声明:本文内容和涉及到的代码仅限于个人学习,任何人不得作为商业用途。
本文将介绍我最近在学习Python过程中写的一个爬虫程序,将力争做到不需要有任何Python基础的程序员都能读懂。读者也可以先跳到文章末尾看最终收集的数据效果和完整代码。
1. 确立目标需求
本次练习Python爬虫的目标需求为以下两点:
1) 收集huajiao.com上的人气主播信息:每位主播的关注数,粉丝数,赞数,经验值等数据
2) 收集每位人气主播的直播历史数据,包括每次直播的开播时间,观看人数,赞数等数据
2. 确立逻辑步骤
首先通过浏览器查看www.huajiao.com网站上的各个页面,分析它的网站结构。得到如下信息:
1) 每一个导航项列出的都是直播列表,而非主播的个人主页列表
以“热门推荐”为例,如下图,每个直播页面的url格式为http://www.huajiao.com/l/liveId, 这里的liveId唯一标识一个直播,比如http://www.huajiao.com/l/52860333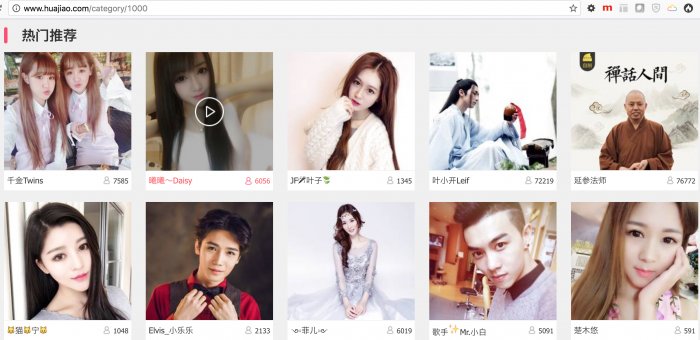
2) 在直播页上有主播的用户ID和昵称等信息
通过点击用户昵称可以进入主播的个人主页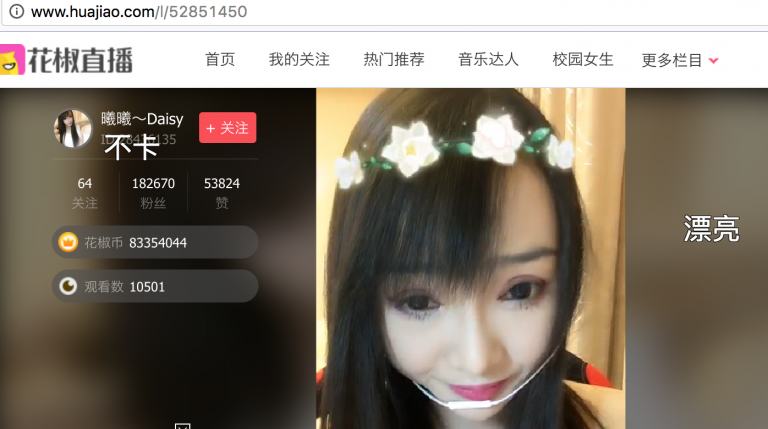
3) 在主播个人主页上有更加完整的个人信息
更加完整的个人信息包括关注数,粉丝数,赞数,经验值等数据;也有主播的直播历史数据,如下图,每个主播个人主页的url格式为http://www.huajiao.com/user/userId, 这里的userId唯一标识一个主播用户,比如http://www.huajiao.com/user/50647288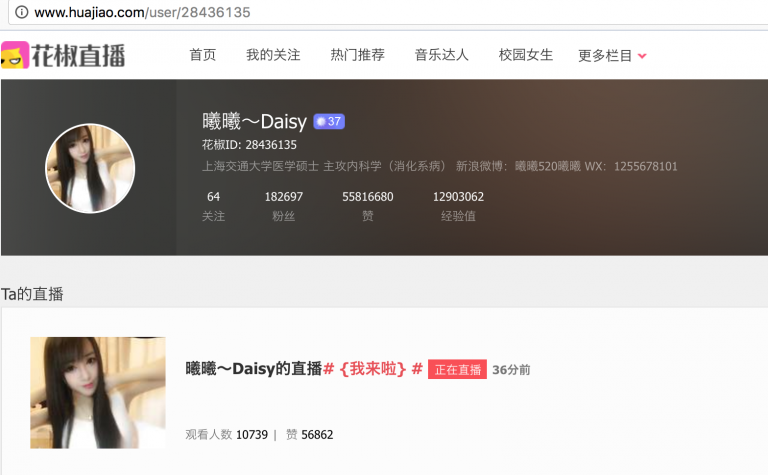
4) 程序逻辑
通过以上的分析,爬虫可以从直播列表页入手,获取到所有的直播url中的直播id,即上文提到的liveId;
拿到直播id后就可以进入直播页获取用户id,即前面提到的userId,
有了userId后就可以进入主播个人主页,在个人主页上有主播完整的个人信息和直播历史信息。
具体步骤如下:
- a):抓取直播列表页的html, 我选取的是”热门推荐”页面http://www.huajiao.com/category/1000
- b):从获取到的“热门推荐”页面的html中过滤出所有的直播地址,http://www.huajiao.com/l/liveId
- c):通过直播id抓取直播页面的html, 并过滤出主播的userId
- d):通过userId抓取主播的个人主页,过滤出关注数,粉丝数,赞数,经验值;过滤出直播历史数据。
- e):将用户数据和直播历史数据写入mysql保存
