|
1、核心组成 ELK由Elasticsearch、Logstash和Kibana三部分组件组成; Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。 Logstash是一个完全开源的工具,它可以对你的日志进行收集、分析,并将其存储供以后使用 Kibana是一个基于浏览器页面的Elasticsearch前端展示工具。Kibana全部使用HTML语言和Javascript编写的 2、组件作用 Logstash: logstash server端用来搜集日志; Elasticsearch: 存储各类日志; Kibana: web化接口用于查询和可视化日志; 3、ELK工作流程 在需要收集日志的所有服务上部署logstash,作为logstash agent(logstash shipper)用于监控并过滤收集日志,然后通过logstash indexer将日志收集在一起交给全文搜索服务ElasticSearch,可以用ElasticSearch进行自定义搜索通过Kibana 来结合自定义搜索进行页面展示。 <ignore_js_op> 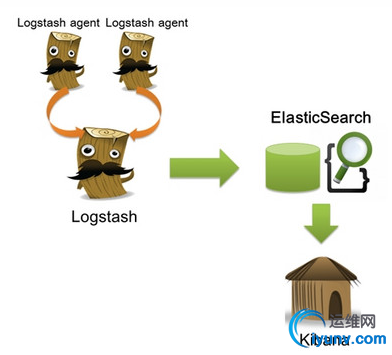 二、下载所需软件 wget http://download.oracle.com/otn-p ... 45-linux-x64.tar.gz wget https://download.elastic.co/elas ... search-1.7.2.tar.gz wget https://download.elastic.co/kiba ... .2-linux-x64.tar.gz wget https://download.elastic.co/logs ... gstash-1.5.4.tar.gz 三、安装步骤 1、首先安装jdk 安装jdk-8u45-linux-x64 root身份登录系统 将jdk-8u45-linux-x64.tar.gz拷贝到/opt下面 cd /opt tar zxvf jdk-8u45-linux-x64.tar.gz 解压后 生成的文件名字叫做jdk-8u45 vim /etc/profile 把如下代码放到文件的最后面 export JAVA_HOME=/opt/jdk-8u45 export JAVA_BIN=/opt/jdk-8u45/bin export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib/rt.jar export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin export JAVA_HOME JAVA_BIN PATH CLASSPATH source /etc/profile 2、安装Logstash tar –zxf logstash-1.5.2.tar.gz -C /usr/local/ 安装完成后运行如下命令: /usr/local/logstash-1.5.2/bin/logstash agent -f logstash-test1.conf # /usr/local/logstash-1.5.2/bin/logstash -e 'input { stdin { } } output { stdout {} }' Logstash startup completed this is test! 2015-07-15T03:28:56.938Z dell-09 this is test! 我们可以看到,我们输入什么内容logstash按照某种格式输出,其中-e参数参数允许Logstash直接通过命令行接受设置。这点尤其快速的帮助我们反复的测试配置是否正确而不用写配置文件。使用CTRL-C命令可以退出之前运行的Logstash。 使用-e参数在命令行中指定配置是很常用的方式,不过如果需要配置更多设置则需要很长的内容。这种情况,我们首先创建一个简单的配置文件,并且指定logstash使用这个配置文件。例如:在logstash安装目录(/usr/local/logstash-1.5.2)下创建一个“基本配置”测试文件logstash-test.conf,文件内容如下: # cat logstash-test.conf input { stdin { } } output { stdout { codec=> rubydebug } } Logstash使用input和output定义收集日志时的输入和输出的相关配置,本例中input定义了一个叫"stdin"的input,output定义一个叫"stdout"的output。无论我们输入什么字符,Logstash都会按照某种格式来返回我们输入的字符,其中output被定义为"stdout"并使用了codec参数来指定logstash输出格式。 3、安装Elasticsearch # tar -zxf elasticsearch-1.6.0.tar.gz -C /usr/local/ 启动Elasticsearch两种方式: # /usr/local/elasticsearch-1.6.0/bin/elasticsearch # nohup /usr/local/elasticsearch-1.6.0/bin/elasticsearch >nohup & 后台启动 验证及确认elasticsearch的9200端口已监听,说明elasticsearch已成功运行 [root@dell-09 tmp]# ss -tunpl |grep 9200 tcp LISTEN 0 50 :::9200 :::* users:(("java",16633,99)) 接下来我们在logstash安装目录下创建一个用于测试logstash使用elasticsearch作为logstash的后端的测试文件logstash-test.conf,该文件中定义了stdout和elasticsearch作为output,这样的“多重输出”即保证输出结果显示到屏幕上,同时也输出到elastisearch中。 cat logstash-test-simple.conf input { stdin { } } output { elasticsearch {host => "localhost" } stdout { codec=> rubydebug } } /usr/local/logstash-1.5.2/bin/logstash agent -f logstash-test-simple.conf Logstash startup completed es logstash #手动添加 { "message" => "es logstash", "@version" => "1", "@timestamp" => "2016-12-06T01:58:49.672Z", "host" => "dell-09" } 验证 使用curl命令发送请求来查看ES是否接收到了数据: curl 'http://localhost:9200/_search?pretty' <ignore_js_op> 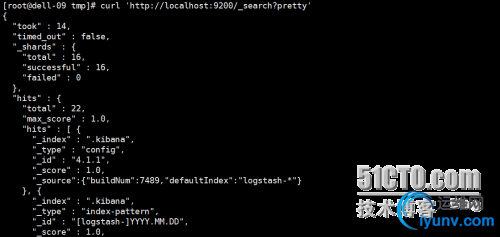 如果看到上图内容说明已经可以用Elasticsearch和Logstash来收集日志数据了。 4、安装elasticsearch插件 Elasticsearch-kopf插件可以查询Elasticsearch中的数据,安装elasticsearch-kopf,只要在你安装Elasticsearch的目录中执行以下命令即可: # cd /usr/local/elasticsearch-1.7.2/bin # ./plugin -install lmenezes/elasticsearch-kopf 访问kopf: http://10.193.1.86:9200/_plugin/kopf/#!/nodes 5、安装Kibana # tar -zxf kibana-4.1.1-linux-x64.tar.gz -C /usr/local/ 启动kibana # /usr/local/kibana-4.1.1-linux-x64/bin/kibana 使用[url=]http://localhost:5601访问Kibana,登录后,首先,配置一个索引,默认,Kibana的数据被指向Elasticsearch,使用默认的logstash-*的索引名称,并且是基于时间的,点击“Create”即可。然后点击discover[/url] note: 碎碎念: ①单机的elk到这基本已经完成了,主要部署思路还是在需要收集日志的所有服务上部署logstash,作为logstash agent(logstash shipper)用于监控并过滤收集日志,然后logstash indexer将日志收集在一起交给全文搜索服务ElasticSearch,可以用ElasticSearch进行自定义搜索通过Kibana 来结合自定义搜索进行页面展示。 ②如果生产服务器过多,有很多日志处理的话建议用zookeeper+kafka+elk …… |