文件和异常
学习处理文件和保存数据可让我们的程序使用起来更容易:用户将能够选择输入什么样的数据,以及在什么时候输入;用户使用我们的程序做一些工作后,可将程序关闭,以后再接着往下做。学习处理异常可帮助我们应对文件不存在的情形,以及处理其他可能导致程序崩溃的问题。这让我们的程序在面对错误的数据时更健壮 —— 不管这些错误数据源自无意的错误,还是源自破坏程序的恶意企图,以下学习的技能可提高程序的适用性、可用性和稳定性。
读写文件
在Python中实现文件的读写操作其实非常简单,通过Python内置的open函数,我们可以指定文件名、操作模式、编码信息等来获得操作文件的对象,文件名要带好路径(相对路径或绝对路径)并将文件模式设置为‘r’(默认值),通过encoding参数指定编码方式。在Python中实现文件的读写操作其实非常简单,通过Python内置的open函数,我们可以指定文件名、操作模式、编码信息等来获得操作文件的对象。
def main():
f = open('致橡树.txt', 'r', encoding='utf-8')
print(f.read())
f.close()
if __name__ == '__main__':
main()
如果open函数指定的文件不存在或者无法打开,就会引发异常状况导致程序崩溃。这时候需要使用python的异常机制对可能运行时发生状况的代码进行处理,如下:
def main():
f = None
try:
f = open('致橡树.txt', 'r', encoding='utf-8')
print(f.read())
except FileNotFoundError:
print('无法打开指定的文件!')
except LookupError:
print('指定了未知的编码!')
except UnicodeDecodeError:
print('读取文件时解码错误!')
finally:
if f:
f.close()
if __name__ == '__main__':
main()
try + 代码块+except+finally 的模式来处理异常。可以使用多个except来指定可能引发的异常错误,最后加上finall代码块来关闭打开的文件,释放掉程序中获取的外部资源,由于finally块的代码不论程序正常还是异常都会执行到,因此我们通常把finally块称为“总是执行代码块”,它最适合用来做释放外部资源的操作。如果不愿意在finally代码块中关闭文件对象释放资源,也可以使用上下文语法,通过with关键字指定文件对象的上下文环境并在离开上下文环境时自动释放文件资源,代码如下所示:
def main():
try:
with open('致橡树.txt', 'r', encoding='utf-8') as f:
print(f.read())
except FileNotFoundError:
print('无法打开指定的文件!')
except LookupError:
print('指定了未知的编码!')
except UnicodeDecodeError:
print('读取文件时解码错误!')
if __name__ == '__main__':
main()
以上是一次全部读取文件内容,如果要分行多次读取可以使用for-in或者readlines方法读取到一个列表容器中,代码如下:
import time
def main():
# 一次性读取整个文件内容
with open('致橡树.txt', 'r', encoding='utf-8') as f:
print(f.read())
# 通过for-in循环逐行读取
with open('致橡树.txt', mode='r') as f:
for line in f:
print(line, end='')
time.sleep(0.5)
print()
# 读取文件按行读取到列表中
with open('致橡树.txt') as f:
lines = f.readlines()
print(lines)
if __name__ == '__main__':
main()
说了读文件,写文件也很简单,在使用open函数时:文件名并加上文件模式即可,w表示写,a表示追加写入,如果文件不存在,会自动创建该文件而不会引发异常。读写二进制文件也很简单,文件模式选择wb或者rb即可实现对图片的复制功能。如下:将1~10000中的素数分别写在三个文件中:
from math import sqrt
def is_prime(n):
"""判断素数的函数"""
assert n > 0
for factor in range(2, int(sqrt(n)) + 1):
if n % factor == 0:
return False
return True if n != 1 else False
def main():
filenames = ('a.txt', 'b.txt', 'c.txt')
fs_list = []
try:
for filename in filenames:
fs_list.append(open(filename, 'w', encoding='utf-8'))
for number in range(1, 10000):
if is_prime(number):
if number < 100:
fs_list[0].write(str(number) + '\n')
elif number < 1000:
fs_list[1].write(str(number) + '\n')
else:
fs_list[2].write(str(number) + '\n')
except IOError as ex:
print(ex)
print('写文件时发生错误!')
finally:
for fs in fs_list:
fs.close()
print('操作完成!')
if __name__ == '__main__':
main()
读写Json文件
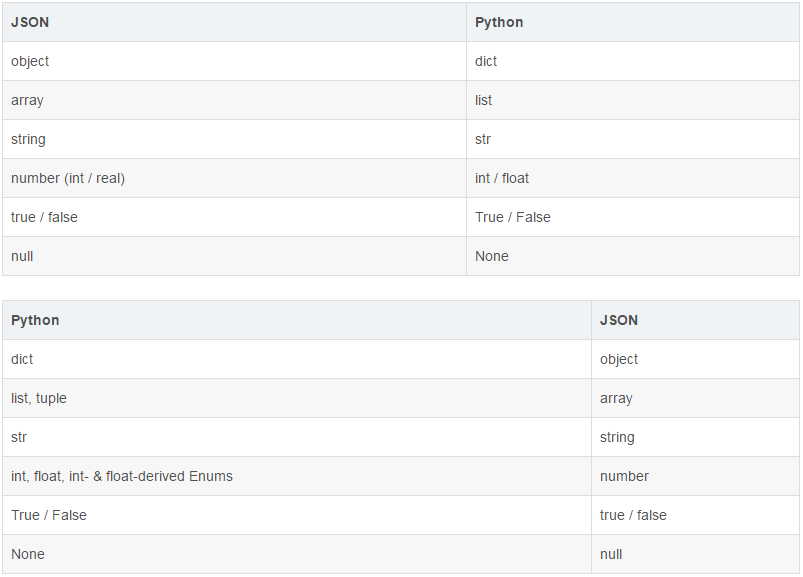
除了读写文本文件,现实中我们经常会处理将一个列表或者字典里面的数据保存到文件中的情况,这时候需要用JSON格式。JSON(JavaScript Object Notation”)现在已经被广泛的应用于跨平台跨语言的数据交换,原因很简单,因为JSON也是纯文本,任何系统任何编程语言处理纯文本都是没有问题的。目前JSON基本上已经取代了XML作为异构系统间交换数据的事实标准。JSON和python中的数据类型很容易找到对应关系,如下表:
接下来我们会从网上扒图片,使用python中的json和requests模块(python爬虫常用模块)。这个例子使用了天行数据提供的it图片数据接口,其中的APIKey需要自己到该网站申请。
import requests
import json
def main():
#每次只能扒10张图
resp = requests.get('http://api.tianapi.com/it/?key=APIKey&num=10')
#loads - 将字符串的内容反序列化成Python对象
#dump - 将Python对象按照JSON格式序列化到文件中
#dumps - 将Python对象处理成JSON格式的字符串
#load - 将文件中的JSON数据反序列化成对象
my_dict = json.loads(resp.text)
#遍历mydict里面我们需要的键值对,取需要的值
for tempdict in mydict['newslist']:
pic_url = tempdict['picUrl']
resp = requests.get(pic_url)
#对字符串切片得到图片文件名
filename = pic_url[pic_url.rfind('/')+1:pic_url.rfind('?')]
try:
with open(filename, 'wb') as fs:#以二进制方式写入
fs.write(resp.content)
except IOError as e:
print(e)
if __name__ == '__main__':
main()