以上是根据观察网站页面,直观上得出的一个爬虫逻辑,但实际在开发过程中,还要考虑更多,比如:
- a)爬虫要定时执行,对于已经采集到的数据,采取何种更新策略
- b)直播历史数据需要请求相应的ajax接口,对收到的数据进行json解码分析
- c)主播昵称包含emoji表情,如果数据库使用常用的编码”utf8″则会写入报错
- d)过滤直播地址来获取直播id时,需要使用到正则匹配,我使用的是Python库”re”
- e)分析html,我使用的是”BeautifulSoup”
- f)读写mysql,我使用的是”pymysql”
如上逻辑步骤分析清楚后,就是编码了,利用Python来实现以上的逻辑步骤。
3. Python编码
1) 数据表设计
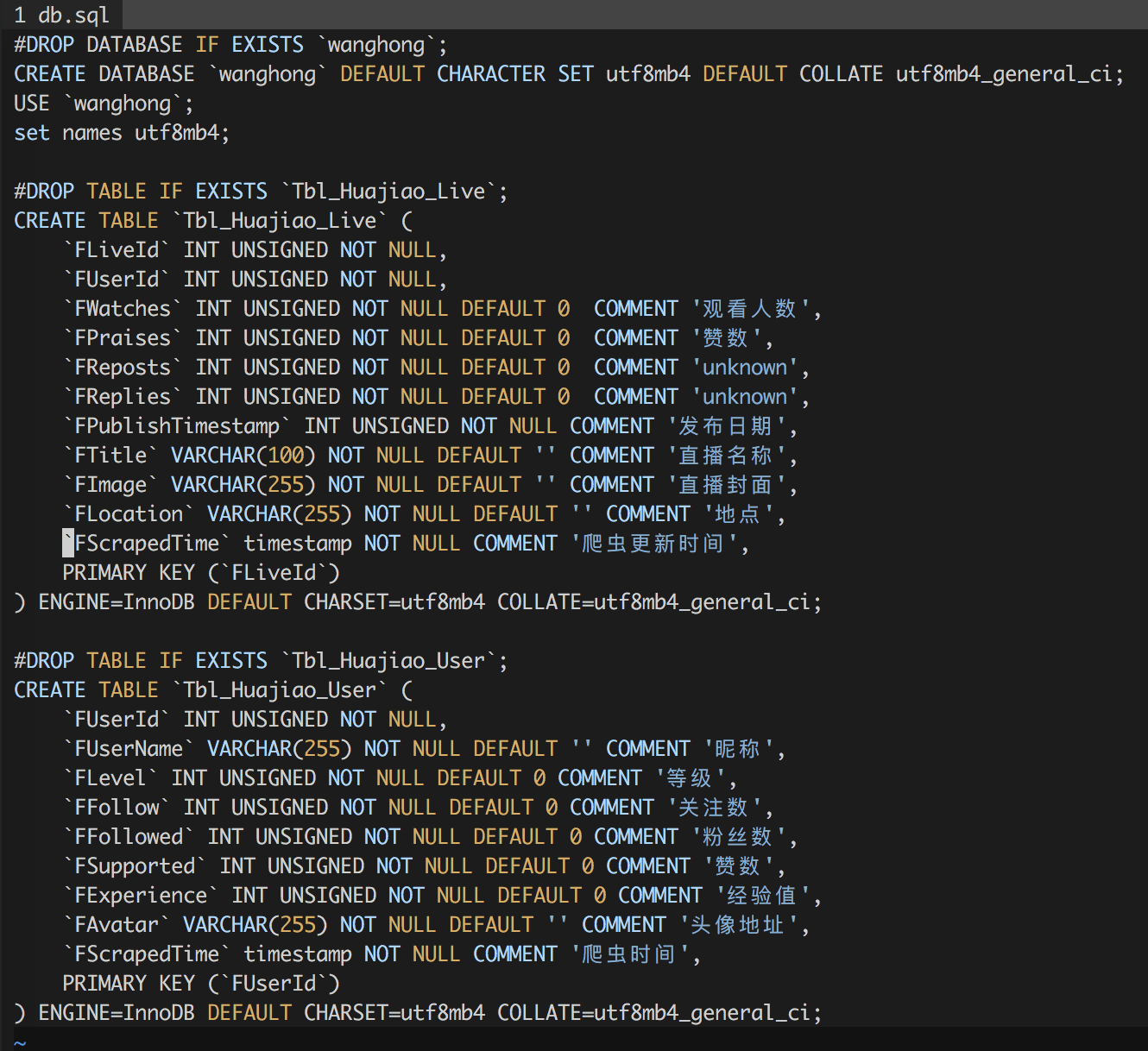
其中Tbl_Huajiao_User用于存储主播的个人数据,Tbl_Huajiao_Live用于存储主播的历史直播数据,其中字段FScrapedTime是每次记录更新的时间,依靠此字段可以实现简单的更新策略。
2) 从直播列表页过滤出直播Id列表
# filter out live ids from a url def filterLiveIds(url): html = urlopen(url) liveIds = set() bsObj = BeautifulSoup(html, "html.parser") for link in bsObj.findAll("a", href=re.compile("^(/l/)")): if 'href' in link.attrs: newPage = link.attrs['href'] liveId = re.findall("[0-9]+", newPage) liveIds.add(liveId[0]) return liveIds
关于python中如何定义函数,直接看以上代码就可以了,使用”def”和冒号,没有大括号。其中urlopen(url)是python的库函数,需要做import, 如下:
from urllib.request import urlopen
其中BeautifulSoup是一个第三方Python库,通过它就可以方便的解析html代码了,通过它的findAll()方法找出所有的a标签,并且这个方法支持正则,所以在它的参数里我传入了一个正则re.compile(“^(/l/)”)来表示寻找一”/l/”开头的所有链接地址,bsObj.findAll(“a”, href=re.compile(“^(/l/)”))的结果是一个列表,故使用for循环来遍历列表内的元素,在遍历过程中通过使用正则re.findall(“[0-9]+”, newPage)匹配出liveId, 并临时保存在liveIds中,并将liveIds返回给调用者。
