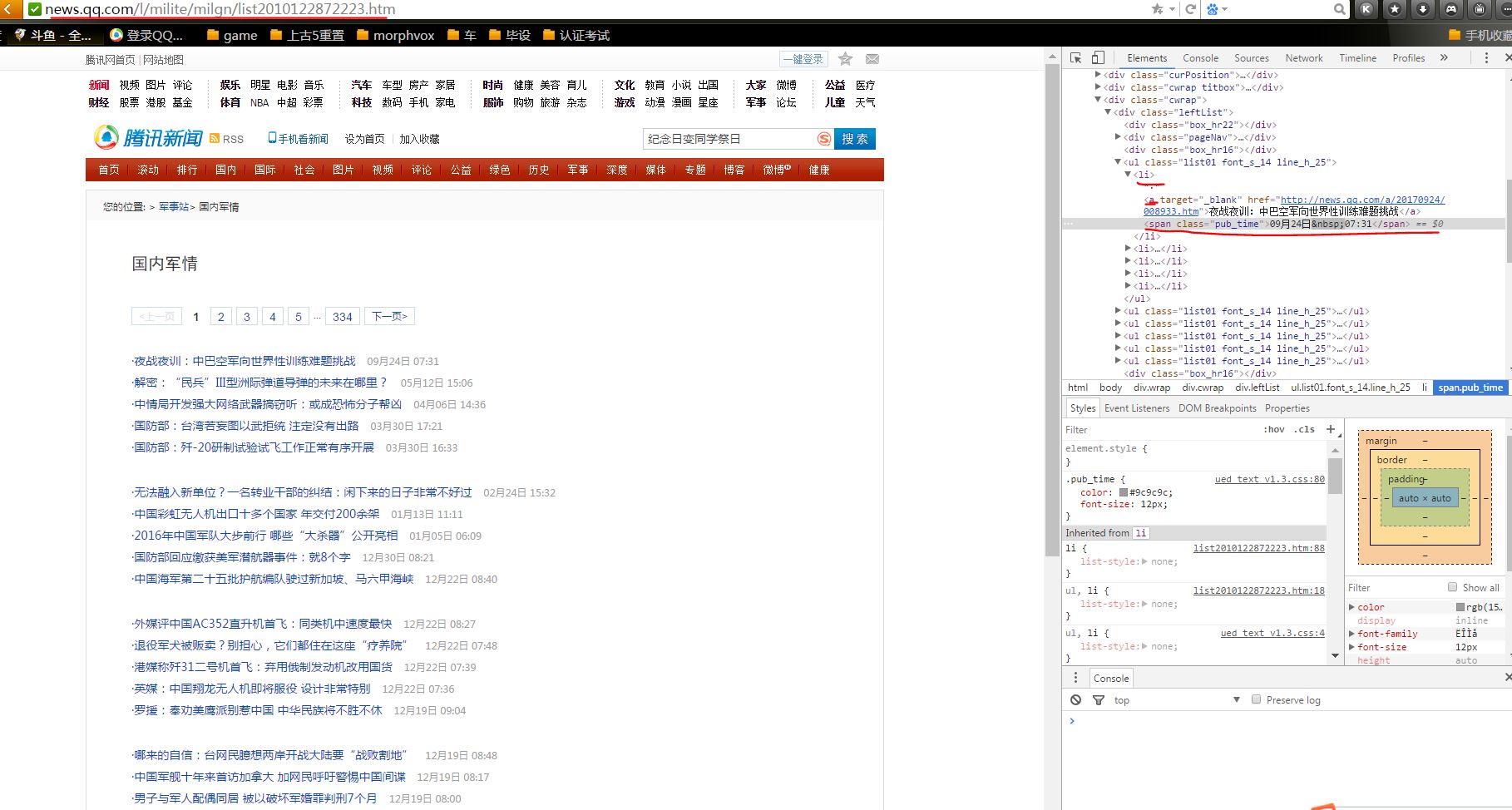
import requests from bs4 import BeautifulSoup import re import pandas from datetime import datetime import random from wordcloud import WordCloud import matplotlib.pyplot as plt url = 'http://news.qq.com/l/milite/milgn/list2010122872223.htm' list =[] def getListFullMarksArticle(url): res = requests.get(url) res.encoding = 'GBK' article0 = BeautifulSoup(res.text,"html.parser") articleList = {} for article in article0.select('.artbox_l'): list.append(getAllArticle(articleList,article)) def getAllArticle(articleList,article): articleList['URL'] = article.select('li')[0].select("a")[0]['href']#链接 articleList['TITLE'] = article.select("li")[0].select("a")[0].text#标题 articleList['DATE'] = article.select("li")[0].select("span")[0].text#日期 url= article.select('li')[0].select("a")[0]['href']#链接 title = article.select("li")[0].select("a")[0].text#标题 time = article.select("li")[0].select("span")[0].text#日期 print(' 标题',title,' 时间',time,' 链接',url) return(articleList) #循环总页数进行输出 for i in range(2,4): allUrl='http://news.qq.com/l/milite/milgn/list2010122872223_{}.htm'.format(i) getListFullMarksArticle(allUrl) #保存数据 df = pandas.DataFrame(list) df.to_excel('FullArticleList.xlsx') #制作词云 lo = open ('FullArticleList.xlsx','r',encoding='ISO-8859-1').read() #lo = open ('FullArticleList.xlsx','r','GBK').read() #lo = open ('FullArticleList.xlsx','r','GB2312').read() #lo = open ('FullArticleList.xlsx','r','ASCII').read() #lo = open ('FullArticleList.xlsx','r','ISO-8859-8').read() #lo = open ('FullArticleList.xlsx','r','ISO-8859-7').read() FullMarks = WordCloud().generate(lo) plt.imshow(FullMarks) plt.show()
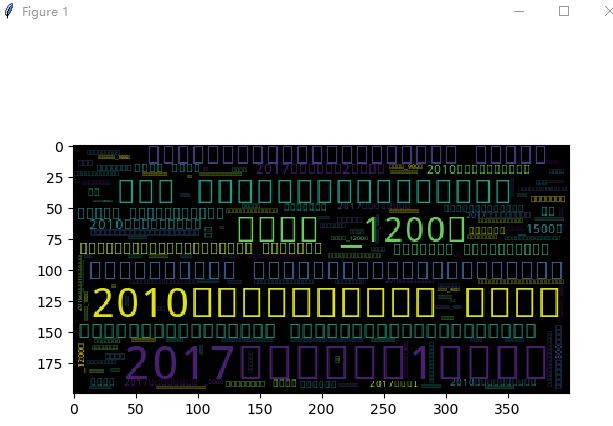
结果如下图所示:

由于未知原因,词云出现乱码。