机器学习解决的问题是对于任意输入一个数据,我们能够预测出它的输出。我们已知的条件是一组输入数据和与之对应的真实输出。需要根据这些数据学习出一个模型,那么对于一个任意测试输入data1,输入到这个模型中会有一个结果y'。我们用已知数据通过这个模型预测出来的结果与真实结果之间的误差来更新模型,直到误差足够小。
例一:实现一个房屋售价的评定模型。
假设房屋的价格由屋子的面积,地段,朝向这三个特征决定。当给一个房子的面积地段和朝向时,如何预测房屋的售价。
我们需要一些先验知识,已知一组数据:房屋的面积,地段,朝向,以及所对应的房子的售价。
根据这些数据,建立一个模型,假设房屋的三个特征与房屋售价是线性关系。用x1表示房屋的面积特征,x2表示房子所处的地段,x3表示房子的朝向,相应的权重分别设为θ1,θ2,θ3。那么房屋的售价预测值y'=x1*θ1+x2*θ2+x3*θ3;
用已知数据来训练模型,将所有已知的房屋特征输入到模型中,得到的预测值y'与真实值y之间的误差和为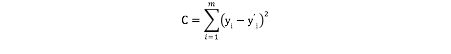
这个误差和称为损失函数。下一步就是求出使得损失函数最小的θ1,θ2,θ3的值。
由损失函数求出θ1,θ2,θ3的值的方法很多,如果损失函数最小值对应的θ1,θ2,θ3有解析解,那么直接求取解析解。如果没有解析解,需要通过优化算法求出使得损失函数最小时的参数值。常见的算法如梯度下降法,牛顿法等。
用梯度下降法优化过程如下:
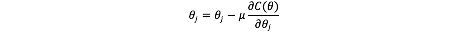
例二:实现鸡蛋和鸭蛋的分类
假设根据蛋的颜色,重量特征可以判断是鸡蛋还是鸭蛋。当给出一个蛋的颜色和重量特征,如何判断它是鸡蛋还是鸭蛋?
同样的我们已知一组蛋的颜色和重量数据,以及其对应的类别。
根据这些数据我们建立一个模型。假设用概率p(y|x)表示根据特征x预测的结果与真实结果y的相同的概率。
将所有的已知的蛋的特征和其对应的分类数据输入到模型,得到该模型对所有已知数据的预测值与真实值之间的相似度的乘积。

假设概率模型p(y=1|x)=hθ(x),p(y=0|x)=1-hθ(x)。 那么p(y|x)=hθ(x)y*(1-hθ(x))1-y。hθ(x)为逻辑函数,值在0~1之间。
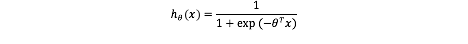
至此模型已经建好,那么需要求出当所有已知数据的预测值与真实值之间的概率达到最大时的模型参数θ。
求解函数L最大值所对应的θ的过程依旧是一个最优化的过程,可以用梯度下降法来求解模型参数θ。因为L(θ)上任意一点沿着梯度方向的变化率最快,因此用L(θ)的梯度不断更新θ。优化过程如下:
为了求解方便,将L(θ)进行log,l(θ)=log(L(θ))=∑p(y|x)
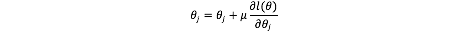
生成学习算法:
判别学习算法是直接建立模型P(y|x),用已知数据对该模型进行训练(如逻辑回归),或者直接学习从输入到输出的映射关系(如感知算法)。
而生成学习是从另一个角度,根据贝叶斯公式,P(y|x)=P(x|y)*P(y)/P(x),因此生成学习算法先建立P(x|y)与P(y)模型。
生成学习算法依旧是解决给出一个输入,就可以预测出输出的问题。首先提取可以进行目标分类的代表性特征,用向量x表示。
因为P(y|x)=P(x|y)*P(y)/P(x),而最后根据一个输入,预测输出时,是根据arg max p(y|x)=arg max P(x|y)*P(y)/P(x)=arg max P(x|y)*P(y)。因此不需要考虑P(x),只需要建立模型P(x|y)与P(y)。
我们用已知的数据和真实输出值来训练该模型,将已知特征数据输入到模型中,得到所有的输入与真实输出之间的相似程度的乘积。即目标函数:

下一步就是求出使得该损失函数最大时的参数值。是一个优化的过程,与前面优化相同。
例三:以垃圾邮件为例,接收到一封邮件,判断该邮件是否是垃圾邮件?
首先提取目标特征,我们用邮件的标题中单词内容来判断是否是垃圾邮件。建立一个词汇表,包含了很多可能出现的单词,用一个特征向量x表示输入的邮件,x=[x1,x2,x3,x4,...,xn],向量的长度n为词汇表中单词数目。向量中的每个xi的取值为0表示词汇表中的第i个单词在邮件标题中没有出现,取值为1表示词汇表中的第i个单词出现在邮件标题中。因此对于每封邮件都可以用一个长度为n的向量表示。对于输出y=0表示是垃圾邮件,y=1表示不是垃圾邮件。
接着建立模型,假设用概率p(y|x)表示根据特征x预测的结果与真实结果y的相同的概率。使用生成学习的方法,我们先建立模型p(x|y=0),表示垃圾邮件的输入特征的分布,建立模型p(x|y=1)表示非垃圾邮件的输入特征的分布。以及p(y)表示邮件的垃圾与非垃圾的分布情况。
在这里当y=0时,输入向量x有2n可能,如果直接考虑y=0时的输入x的分布,会是一个多项式分布,参数是2n-1个。
因此我们假设输入向量x=[x1,x2,x3,x4,...,xn]中xi的取值是相互独立的。那么p(x|y=0)=p(X1=x1,X2=x2,...,Xn=xn|y=0)=∏i=1~np(X=xi|y=0),假设对于输入向量x中的每一个p(Xi=xi|y=0)都服从伯努利分布,xi|y=0 ~ Bermoulli(Φi|y=0)。
同样的输入向量x中的每一个p(Xi=xi|y=1)都服从xi|y=1 ~ Bermoulli(Φi|y=1)。y也服从Bermoulli(Φy)分布。
p(x|y=0)=∏i=1~n (Φi|y=0)xi(1-Φi|y=0)1-xi
p(x|y=1)=∏i=1~n (Φi|y=1)xi(1-Φi|y=1)1-xi
p(y)=(Φy)y(1-Φy)1-y
根据已知的邮件标题特征与是否为垃圾邮件的情况输入到模型中,对模型进行训练,得到所有已知邮件的预测结果与真实结果之间的相似程度的乘积:
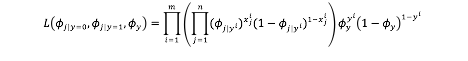
最后需要求出使得L最大时的模型参数Φi|y=0,Φi|y=1,Φy的值。这是一个优化的过程,此时可以直接进行L对Φi|y=0,Φi|y=1,Φy分别求偏导数,分别令偏导数为0,求得解析解。
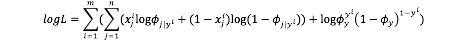
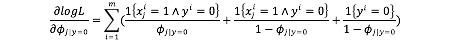
令上式偏导式=0,求得

用同样的方法求得Φi|y=1,Φy的解析解:
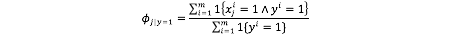

至此如果接收到一封邮件,分别计算p(y=0|x)=P(x|y=0)*P(y=0)/P(x)和p(y=1|x)=P(x|y=1)*P(y=1)/P(x)两种情况的概率大小,从而判定邮件是否是垃圾邮件。