3) 从直播页过滤出主播id
# get user id from live page def getUserId(liveId): html = urlopen("http://www.huajiao.com/" + "l/" + str(liveId)) bsObj = BeautifulSoup(html, "html.parser") text = bsObj.title.get_text() res = re.findall("[0-9]+", text) return res[0]
这里还是使用BeautifulSoup分析直播页的html结构,使用bsObj.title.get_text()获取到主播Id的文本信息后,通过正则获取到最终的userId
4) 通过userId进入主播个人主页获取个人信息
#get user data from user page def getUserData(userId): html = urlopen("http://www.huajiao.com/user/" + str(userId)) bsObj = BeautifulSoup(html, "html.parser") data = dict() try: userInfoObj = bsObj.find("div", {"id":"userInfo"}) data['FAvatar'] = userInfoObj.find("div", {"class": "avatar"}).img.attrs['src'] userId = userInfoObj.find("p", {"class":"user_id"}).get_text() data['FUserId'] = re.findall("[0-9]+", userId)[0] tmp = userInfoObj.h3.get_text('|', strip=True).split('|') #print(tmp[0].encode("utf-8")) data['FUserName'] = tmp[0] data['FLevel'] = tmp[1] tmp = userInfoObj.find("ul", {"class":"clearfix"}).get_text('|', strip=True).split('|') data['FFollow'] = tmp[0] data['FFollowed'] = tmp[2] data['FSupported'] = tmp[4] data['FExperience'] = tmp[6] return data except AttributeError: #traceback.print_exc() print(str(userId) + ":html parse error in getUserData()") return 0
