Linux
Linux的文件结构
/bin //二进制文件目录,所有Linux版本公有的命令
/sbin //二进制文件目录
/dev //device,设备目录,光驱、磁盘、分区
/etc //配置文件目录,Environment Config
/lib //库文件,共享对象文件(SO--Shared Object,等价于windows dll文件)
/home //主目录,里面有很多用户目录,如:/home/ubuntu,但root用户目录位于/root下。
/media
/mnt
/opt
/root //root用户目录
/usr //不同Linux厂商的目录
/usr/bin //Linux厂商的可执行文件目录,/usr/bin/apt-get
/usr/sbin //Linux厂商的可执行文件目录
/usr/local //用户目录
/usr/local/bin //用户命令存放的目录
/usr/local/sbin //用户命令存放的目录
Linux常用的命令
xxx --help(或-h) //查看帮助
man ls //查看ls命令的帮助
info ls //查看ls命令的帮助
help <内置命令> //查看内置命令的帮助
cd //改变目录
ls //列出文件
ls -al | more //a表示all:即列出所有.开头文件,等价于隐藏文件;滚动屏幕查看,空格翻屏,q退出
clear //清屏
whoami //查看当前用户
which //查看可执行文件的位置
echo $PATH //显示文本
pwd //显示当前路径
sudo <command> //以root的权限去操作
sudo mkdir dir1
sudo passwd //设置root用户的密码。
su root //切换root用户,只有设置root用户密码后才能切换root用户.
ifconfig //查看ip地址 相当于window中的ipconfig
find //find <路径> 以树形结构显示该路径所有的目录及其子目录,类似于windows的tree命令。
mkdir //创建目录 mkdir -p a/b -p parent如果父目录不存在,还递归创建父目录
rm //删除目录 rm -rf a/b -r recursive递归 -f force强制
touch //创建空文件 touch hello.txt
echo //echo hello,world > hello.txt 将显示的内容覆盖的形式写入到hello.txt中。
//echo hello,world >> hello.txt 将显示的内容追加的形式写入到hello.txt中。
cat //cat hello.txt 查看文件内容
cp //拷贝文件 -r recursive 递归 eg:cp b/c/d.txt ../
mv //移动或重命名
head //显示前10行 eg:head -n 3显示前3行
tail //显示后10行
hostname //查看主机名
hostname //显示主机名 vi /etc/hostname 修改主机名
reboot //重启
shutdown //关机 -P:Power off -r:reboot now:立刻执行
halt //halt -p 关机
uname //打印系统内核信息 uname -a
file //查看文件类型 file <文件名> eg: file /lib/xxx.so.0.0.0 so为共享对象文件,类似于windows dll文件。
tar 归档
类型:
war:web archive file
ear:enterprise archive file
jar:java archive file
参数:
-c:create创建归档
-f:file指定文件
-v:verbose显示详细信息
-x:extract解档
-z:gzip通过gzip进行过滤
-t:查看归档文件
-r:追加文件
tar -zxvf mytar.tar.gz
gzip //压缩
-d:decompress解压缩
-1:faster快速压缩
-9:better高压缩率
gunzip //解压缩
xargs //将管道输出的内容合并成一行数据,使用空格分隔。
$>find . | grep txt | cp `xargs' kk //将当前目录下所有txt的文件复制到kk目录下。
``是按命令进行输出,如:echo `hostname`
mount //挂载
mount /dev/cdrom /mnt/cdrom //挂载光驱到/mnt/cdrom下
umount /dev/cdrom //解除挂载
ln //链接
1.硬链接:根据源文件创建一个副本,源文件内容改变,副本也改变,且和源文件占用同样的磁盘空间。但删除源文件,副本却不会删除。如:ln hello.txt hello.txt.ln
2.符号链接:ln -s how.txt how.txt.ln,//-s:symbolic,符号链接相当于快捷方式。
jobs //显示作业
kill //杀死作业
//kill %1 杀死1号作业
ps //显示进程 process show
//-a : all -f:full
ps -af //查看所有进程的完整信息
cut //剪切字符
cut -c 3-6 hello.txt //从hello.txt的第3个字符开始截取到第6个。
fdisk //查看磁盘包括分区
fdisk -l /dev/sda
df //disk free查看磁盘使用情况
df -ah //-a:all -h:human人性化显示
dirname //查看文件所有目录
eg:dirname /bin/cp # /bin
basename //输出文件的基本名称(去除目录的部分)
eg:basename /home/ubuntu/how.txt .txt //how
eg:basename /home/ubuntu/data //data
netstat -ano | grep 8088 //查看网络连接信息
$(command)
eg:$>echo $(hostname) //echo `hostname`
cd -P (P:Physical)进入物理目录,而不是链接目录
$>ln -s /bin mybin
$>cd mybin //:mybin$
$>cd -P mybin //:bin$
echo $PATH //或echo ${PATH} 或echo "$PATH"
export //导入环境变量
eg:export MYPATH=/home/ubuntu //只在当前会话中有效,重启后就丢失。
eg:export MYPATH=${PATH}:/home/ubuntu //拼接
eg:export YOURPATH=${PATH-$MYPATH} //如果PATH变量不存在,就取$MYPATH
if <命令>; then <命令>; elif <命令>;...else <命令>; fi
eg:if rm b; then echo ok; else echo error; fi
Linux内置变量的访问方式
1.$?:返回刚刚执行命令的结果,0表示成功,非0表示失败
2.$#:表示获取参数的个数 eg:rm -r bin //$# 2(含bin)
eg:if[$# -gt 1]
3.$n:表示取第n个参数
4.$@:表示所有参数
5.shift:表示向左移动参数,左边的参数被覆盖掉。
命令组合
1.a && b //a执行成功后再执行b
2.a || b //a执行失败后再执行b
3.a ; b //a执行后再执行b
4.(a ;b) //只在当前目录下执行,不切换目录
NetCat //美其名日,瑞士军刀
1.tcp/ip:
socket编程
Server socket //server,listener,port
Socket //connection,port
2.nc命令
