自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取:
https://www.cnblogs.com/bclshuai/p/11380657.html
1.1 RNN循环神经网络(recurrent neural network)
1.1.1 RNN简介
RNN循环神经网络会循环的加入上一时刻的状态作为输入,得出下一时刻的输出。解决的是具有时序关联性的问题,例如股票趋势预测,需要上一时刻的股票价格输入作为下一时刻的输出,又比如输入预测,当你输入I am studen时,神经网络会根据你前面的输入推断出下一时刻你会输入t。而卷积神经网络处理的输入之间没有关联关系,例如手写数字识别例子中,各个手写数字没有任何时间上的关联性。
1.1.2 循环神经网络结构

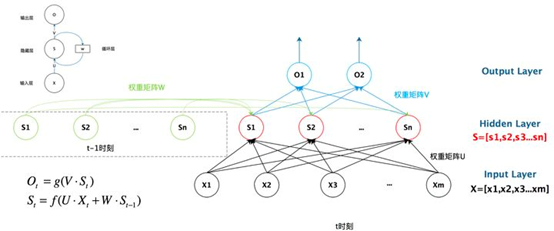
从一个简单的图弄清楚循环神经网络的结构和概念,如上图所示。
x输入层,s是隐藏层,o是输出层,u是输入层到隐藏层的参数,v是隐藏层到输出层的参数,循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵w就是隐藏层上一次的值作为这一次的输入的权重。上图左边的圆圈表示的就是循环的概念。如果将循环神经网络按照时间序列展开,就是上图右侧所示,下一刻输出和前面的所有的输入和状态都建立起了关联性,这就是循环神经网络能处理时序性问题的原因。
用公式表示循环神经网络的结构如下:

式1是输出层的计算公式,输出层是一个全连接层,也就是它的每个节点都和隐藏层的每个节点相连。V是输出层的权重矩阵,g是激活函数。式2是隐藏层的计算公式,它是循环层。U是输入x的权重矩阵,W是上一次的值作为这一次的输入的权重矩阵,f是激活函数。循环层和全连接层的区别就是循环层多了一个权重矩阵 W。
如果将公式(2)带入公式(1)中,并且不断的循环展开,会发现公式展开和图片中按照时间序列展开有异曲同工之妙。这也是为什么循环神经网络关联前面所有输入和状态的原因。

概念理解了,公式也明白了。循环神经网络不是像上图那样输入、隐藏、输出都是一个节点那样简单,而是一个网络。S是由多个节点组成的隐藏层。
参考文献:
https://zhuanlan.zhihu.com/p/30844905
https://zybuluo.com/hanbingtao/note/541458
1.1.3 tensorflow实现循环神经网络源码实例
将网上的一段英文先获取英文中所有的字符,然后将字符进行编码,然后再将将英文转码位数字,对数字进行抽样,随机抽取1000个连续的50个字符,送入循环神经网络RNN进行训练,让设计网络具有一定的语言记忆功能,然后再让循环神经网络去预测输出一段话。具体实现步骤如下:
(1) 从亚马逊的网站读取一个文本 ,里面是一段英文,获取英文的无重复字符集;将字符集进行排序、数字编码(0,n);并且定义抽取连续长度的字符串接口;
(2) 定义循环神经网络模型,,初始化init函数中定义循环层,全连接层。call函数中定义层的组合连接。predict函数定义预测输出结果;
(3) 随机抽取连续的字符串输入神经网络进行训练,用梯度下降法优化模型参数;
(4) 将训练好的模型用于字符预测,随机抽取长度为40的字符,输入训练好的模型预测出下一个字符,然后再将抽取的字符后面39个,和预测的字符组合成新的40个字符输入模型进行预测,依次循环,输出预测的50个字符。
代码实例
import tensorflow as tf import numpy as np import matplotlib.pyplot as plot class Daataloder: def __init__(self): #下载文件 path=tf.keras.utils.get_file('nietzsche.txt',origin="https://s3.amazonaws.com/text-datasets/nietzsche.txt") #打开文件 with open(path,encoding='utf-8') as f: #读取文件,并且将字符全部转换为小写,这是一段英文 self.raw_text=f.read().lower() #去除换行符 self.raw_text=self.raw_text.replace(' ','') self.raw_text_len=len(self.raw_text) #先转换为set去除重复的字符,然后在转为list进行升序排序 self.chars=sorted(list(set(self.raw_text))) self.chars_len=len(self.chars) #遍历字符,获取字符到索引的字典映射 self.chars_index=dict((c,i) for i,c in enumerate(self.chars)) self.chars_index_len=len(self.chars_index) # 