以上使用了python的try-except的异常处理机制,因为在使用BeautifulSoup分析html数据时,有时候会因为没有某个对象而报错,对于这种报错需要处理,否则整个程序就会停止执行,这里我们打印出了日志,在日志中记录了相应的userId。当然这里还是主要用到了BeautifulSoup便捷的功能,比如其中的get_text()方法,能够将多个标签的文本抽取出来并且能够制定文本的分隔符,和对空格等字符进行过滤。
5) 将获取的个人信息写入mysql
# update user data def replaceUserData(data): conn = getMysqlConn() cur = conn.cursor() try: cur.execute("USE wanghong") cur.execute("set names utf8mb4") cur.execute("REPLACE INTO Tbl_Huajiao_User(FUserId,FUserName, FLevel, FFollow,FFollowed,FSupported,FExperience,FAvatar,FScrapedTime) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s)", (int(data['FUserId']), data['FUserName'],int(data['FLevel']),int(data['FFollow']),int(data['FFollowed']), int(data['FSupported']), int(data['FExperience']), data['FAvatar'],getNowTime()) ) conn.commit() except pymysql.err.InternalError as e: print(e)
这里使用了Python第三方库pymysql进行mysql的读写操作,而指定编码utf8mb4,也就是为了避免文章开始提到的一个问题,关于emoji表情符,如果数据库使用常用的编码”CHARSET=utf8 COLLATE=utf8_general_ci”则会写入报错,注意上面sql语句里也声明了utf8mb4字符集和编码。
这里没有使用mysql的“INSERT”,而是使用了“REPLACE”,是当包含同样的FUserId的一条记录被写入时将替换原来的记录,这样能够保证爬虫定时更新到最新的数据。
6) 获取某主播的直播历史数据