$>nc -l 8888 & //开启本机(服务器端)的套接字(ServerSocket)进程,&表示在后台运行,-l:listener
$>nc localhost 8888 //启动客户端,连接到服务器的端口8888
hello,world. //客户端发送信息
^z //ctrl+z暂停当前进程并放入后台,变成作业(job)了。ctrl+d结束任务
s>jobs //查看作业,重点查看作业编号
$>bg %1 //将编号为1的后台作业激活
$>fg %1 //将编号为1的作业切换到前台
传送文件
服务端:nc -l 1234 > readme2.txt //重定向接收数据到文件
客户端:nc localhost 1234 < readme1.txt //从定向输入
端口扫描
nc ip -z port1-port2 //指定要扫描的ip和端口区间
nc -v -w 2 s1 -z 2000-4000
-v:详细信息
-w:连接超时
-z:扫描端口
文件和权限
1.文件类型
d:directory
-:文件
b:block 块设备
l:link 链接文件
2.权限
user(owner) 用户
group 用户组 //Linux用户可以隶属于多个组,但是有一个首要组(primary group)
other 其他
all 所有 ugo
3.控制权限
r:read //如果是文件,读是指查看文件内容。对于文件夹,读是指查看文件夹包含的资源。
w:write //如果是文件,写是指修改文件内容;对于文件夹,是指创建文件或删除文件。
x:execute //是指可执行文件;对于文件夹,是指是否可以进入文件夹
-:none
chmod //修改权限
eg: chmod ugo+rwx hello.txt
eg: chmod a+rw hello.txt //给所有用户加读和执行权限
./hello.txt 加了执行权限后,如果不指定路径,系统会在$PATH里找。所以对于不是可执行的文件执行时,需要加路径。如:./hello.txt
eg: chmod -R 777 dir //R表示递归,文件夹里的文件也是777
eg:chmod ubuntu:ubuntu /soft //将/soft目录的拥有权限修改为ubuntu组中的ubuntu用户
adduser
eg: adduser --system --home /home/ubuntu2 --gid 1000 ubuntu2 //gid为组编号
useradd
是一个底层添加用户的命令
apt
apt-get update //更新
apt-get upgrade //升级
apt-cache search ubuntu-desktop //搜索
apt-get install ubuntu-desktop .//安装
从本地安装桌面
1.取得iso文件
2.挂载iso文件到/mnt下
$>mount /dev/cdrom /mnt/cdrom
3.修改/etc/apt/source.list
deb file:/mnt/cdrom ./
4.更新和升级软件源
$>apt-get update
$>apt-get upgrade
5.安装
$>apt-get install ubuntu-desktop
6.卸载
$>apt-get remove ubuntu-desktop
7.dpkg //安装deb软件包
dpkg -i xxx.deb //i:install
dpkg --remove xxx //卸载软件
dpkg-query --list
安装虚拟机增强工具
1.VMware->重新安装VMware tools
2.自动打开光驱文件
3.复制vmware-tools-xxx.tar.gz
4.解压
5../vmware-install.pl
客户机和宿主机共享文件夹
1.虚拟机->选项->共享文件夹
2.进入客户机的/mnt/hgfs查看共享的文件夹
客户机和宿主机共享剪贴板
1.虚拟机->设置->客户机隔离
客户机和宿主机之间支持拖放
略
虚拟机的网络连接方式
1.bridge(桥接)
完全模拟网络中的真实电脑,可配IP,访问互联网,局域网内互访。如果无网络,彼此之间无法连通。
2.NAT
Net Address Transform 网络地址转换
和Host形成局域网,由Host作NAT或DNS,可访问互联网,局域网内的主机无法访问客户机。没有网络时,Host和客户机之间仍然能连通。
Vnet8是宿主机的虚拟网卡,作NAT
3.only host(仅主机)
和NAT非常像,但client不能访问外部网络,主要出于安全角度出发。即client和host之间形成封闭的局域网络。
编辑ubuntu网络配置文件(/etc/network/interfaces)
$>sudo gedit interfaces
iface eth0 inet static
address 192.168.238.128
netmask 255.255.255.0
gateway 192.168.238.2
dns-nameservers 192.168.238.2
auto eth0
重启网络服务
$>sudo /etc/init.d/networking/restart
for循环格式一
eg: for a in 1 2 3 4; do echo $a > ${a}.txt;done //产生4个新文件
可编写脚本文件test.sh
$>gedit test.sh
#! /bin/bash
if [[ $# -lt 1]]; then echo no parameter!!!;exit;fi //表示参数个数
for a in "$@"; do echo $a > ${a};done //$@表示所有参数
$>chmod a+x test.sh //test.sh需加执行权限
$>./test.sh 1.txt 2.txt 3.txt //执行时带参数
for循环格式二
for(( a=1;a< 11;a=a+1));do echo $a;done
while循环
((表达式1))
while(( 表达式2));do
命令;
((表达式3))
done
例:
((a=1))
while((a<=10) ;do
echo $a
((a=a+1))
done
hadoop环境的搭建(ubuntu)
ubuntu桌面模式和文本模式的切换:
1.ctrl+alt+F6 //切换文本模式
2.ctrl+alt+F7 //切换桌面模式,也可以运行startx进入图形界面
ubuntu开机进入文本模式:
1.修改/etc/default/grub文件
#GRUB_CMDLINE_LINUX_DEFAULT="quite" //quite为图形模式
GRUB_CMDLINE_LINUX_DEFAULT="text" //text为文本模式
2.运行update-grub
$>sudo update-grub
一、配置ubuntu系统
1.修改主机名:
$>su root //切换root
$>echo s100 > hostname //重定向
$>reboot //重启
2.修改IP:
[/etc/network/interfaces]
iface eth0 inet static //静态IP
address 192.168.231.100
netmask 255.255.255.0
gateway 192.168.231.2
dns-nameservers 192.168.231.2
auto eth0
3.修改dns:
[/etc/hosts]
127.0.0.1 localhost
192.168.231.100 s100
192.168.231.101 s101
...
win7修改dns:
[c:windowssystem32driversetchosts]
127.0.0.1 localhost
192.168.231.100 s100
192.168.231.101 s101
...