遍历字符,获取索引到字符的字典映射 self.index_char=dict((i,c) for i,c in enumerate(self.chars)) #将文本按照chars_index数据字典映射为数字 self.text=[self.chars_index[c] for c in self.raw_text] self.textlen=len(self.text) def get_batch(self,seq_length,batch_size): seq=[] next_char=[] for i in range(batch_size): #随机产生一个索引 index=np.random.randint(0,len(self.text)-seq_length) #在self.text中截取起始索引为index的,长度为seq_length的数组 seq.append(self.text[index:index+seq_length]) #将截取的数据的下一个字符作为正确的字符标签,要和训练的预测数据结果做对比 next_char.append(self.text[index+seq_length]) #seq大小是[batch_size,seq_length].next_char大小是[batch_size] return np.array(seq),np.array(next_char) class RNN(tf.keras.Model): def __init__(self,num_chars,batch_size,seq_length): super().__init__() self.num_chars=num_chars#字符集中字符数量 self.batch_size=batch_size#训练数据的数量 self.seq_length=seq_length#一批训练数据的大小 #定义一个循环层,长短期记忆网络(LSTM,Long Short-Term Memory)是一种时间循环神经网络 self.cell=tf.keras.layers.LSTMCell(units=256) #定义一个全连接层 self.dence=tf.keras.layers.Dense(units=self.num_chars) def call(self,inputs,from_logits=False): # #one_hot是将一维数组转化为对应元素值对应的位置为1,其余都为0二维数组,例如[1,2,3,4],depth=5,转化为4行5列的矩阵 # [[0. 1. 0. 0. 0.] # [0. 0. 1. 0. 0.] # [0. 0. 0. 1. 0.] # [0. 0. 0. 0. 1.]] #print(inputs)#shape=(50, 40) inputs=tf.one_hot(inputs,depth=self.num_chars) #print(inputs)#shape=(50, 40, 56) #获取初始的状态 state=self.cell.get_initial_state(batch_size=self.batch_size,dtype=tf.float32) #将长度为40的字符串(数字转码)一个个的传入循环层,得出最后的结果 for t in range(self.seq_length): #print(inputs)#shape=(50, 40, 56) #print(inputs[:,t,:])# shape=(50, 56) output,state=self.cell(inputs[:,t,:],state) #print(output)# shape=(50, 56) #print("state:") #print(state)# shape=(50, 56) #用全连接层去处理output,输出预测字符 logits=self.dence(output)## shape=(50, 56),50组数据,每组输出的字符对应字符集中的 if from_logits: return logits#非训练时,返回数组,用概率分布去抽样,增加文本丰富性 else: return tf.nn.softmax(logits)#训练的时候用概率最大的 def predict(self,inputs,temprrature=1.): #用模型输出概率数组 batch_size,_=tf.shape(inputs) #用模型输出概率数组 logict=self(inputs,from_logits=True) #用temprrature控制概率分布图形状, 越大概率分布越平缓,各个值的概率越接近,生成的文本越丰富 #softmax则是归一化,数组中所有值除以和,值范围0-1,值总和为1 prob=tf.nn.softmax(logict/temprrature).numpy() #按照概率分布随机抽取一个字符作为预测的下一个字符,概率越大的抽中越大,概率小的也有可能被抽中,增加输出结果丰富性 