#get user history lives def getUserLives(userId): try: url = "http://webh.huajiao.com/User/getUserFeeds?fmt=json&uid=" + str(userId) html = urlopen(url).read().decode('utf-8') jsonData = json.loads(html) if jsonData['errno'] != 0: print(str(userId) + "error occured in getUserFeeds for: " + jsonData['msg']) return 0 return jsonData['data']['feeds'] except Exception as e: print(e) return 0
前面说到,获取直播历史数据是通过直接请求ajax接口地址的,代码中的url即为接口地址,这是通过浏览器的调试工具获得的。这里用到了json的解码。
7) 将主播的直播历史数据写入Mysql
这里和以上第5项类似,就不详述了,读者可以在文章末尾的github地址获取完整的代码
8) 定义骨架函数
#spider user ids def spiderUserDatas(): for liveId in getLiveIdsFromRecommendPage(): userId = getUserId(liveId) userData = getUserData(userId) if userData: replaceUserData(userData) return 1 #spider user lives def spiderUserLives(): userIds = selectUserIds(100) for userId in userIds: liveDatas = getUserLives(userId[0]) for liveData in liveDatas: liveData['feed']['FUserId'] = userId[0] replaceUserLive(liveData['feed']) return 1
所谓的骨架函数,就是控制单个小的功能函数,实现循环逻辑,一页一页的去采集数据。
spiderUserDatas()的逻辑:拿到liveId列表后,循环遍历的去取每一个liveId对应的userId,进而渠道userData并写入mysql;
spiderUserLives()的逻辑:从mysql中选出上次爬虫时间最晚的100个userId, 循环遍历地去取每一个user的直播历史数据并写入mysql;
9) 定义入口函数和命令行参数