BigData:
数据存储单位:
K、M、G、T、P、E、Z、Y、N
hadoop:
可靠、可伸缩、分布式计算的开源软件。
hadoop是分布式计算大规模数据集框架,使用简单数据模型,可从单个服务器扩展到几千台主机,每台机器都有本地存储和计算,不需要使用硬件来获得高可用性,类库在应用层检测和处理故障,因此在集群之上获得HA(高可用,达到99.999%存活率)服务。
分布式:
分布在不同主机上的进程协同在一起,才能构成整个应用。(也可是同一主机上的不同进程)
去IOE:
是阿里巴巴造出的概念,其本意是在阿里巴巴的体系架构中,去掉IBM的小型机,Oracle数据库,EMC存储设备,代之以自己在开源软件的基础上开发的系统。即被新型的云计算技术所替代(云化)。还有一层意思,是对美国产品“严打”,减少或者不再购买IBM、Oracle、EMC的产品。
IBM(服务器提供商)、Oracle(数据库软件提供商)、EMC(存储设备提供商)
4V:
Volumn(体量大)、Variaty(样式多,有结构化、半结构化、非结构化的)、Velocity(数据产生的速度快)、Valueless(价值密度低)
MapReduce:
MR //映射和化简,编程模型
二、hadoop安装
配置文件介绍:
用户级:
可以在当前用户的目录下配置.bashrc或者.profile,配置的信息只有当前用户可用。
[~/.bashrc]或[~/.profile]
全局:
[/etc/enviroment]
1.安装jdk
1)安装(略)
$>ln -s /soft/jdk1.8.0_65 jdk //做个符号链接
2)配置环境变量
a.配置JAVA_HOME变量
JAVA_HOME=/soft/jdk
b.配置PATH变量
PATH=.../soft/jdk/bin
c.编译
source <配置文件>
如:source /etc/enviroment
d)检测安装是否成功
$>java -version
2.安装hadoop
1)安装(略)
2)配置环境变量
a.配置HADOOP_HOME
HADOOP_HOME=/soft/hadoop
b.配置PATH
PATH=...:/soft/hadoop/bin:/soft/hadoop/sbin
c.编译
$>source /etc/enviroment
d.检测安装是否成功
$>hadoop -version
hadoop包含的模块:
1)hadoop common
支持其他模块的通用工具模块
2)hadoop Distributed File System(HDFS)
分布式文件系统,提供了 对应用程序高吞吐量访问。
[进程]
NameNode //NN
DataNode //DN
SecondaryNameNode //2NN
3)hadoop yarn(Yet Another Resource Negotiate)
作业调度与集群资源管理
[进程]
ResourceManager //RM
NodeManager //NM
4)hadoop mapreduce
基于yarn系统的大数据集并行处理
hadoop安装的三种模式:
1)Standalone/local(独立/本地)
用的就是本地文件系统,不需要启动守护进程,所有的程序都运行在一个JVM中,它是默认的模式。
hadoop fs -ls
2)Peseudo Distributed Mode (伪分布)配置过程
a.修改配置文件
[core-site.xml]
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost/</value>
</property>
</configuration>
[hdfs-site.xml]
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
[mapred-site.xml]
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
[yarn-site.xml]
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
[slaves]
localhost
b.配置SSH免密登录
安装ssh
$>sudo apt-get install ssh
生成密钥对
$>ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa //-t rsa:指定加密算法为rsa -P '':指定密码为空 -f:指定文件
//id_rsa.pub为公钥文件,id_rsa为私钥文件
将公钥内容映射追加到密钥库里
$>cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
登录确认
$>ssh localhost
...
$>exit //退出登录
再次登录
$>ssh localhost //免密
c.格式化hdfs
$>hadoop namenode -format
d.启动所有进程
$>start-all.sh //启动hadoop所有进程
$>jps //查看进程
//SecondaryNameNode
//ResourceManager
//NameNode
//DataNode
//NodeManager
$>hadoop fs -mkdir -p /user/ubuntu/data //在hdfs上创建文件夹
$>hadoop fs -lsr / //递归查看/下所有的文件
查看hdfs的WebUI:http://localhost:50070
3)Full Distributed Mode
a.修改配置文件
//类似于伪分布
[core-site.xml]
fs.defaultFS=hdfs://s100
[hdfs-site.xml]
dfs.replication=3
[yarn-site.xml]
yarn.resourcemanager.hostname=s100 //资源管理器节点为s100
[mapred-site.xml]
mapred.framework.name=yarn
[slaves] //数据节点
s101
s102
...
b.配置SSH无密登录
修改ubuntu的软件源:
[/etc/apt/source.list]
...