return np.array([np.random.choice(self.num_chars,p=prob[i,:]) for i in range(batch_size.numpy())]) #定义超参数 num_batch=1000#数据的训练次数 seq_length=40#一组数据的长度 batch_size=50#数据的组数 learning_rate=0.001#学习率 data_loader=Daataloder()#创建数据加载对象 #创建模型对象 model=RNN(num_chars=len(data_loader.chars),batch_size=batch_size,seq_length=seq_length) #创建参数优化器 opimister=tf.keras.optimizers.Adam(learning_rate=learning_rate) #保存每次训练的误差用于画图 arryindex=np.arange(num_batch) arryloss=np.zeros(num_batch) for index in range(num_batch): #随机获取数据 x,y=data_loader.get_batch(seq_length,batch_size) with tf.GradientTape() as tape: #通过模型预测数据 y_pred = model(x) #和标签数据计算误差 loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred) #计算梯度 grads=tape.gradient(loss,model.variables) loss=tf.reduce_mean(loss) arryindex[index]=index arryloss[index]=loss print("batch %d :loss%f" % (index,loss)) #更新参数 opimister.apply_gradients(grads_and_vars=zip(grads,model.variables)) #画出训练误差随训练次数的图片图 plot.plot(arryindex,arryloss,c='r') plot.show() X_,_=data_loader.get_batch(seq_length,1) for diversity in[0.2,0.5,1.0,1.2]: X=X_ print(diversity) for s in range(seq_length): index=X_[0,s] print(data_loader.index_char[index], end='', flush=True) for t in range(50): #X为是从文章中随机获取的一个长度为40的一维数组 y_pred=model.predict(X,diversity) print(data_loader.index_char[y_pred[0]],end='',flush=True) #一维数组,一个数据变成1*1的二维 张量 y_pred=np.expand_dims(y_pred,axis=1) #取X中后面39个字符,加上预测出的字符,连接成新的40个字符,继续输入得出下一字符 X=np.concatenate([X[:,1:],y_pred],axis=-1)#第一个冒号表示所有行,第二个1:表示从第一个起后面所有的字符 # print(X) print(" ")
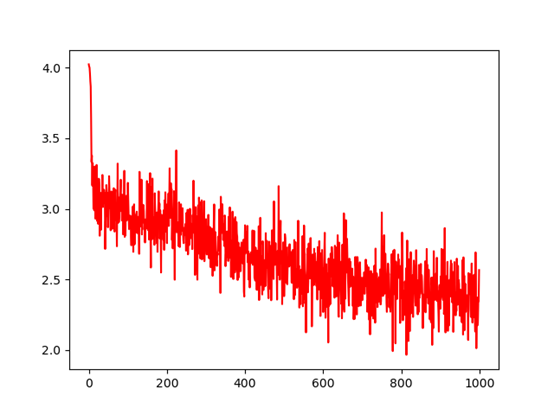
训练的误差曲线图
不同的参数temperature,相同的训练模型,相同的输入字符串,不同的输出的结果如下,前40个字符是随机抽取文本中一段连续的文本,后面的50个字符是用循环网络依次预测出的字符,参数temperature越小,概率分布曲线图越陡峭,概率最大的字符输出的概率也越大,输出的文本丰富性低。预测的文本没有啥含义,说明升级网络模型还是需要优化。
0.2
nish the anti-semitic bawlers out of the sore the the the and the the the the the the the
0.5
nish the anti-semitic bawlers out of the mon the ment ond the mond the the as and os ins o
1.0
nish the anti-semitic bawlers out of thenvoun serti; gficej)ingatresmors po sy the komnmos
1.2
nish the anti-semitic bawlers out of the hit asd phith"rorydyrtlingeree.e -om thol fof inm