def main(argv): if len(argv) < 2: print("Usage: python3 huajiao.py [spiderUserDatas|spiderUserLives]") exit() if (argv[1] == 'spiderUserDatas'): spiderUserDatas() elif (argv[1] == 'spiderUserLives'): spiderUserLives() elif (argv[1] == 'getUserCount'): print(getUserCount()) elif (argv[1] == 'getLiveCount'): print(getLiveCount()) else: print("Usage: python3 huajiao.py [spiderUserDatas|spiderUserLives|getUserCount|getLiveCount]") if __name__ == '__main__': main(sys.argv)
首先,要命名python在命令行模式下如何接收参数,通过sys.argv;
再有__name__的含义,如果文件被执行,则__name__的值为”__main__”;
这样通过以上代码就可以实现命令行调用和参数处理了。
比如要爬取主播的个人信息,则执行:
python3 huajiao.py spiderUserDatas
比如查看爬取了多少条用户数据信息,则执行:
python3 huajiao.py getUserCount
10) 加入crontab
*/1 * * * * python3 /root/PythonPractice/spiderWanghong/huajiao.py spiderUserDatas >> /tmp/huajiao.py_spiderUserDatas.log */1 * * * * python3 /root/PythonPractice/spiderWanghong/huajiao.py spiderUserLives >> /tmp/huajiao.py_spiderUserLives.log
4. 目标需求达成
主播数据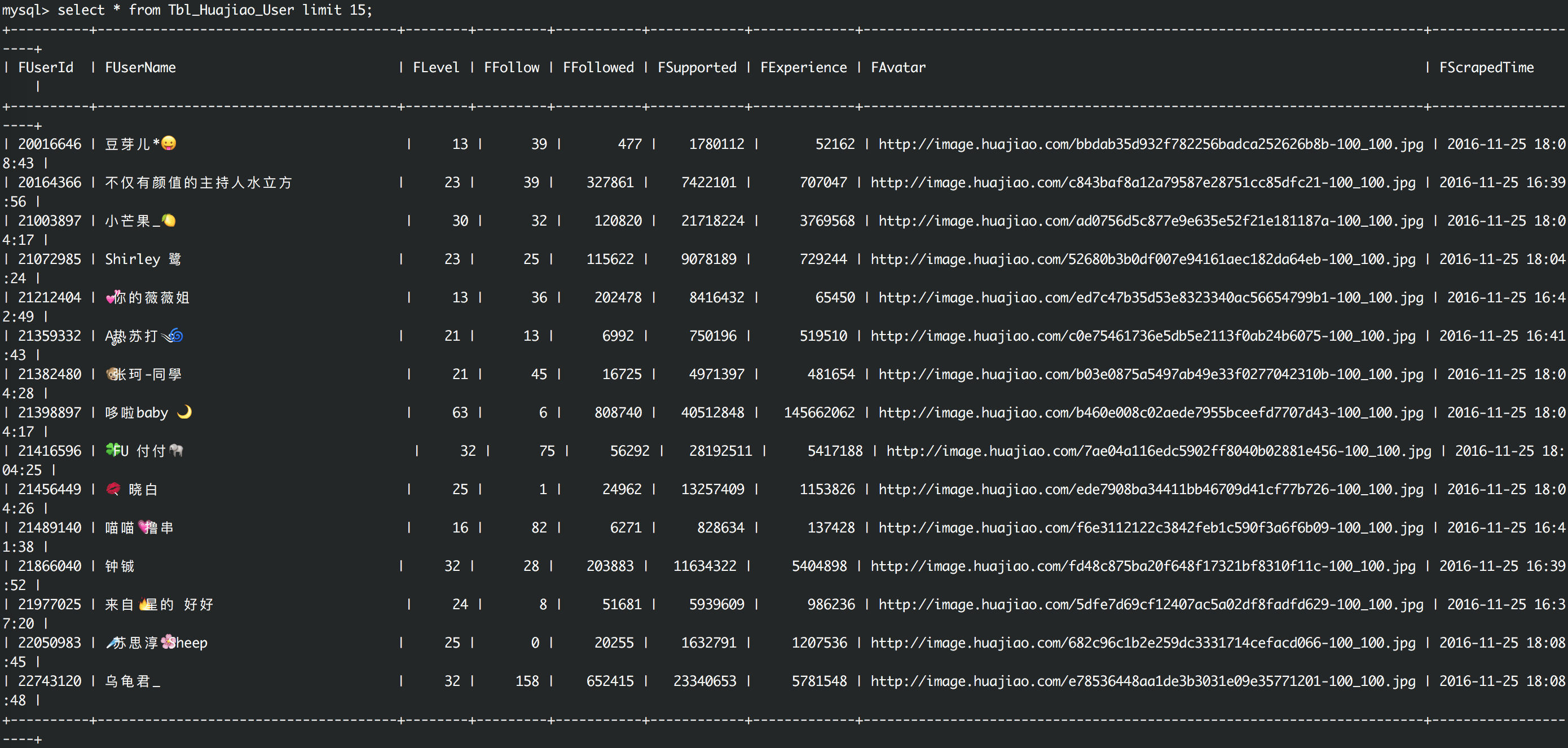
直播历史数据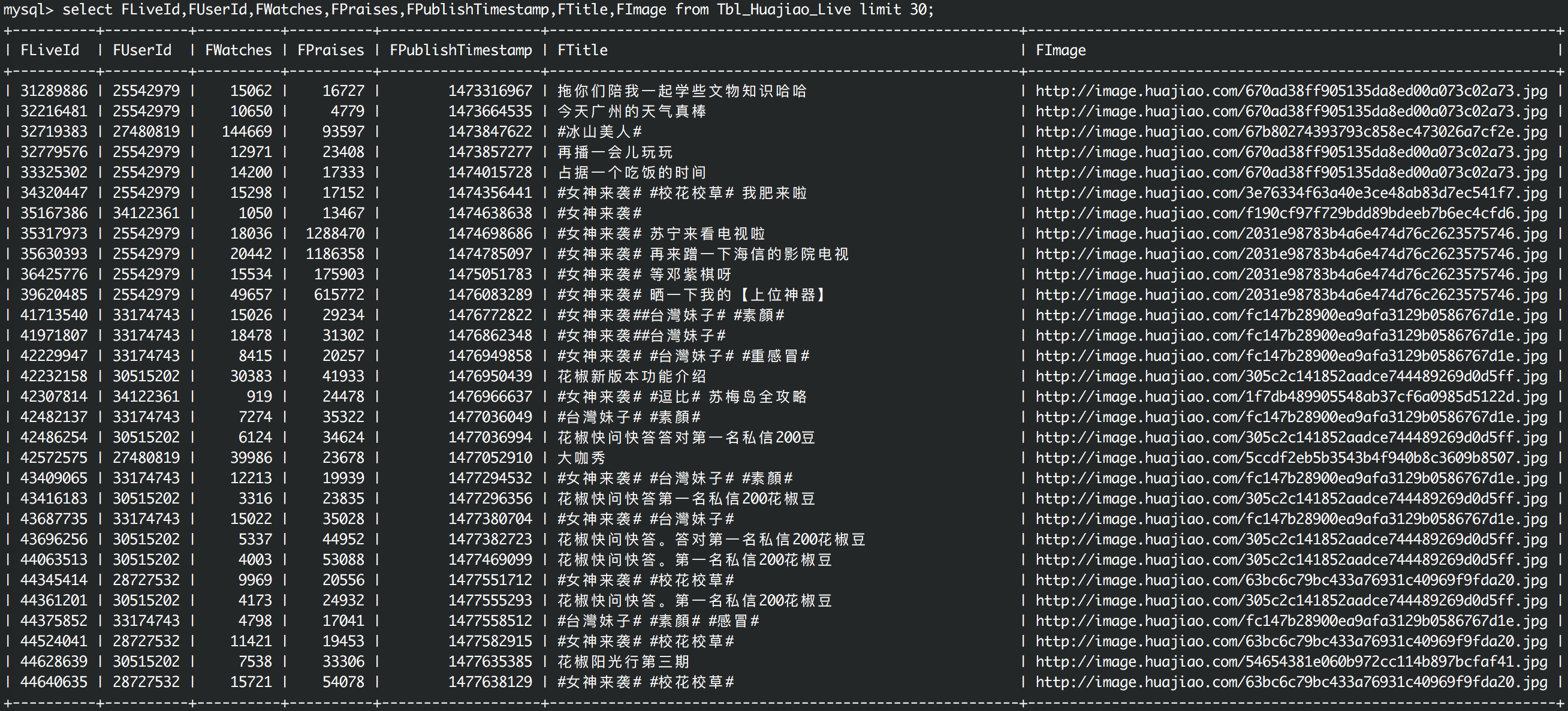
5. 待改进项和后续计划
对mysql的读写部分进行优化,现在写的比较臃肿
对其他直播网站进行分析并收集数据
将各个直播网站的数据进行聚合
6. 代码地址
https://github.com/octans/PythonPractice/tree/master/spiderWanghong