$>apt-get update //修改后要apt-get update更新
安装ssh
$>apt-get install ssh
$>ps -Af | grep ssh //查看是否有sshd服务进程
生成密钥对
//略
//以下仅供参考
用nc将公钥复制到其他的机器上:
接收端:nc -l 8888 > id_rsa.pub.s100 //监听8888端口,将接收到的数据重定向到id_rsa.pub.s100文件中。
发送端:nc s101 8888 < id_rsa.pub //将公钥id_rsa.pub内容发送到s101的8888端口上
接收端:cat id_rsa.pub.s100 >> authorized_keys //将id_rsa.pub.s100的内容追加到密钥库文件中。
scp是安全的远程复制程序,基于ssh
缺点:拷贝符号链接时,会转换成文件
rsync是远程同步工具,主要用于备份和镜像,支持链接拷贝,可以避免复制相同的文件,
编写集群文件分发脚本:
[xsync]
#! /bin/bash #判断参数个数 pcount=$# if (( pcount<1 )); then echo no args! fi #获得文件名 p1=$1 fname=`basename $p1` #获得路径,将相对路径转换物理路径 pdir=`cd -P $(dirname $p1) ; pwd` cuser=`whoami` for(( host=101;host<105;host=host+1 )) ;do echo ------------ s$host -------------- rsync -rvl $pdir/$fname $cuser@s$host:$pdir #r表示递归、v表示显示信息、l表示包括链接 done
编写远程调用集群中每一台节点执行命令:
[xcall]
#! /bin/bash #判断参数个数 pcount=$# if (( pcount<1 )); then echo no args! fi echo -------- localhost -------- $@ #所有参数 for(( host=101;host<105;host=host+1 )) ;do echo -------- s$host -------- ssh s$host $@ done
hadoop默认的配置文件在jar包中的位置:
[hadoop-common-x.x.x.jar/core-default.xml]
[hadoop-hdfs-x.x.x.jar/hdfs-default.xml]
[hadoop-yarn-x.x.x.jar/yarn-default.xml]
[hadoop-mapred-client-core-x.x.x.jar/mapred-default.xml]
设置集群的SecondaryNameNode节点:
[hdfs-site.xml]
...
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>s104:50090</value>
</property>
...
守护进程就是为其它进程提供服务的进程
单独启动进程:
hadoop-daemon.sh start namenode //启动名称节点,关闭使用start换成stop
hadoop-daemon.sh start secondarynamenode //启动辅助名称节点
hadoop-daemons.sh start datanode //启动所有的数据节点
hadoop常用的文件操作命令
hadoop fs -<command>
hdfs dfs -<command> //和上面的命令一样
hadoop fs -help <command> //查看put命令的帮助
hdfs dfs -ls -R / //递归查看集群根目录
hdfs dfs -put hello.txt . //.表示集群的当前目录,就是/user/ubuntu/
//put等价于copyFromLocal
hadoop环境的搭建(centos)
1)在Linux中安装jdk,并设置环境变量
安装比较简单,略
配置环境变量:vi /etc/profile
export JAVA_HOME=/usr/local/jdk-1.8.0 export JRE_HOME=$JAVA_HOME/jre export HADOOP_HOME=/opt/hadoop-1.2.1 export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$PATH
2)下载Hadoop,并设置hadoop环境变量
配置环境变量:vi /etc/profile 如上所示
设置好后编译一下:source /etc/profile
3)修改4个配置文件
位于安装目录下conf目录里
hadoop-env.sh
# The java implementation to use. Required. export JAVA_HOME=/usr/local/jdk-1.8.0
core-site.xml(在<configuration></configuration>里添加)
<property> <name>hadoop.tmp.dir</name> <value>/hadoop</value> </property> <property> <name>dfs.name.dir</name> <value>/hadoop/name</value> </property> <property> <name>fs.default.name</name> <value>hdfs://imooc:9000</value> </property>
hdfs-site.xml
<property> <name>dfs.data.dir</name> <value>/hadoop/data</value> </property>
mapred-site.xml
<property> <name>mapred.job.tracker</name> <value>imooc:9001</value> </property>
4)执行
hadoop namendoe -format //格式化namenode
start-all.sh //启动hadoop
jps //查看当前启动的进程,如下所示
[root@imooc conf]# jps
3700 DataNode
3892 JobTracker
3573 NameNode
3815 SecondaryNameNode
4039 TaskTracker
4233 Jps
hadoop环境搭建完毕...

HDFS的基本概念
块(block)
是一个固定大小的逻辑单元,在HDFS中,HDFS的文件被分成块进行存储的
HDFS块的默认大小是64MB
块是文件存储处理的逻辑单元
HDFS里有两类节点,一个NameNode,一个是DataNode。
NameNode
NameNode是管理节点,存放文件元数据,元数据包括两个部分:
(1)文件与数据块的映射表
(2)数据块与数据节点的映射表
NameNode节点里保存了大量的元数据,客户查询文件时,它会从NameNode读取元数据,返返回结果就知道这个文件是存放在哪些节点上的,于是向这些节点去拿数据块,然后拼装成一个完整的文件
DataNode
DataNode是HDFS的工作节点,存放数据块的。
HDFS数据管理策略
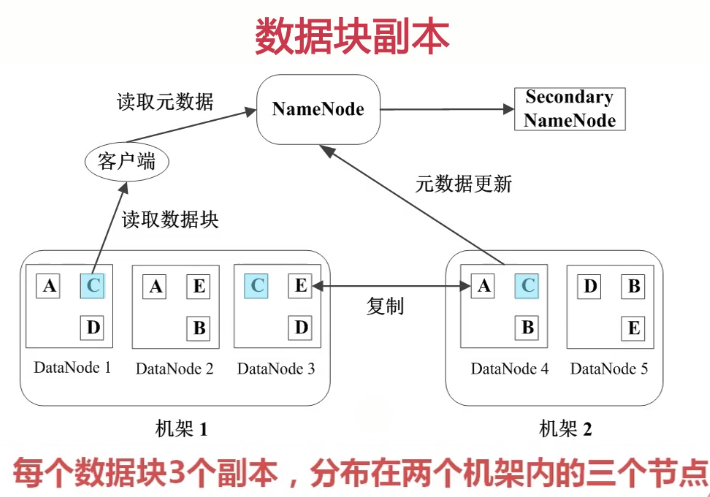
心跳检测:所谓心跳检测就是NameNode和DataNode之间会有一个心跳协议。每隔几秒DataNode会向NameNode汇报自己的状态,是不是还处于一个active状态,这个网络有没有断,是不是关机了,或down机的情况。那么NameNode就会知道当前的整个机群里,哪些DataNode已经挂了,哪些DataNode还健康。
为了保证NameNode的数据不会丢失,它同时做了一个备份,元数据会定期时行一个同步,同步到一个SecondaryNode节点上。
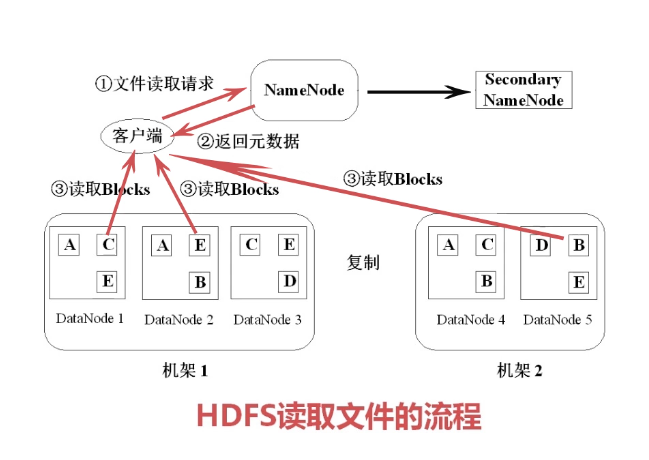
第1步客户端会向NameNode发出一个读取文件请求,把文件路径告诉NameNode,NameNode查询元数据,将元数据返回客户端,这样客户端就知道这个文件包含哪些块,以及这些块分别在哪些DataNode里,从这些DataNode读取block将数据下载下来以后进行组装。这样读取的过程就完成了。

第1步将文件拆分成块,固定大小64M的block,通知NameNode。第2步NameNode会找到一些可用的、当前在线的、有足够磁盘空间的DataNode返回给客户端。第3步根据返回的DataNode,客户端会将数据块进行写入。第4步写入第一个块之后要进行流水线复制,通过流水线管道复制到其它的DataNode里(包括本机架和其它的机架)。第5步更新元数据,告诉NameNode,数据块创建已经完成,这样可以保证NameNode里的元数据都是最新的状态。这样第一个block完成后,再开始写第二个block...
HDFS的特点
1、数据冗余,硬件容错
用三个备份来硬件上的容错,这样就可以允许运行在廉价的机器上。
2、流式的数据访问
所谓流式访问就是我们的数据是一次写入,多次读取。一旦写入之后是不会被修改。除非删除再添加
3、存储大文件
如果是大量的小文件,NameNode的压力会非常大,因为小文件它的元数据也是很大的,所以NameNode的负载压力就会很大。所以它适合存储大文件。
HDFS的适用性和局限性
适合数据批量读写,吞吐量高;
不适合交互式的应用,低延迟很难满足(比如数据库的操作就不适合)
适合一次写入多次读取,顺序读写
不支持多用户并发写相同文件

Job是一个作业,比如:从100g的日志文件中找出出现次数最多的IP,一个job作业要完成的话,它需要分成多个任务Task,而每一个task又要分成MapTask和ReduceTask。
而在整个Hadoop MapReduce体系结构中,分成两类节点JobTracker和TaskTracker。jobTracker是一个master管理节点,当一个job进来后,JobTracker把它放在后选队列中,在适当的时候进行调度,选择一个job出来,将这个job拆分成多个map任务和reduce任务,这些任务分发给下面的TaskTracker来做,TaskTracker和HDFS的DataNode是同一组,这样可以保证我的计算是跟着数据走的。节点分配的任务专门计算本节点的数据,这样可以保证读写数据的开销最小,能够最快地找到我的数据,这也是MapReduce的设计思想,用移动计算来代替移动数据。
所以JobTracker的角色就包括:
(1)作业调度
作业过来的话,在后选队列里按着某种规则来进行调度。比如:先到先服务
(2)分配任务、监控任务执行进度
整个任务分发下去,任务分给TaskTracker去做的时候,TaskTracker将每个任务的进度给JobTracker一个状态更新,现在执行到一个什么状态
(3)监控TaskTracker的状态
看看TaskTracker是否出现故障
TaskTracker的角色
(1)执行任务
(2)汇报任务状态

输入数据进行数据分片,分片之后按照一定的规则分配TaskTracker,放到TaskTracker里,分配map任务,任务分配好了之后产生一个中间结果,中间结果就是键值队(key-value),key和value根据规则进行交换,再到reduce端进行reduce任务,Reduce端也是一些TaskTracker,只不过它是做reduce任务,运算完以后,数据结果写回到HDFS里面去。小结:数据是可能从HDFS来的,中间的一些结果可能会写到本地磁盘,经过交换之后,再发reduce的TaskTracker,运算完之后写回到HDFS里去。任何一个任务过来都先交到JobTracker里,JobTracker采用一定的调度策略进行分配(map任务和reduce任务),这就是MapReduce作业的执行过程。
MapReduce的容错机制
所谓容错就是允许在整个任务执行过程中,这些TaskTracker中间可能会出现一些故障。有两种容错机制:
(1)重复执行
这个出错有可能是job本身有错,也可能是硬件问题,或者是数据有问题。不管是什么情况,首先它要尝试重试,就是重新执行。
(2)推测执行
所谓推测执行就是在我们整个任务执行过程中需要等待所有的map端都执行完,reduce端才会开始。如果一个TaskTracker节点特别慢,JobTracker就会发现,然后允许算的慢的节点继续算,再找一台TaskTracker就做同样的事,这两个谁先算完,就把另一个终止掉。这样推测执行可以保证不会因为一两个TaskTracker的故障导致整个任务执行效率很低。这是hadoop里的一个容错机制。
javac编译时指定包
javac -classpath /opt/hadoop-1.2.1/hadoop-core-1.2.1.jar:/opt/hadoop-1.2.1/lib/commons-cli-1.2.jar -d word_count_class/ WordCount.java
jar打包
jar -cvf wordcount.jar *.class //将当前目录下所有的class文件打成jar包
将指定的文件上传到hadoop指定的目录下
hadoop fs -put input/* input_wordcount //input_wordcount需要在hadoop中创建,如: hadoop fs -mkdir input_wordcount
hadoop运行jar包
hadoop jar word_count_class/wordcount.jar WordCount input_wordcount output_wordcount //WordCount是主函数,input_wordcount和output_wordcount是该函数的两个参数,output_wordcount该文件夹如果没有创建,hadoop会自动创建的
查看输出目录:hadoop fs -ls output_wordcount
查看结果文件:hadoop fs -cat output_wordcount/part-r-00000
首先我们要打包程序,,打包完毕,我们该如何运行
首先显示一个比较简单的:
上面命令:hadoop jar x.jar 是运行包的一种方式,完整的方式为
hadoop jar x.jar ×××.MainClassName inputPath outputPath
同时解释一下:
x.jar为包的名称,包括路径,直接写包名称,则为默认路径
×××.MainClassName为运行的类名称
inputPath为输入路径
outputPath为输出路径。
HIVE理解
hive不是数据库,而是一个数据仓库,更像一个查询工具,是一个SQL解析引擎,能把SQL语句转换成MapReduce任务。
依靠存储在其它关系数据库metaStore来对hdfs结构化的数据进行管理,实现类似数据库的功能。
hive 表的结构信息是存储在传统的关系型数据库(metaStore)上(如: MySQL 、默认的是derby),而表的数据则是存储在hdfs 文件中,而且数据是结构化的。
表的结构信息(元数据meta)主要包括表的ID、表名、所属数据库、隶属人等。
计算引擎是MapReduce
适合存储海量全量(历史+更新)的轨迹数据,比对数据进行指的数据挖掘和分析等操作。
缺点:不具备数据库的主键、索引和更新的特性、但提供了分区、块索引和sql等特性。
总之,hive是利用mysql数据库在hadoop上层套了一个壳,来实现对hdfs结构化数据的映射,来为上层提供sql服务。
HBASE理解
HBASE是分布式数据,是按列存储的非结构化的数据库 (noSql)
计算执行引擎是 HBASE自身提供的,底层存储是基于hdfs的。
比较适合海量带时间序列的数据的存储和检索,性能较好。
原生支持rowkey的一级索引。
zookeeper:zk
保证高可靠、高可用的协同服务。集中式服务,用于配置信息、名称服务、分布式同步处理。
zk组件
1.client
向Server周期性发送信息,表明自己还活着,Server向Client响应确认消息。
2.Server
一个zk节点,向client提供所有服务,通知client,server是alive。
3.ensemble
全体,一组zk节点,需要最小值为3.
4.leader
领袖,特殊的zk节点,zk集群启动时,推选leader.
5.follow
随从,听命于leader的指令。
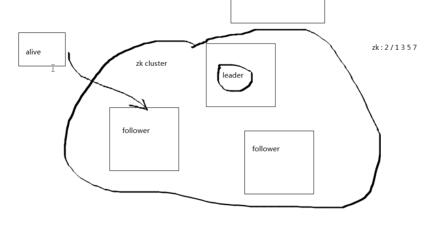
zk的namespace的等级结构(zk data modal)
1.驻留在内在的
2.树上每个节点都是znode
3.每个znode都有name,而且/分割
4.每个znode存放的数据不能超过1M
5.每个节点都有stat对象
a.version:与之关联的数据都发生改变,版本增加
b.acl:action control list
c.timestamp
d.datalength
zk znode节点类型
1.持久节点
2.临时节点
3.顺序节点
Flume
是分布式、可靠、可用性好服务,用于收集、聚合和移动大量的日志数据。
基于流计算(stream)的简单灵活架构。用于在线分析。
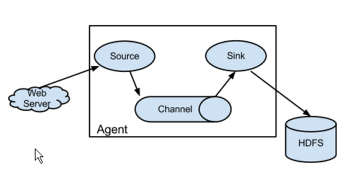
Flume是一个高可靠的,分布式的,可配置的工具。它主要被设计为从各种类型的web服务器拷贝流数据(日志)到HDFS。
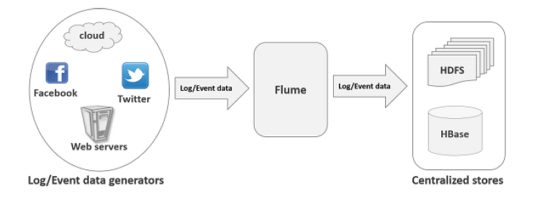
Flume的主要应用
假设某一电商服务器想要分析某一地区的顾客行为。为了这么做,他们必须将日志数据移到hadoop上进行分析。 Flume可以帮我们实现这一任务。
Flume通常可以将应用服务器产生的日志数据快速地移到hdfs.
Flume的优点
1.可以存储数据到任何的中央存储(hdfs,hbase)
2.当输入数据的速率大于写入存储目的地的速度时,Flume会进行缓冲。
3.Flume提供了上下文路由(数据流路线)。
4.Flume的事务是基于通道(channel),使用了两个事务模型(sender+receiver),确保消息被可靠发送。
5.Flume是可靠的,容错的,可伸缩的,可维护的,并且是可定制的。
Flume的特点
1.Flume可以高效地从web 服务器收集数据到hdfs上。
2.使用Flume,我们可以从多个服务器快速获取数据到hadoop.
3.可以用来导入由社交网络(twitter、facebook)、电商网站(Amozon)产生的海量事件数据。
4.Flume支持大量的源类型(source,web服务器、netcat瑞士军刀)和目标类型(destination)。
5.支持多级跳跃,扇入扇出,上下文路由。
6.支持水平伸缩。
为什么不用put命令而用Flume
1.同一时刻只能传输一个文件。
2.使用put命令,数据必须打包才能上传。而web服务器生成数据是持续不断的,所以,它难以胜任。
kafka
分布式流计算平台。
发布和订阅数据流,类似消息系统。
以分布式、副本集群的方式来存储数据流。
实时处理数据流。
构建实时数据流管道,水平可伸缩、容错、速度快。
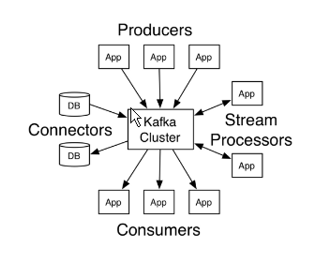
kafka的特点
1.持久存储,海量数据,TB级。
2.高吞吐量
3.分布式
支持多个server间的消息分区
4.多客户端支持
多语言协同(java .net php ruby),它是一个中间件
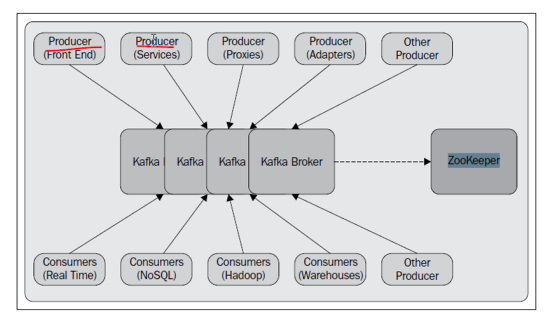
体验kafka
1.启动服务器
a.启动zk服务器
$>bin/zookeeper-server-start.sh config/zookeeper.properties
b.启动kafka服务器
$>kafka-server-start.sh config/server.properties
2.创建主题
#创建一个分区一个副本的主题
$>kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
$>zkcli.sh -server localhost:2181 //通过zk客户端查看zk的数据结构
$>kafka-topic.sh --list --zookeeper localhost:2181 //列出主题:test
3.发送信息
$>kafka-console-producer.sh --broker-list localhost:9092 --topic test
helloworld
how are you
4.启动消费者
$>kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
#helloworld
#how are you
5.创建多broker的kafka集群
a.创建多个server的配置文件
$>cp server.properties server-1.properties
[server-1.properties]
broker.id=1
listeners=PLAINTEXT://9093
...
log.dir=/tmp/kafka-log-1
$>cp server.properties server-1.properties
[server-1.properties]
broker.id=2
listeners=PLAINTEXT://9094
...
log.dir=/tmp/kafka-log-2
b.启动server
$>kafka-server-start config/server-1.properties &
$>kafka-server-start config/server-2.properties &
c.创建主题
$>kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
$>kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
$>kafka-topics.sh --describe --zookeeper localhost:2181 --topic test #查看原有主题
d.发送信息给主题
$>kafka-consol-producer.sh --broker-list localhost:9092 --topic my-replicated-topic
e.消费消息
$>kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic
f.容错测试
1)找到server-1进程
$>ps -Af |grep server-1
2)杀死进程
$>kill pid
3)查看主题描述
$>kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
4)启动消费者主题消息
$>kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic
sqoop
Apache Sqoop是hadoop和RDBMS之间传递数据的工具。
配置Sqoop2 Server和Sqoop Client:
Server:是所有Client的入口。
Client:可以安装在任何节点上。
安装Sqoop Server:
1.确保hadoop可用,且hadoop环境变量可用。
2.配置hadoop core-site.xml文件:
<property>
<name>hadoop.proxyuser.sqoop2.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.sqoop2.group</name>
<value>*</value>
</property>
3.配置hadoop/etc/hadoop/container-executor.cfg:
allowed.system.users=sqoop2
4.第三方类库(驱动程序)
直接复制jar包到sqoop/tools/lib下
5.配置sqoop Server配置文件:
[sqoop/conf/sqoop_bootstrap.properties]
[sqoop/conf/sqoop.properties]
6.仓库的初始化
$bin>sqoop2-tool upgrade
$bin>sqoop2-tool verify //验证初始化是否成功
7.Server的启动和停止
$bin>sqoop2-server start //端口12000
$bin>sqoop2-server stop
安装Sqoop Client:
1.启动客户端
$bin>sqoop2-shell
2.连接到自己的Server
sqoop:000>set server --host localhost --port 12000 --webapp sqoop
sqoop:000>show version --all //验证连接
3.查看sqoop注册的连接
sqoop:000>show connector
4.创建mysql连接
sqoop:000>create link --connector generic-jdbc-connector
Name:mysql
Driver class:com.mysql.jdbc.Driver
Connection string:jdbc:mysql://192.168.231.1:3306/test
Username:root
Password:****
entry#protocal=tcp
sqoop:000>show link --all;
5.创建hdfs连接
sqoop:000>create link --connector hdfs-connector
Name:hdfs
URI:file:///
Conf directory:/soft/hadoop/etc/hadoop
entry#回车
sqoop:000>show link --all;
6.创建作业(job)
sqoop:000>create job -f "mysql" -t "hdfs"
Name:myjob
Schema:test
Table name:customers
...
element#回车
sqoop:000>show job //显示作业
7. 启动作业
sqoop:000>start job --name myjob
sqoop将mysql导入到hdfs
1.import
sqoop import --connect jdbc:mysql://192.168.231.1:3306/test //""表示续行,即一条命令多行写。
--driver com.mysql.jdbc.Driver
--username root
--password root
--table customers //指定要导出的表为customers
--target-dir /home/ubuntu/tt //指定导入的目录
--increment append //增量模式为追加
--check-column id //检查id列
2.import-all-tables
sqoop import-all-tables --connect jdbc:mysql://192.168.231.1:3306/test
--driver com.mysql.jdbc.Driver
--username root
--password root
sqoop 将hdfs导出到mysql
sqoop export --connect jdbc:mysql://192.168.231.1:3306/test
--username root
--password root
--table ctmp #事先在mysql中创建一个临时表,准备接受hdfs导出的数据,注意数据结构要匹配。
--export-dir /home/ubuntu/emp_data
sqoop将mysql导入hive
sqoop import-all-tables --connect jdbc:mysql://192.168.231.1:3306/test
--driver com.mysql.jdbc.Driver
--username root
--password root
--table customers
--hive-import
--hive-overwrite
--hive-table test
sqoop 将mysql数据导入hbase
sqoop import-all-tables --connect jdbc:mysql://192.168.231.1:3306/test
--driver com.mysql.jdbc.Driver
--username root
--password root
--table customers
--hbase-create-table
--hbase-table tt
--column family cf1
--hbase-row-key id
pig
类似于hive,大数据集数据分析平台,pig有编译器最终生成MR程序。
pig latin:类似于sql,易于编写,优化处理,可扩展。
pig MR
数据流语言 数据处理过程
高级语言 低级语言
作连接操作非常简单 在两个数据集间执行连接操作非常困难
对具有SQL基础的人员来说容易使用 需要写java程序
多次查询就可以达到,代码量少 20倍的代码量
不需要编译,转换成MR作业 需要较长的编译过程
pig sql
过程式语言 声明式语言
schema(元数据,即表结构)是可选的 必须有schema
数据模型是嵌套关系 扁平关系(flat)
提供有限的查询优化 有更多机会进行SQL优化
pig hive
使用的是pig latin(最开始是由雅虎创建) 使用是HQL,最开始是由facebook创建
是一种数据流语言 是一种查询处理语言
是一种过程式语言,适用于管道编程 是一种声明式语言
结构化、半结构化和非结构化 结构化
Storm
是一个开源分布式实时计算系统
应用:实时分析,在线机器学习,持续计算,流式计算
特点:速度快,每秒每节点百万级别的元组。无状态,集群状态和分布式环境在zk中保存。确保每个消息至少被消费一次。
核心概念:
1.tuple:元组,是一种有序的数据结构,通常是任意类型的数据,使用逗号分隔,交给Storm计算。
2.stream:流,一系列无序的tuple。
3.spount:水龙头(源源不断产生数据的地方,数据源)
4.bolt:转接头,逻辑处理单元,spout数据传给bolt,bolt处理后产生新的数据,可以filter、aggregation(聚合)、连接、交互。
接收数据处理后发送给一个或多个bolt
5.topology:不会停止,除非主动杀死。MR是会停止 的。
6.tasks:spout和bolt的执行过程就是task。spout和bolt都可以以多实例的方式运行(每个运行在单独的线程上)
7.works:工作线程,storm在works中均衡地分发任务,监听job,启动和停止进程。
8.stream grouping:控制tuple如何进行路由。
内置4个分组策略
storm架构
1.节点类型
a)Numbus(灵气),master node。
主要工作运行topology,分析topology,收集执行的task。将task分发到supervisor。
b)supervisor:work node
接收Nimbus指令,有多个work 进程,监督work进程,完成任务的执行。
c)work process:执行的是相关的task,本身不执行,创建执行线程(executor),可以有多个executor。
d)executor:执行线程,由work进程孵化的一个线程,运行一个或多个task(spout/bot)
e)task:处理数据
f)zk:维护状态

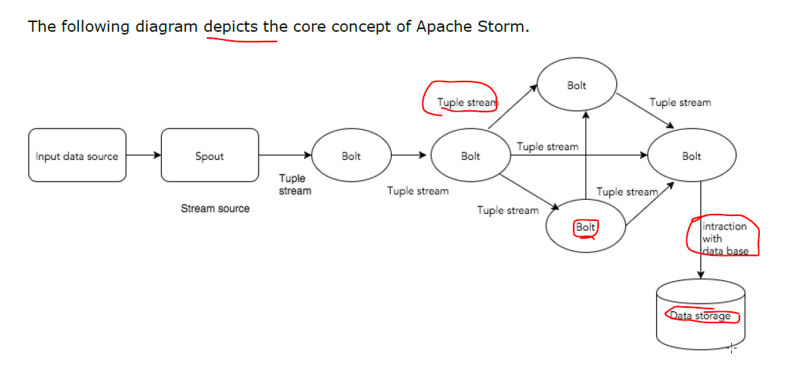
Python 中文分词 jieba
CUT函数简介
cut(sentence, cut_all=False, HMM=True)
返回生成器,遍历生成器即可获得分词的结果
lcut(sentence)
返回分词列表
代码示例:
import jieba sentence = '我爱自然语言处理' # 创建【Tokenizer.cut 生成器】对象 generator = jieba.cut(sentence) # 遍历生成器,打印分词结果 words = '/'.join(generator) print(words)
打印结果:
我/爱/自然语言/处理
词云wordCloud
简介
词云图,也叫文字云,是对文本中出现频率较高的“关键词”予以视觉化的展现,词云图过滤掉大量的低频低质的文本信息,使得浏览者只要一眼扫过文本就可领略文本的主旨。
代码示例:
#导入所需库 from wordcloud import WordCloud f = open(r'C:UsersJluTIgerDesktop exten.txt','r').read() wordcloud = WordCloud(background_color="white",width=1000, height=860, margin=2).generate(f) # width,height,margin可以设置图片属性 # generate 可以对全部文本进行自动分词,但是对中文支持不好 # 可以设置font_path参数来设置字体集 #background_color参数为设置背景颜色,默认颜色为黑色 import matplotlib.pyplot as plt plt.imshow(wordcloud) plt.axis("off") plt.show() wordcloud.to_file('test.png') # 保存图片,但是在第三模块的例子中 图片大小将会按照 mask 保存
运行结果:
