PS:因为Spark是用内存运行 的,非常快

PS:
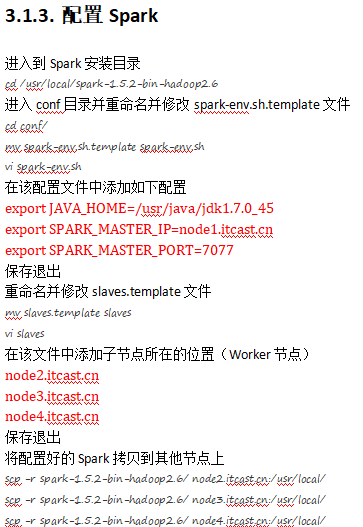
1.下面就是将conf的spark-env.template改变成spark-env.sh,并添加红色部分
2.修改slaves文件添加从设备
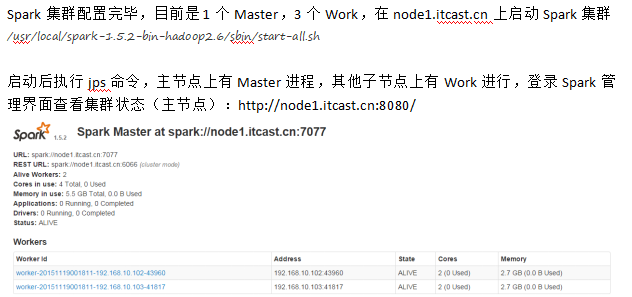
启动程序
PS:ui 端口是8080
1. 执行Spark程序
PS:如果不指定内核和内存,默认会全部占用
1.1. 执行第一个spark程序
/usr/local/spark-1.5.2-bin-hadoop2.6/bin/spark-submit
--class org.apache.spark.examples.SparkPi
--master spark://192.168.8.10:7077
--executor-memory 1G
--total-executor-cores 1
/root/apps/spark/lib/spark-examples-1.6.1-hadoop2.6.0.jar
100
该算法是利用蒙特·卡罗算法求PI

bin/spark-shell --master spark://192.168.8.10
PS:不得不说,速度的确非常快


PS:以并行化的方式创建RDD
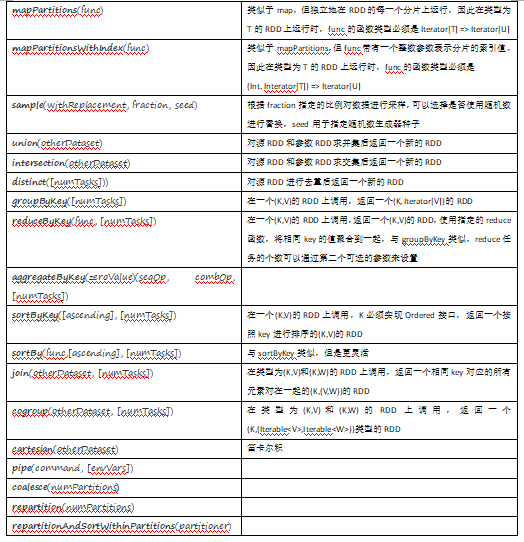
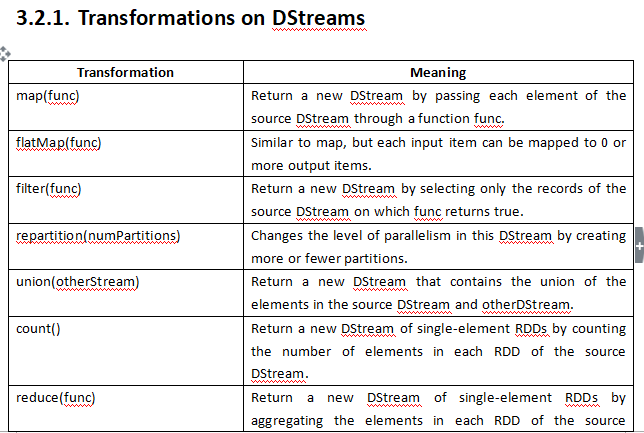
#常用Transformation(即转换,延迟加载) #通过并行化scala集合创建RDD val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8)) #查看该rdd的分区数量 rdd1.partitions.length val rdd1 = sc.parallelize(List(5,6,4,7,3,8,2,9,1,10)) val rdd2 = sc.parallelize(List(5,6,4,7,3,8,2,9,1,10)).map(_*2).sortBy(x=>x,true) val rdd3 = rdd2.filter(_>10) val rdd2 = sc.parallelize(List(5,6,4,7,3,8,2,9,1,10)).map(_*2).sortBy(x=>x+"",true) val rdd2 = sc.parallelize(List(5,6,4,7,3,8,2,9,1,10)).map(_*2).sortBy(x=>x.toString,true) val rdd4 = sc.parallelize(Array("a b c", "d e f", "h i j")) rdd4.flatMap(_.split(' ')).collect val rdd5 = sc.parallelize(List(List("a b c", "a b b"),List("e f g", "a f g"), List("h i j", "a a b"))) List("a b c", "a b b") =List("a","b",)) rdd5.flatMap(_.flatMap(_.split(" "))).collect #union求并集,注意类型要一致 val rdd6 = sc.parallelize(List(5,6,4,7)) val rdd7 = sc.parallelize(List(1,2,3,4)) val rdd8 = rdd6.union(rdd7) rdd8.distinct.sortBy(x=>x).collect #intersection求交集 val rdd9 = rdd6.intersection(rdd7) val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 2), ("kitty", 3))) val rdd2 = sc.parallelize(List(("jerry", 9), ("tom", 8), ("shuke", 7))) #join val rdd3 = rdd1.join(rdd2) val rdd3 = rdd1.leftOuterJoin(rdd2) val rdd3 = rdd1.rightOuterJoin(rdd2) #groupByKey val rdd3 = rdd1 union rdd2 rdd3.groupByKey rdd3.groupByKey.map(x=>(x._1,x._2.sum)) #WordCount, 第二个效率低 sc.textFile("/root/words.txt").flatMap(x=>x.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).collect sc.textFile("/root/words.txt").flatMap(x=>x.split(" ")).map((_,1)).groupByKey.map(t=>(t._1, t._2.sum)).collect #cogroup val rdd1 = sc.parallelize(List(("tom", 1), ("tom", 2), ("jerry", 3), ("kitty", 2))) val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2))) val rdd3 = rdd1.cogroup(rdd2) val rdd4 = rdd3.map(t=>(t._1, t._2._1.sum + t._2._2.sum)) #cartesian笛卡尔积 val rdd1 = sc.parallelize(List("tom", "jerry")) val rdd2 = sc.parallelize(List("tom", "kitty", "shuke")) val rdd3 = rdd1.cartesian(rdd2) ################################################################################################### #spark action val rdd1 = sc.parallelize(List(1,2,3,4,5), 2) #collect rdd1.collect #reduce val rdd2 = rdd1.reduce(_+_) #count rdd1.count #top rdd1.top(2) #take rdd1.take(2) #first(similer to take(1)) rdd1.first #takeOrdered rdd1.takeOrdered(3) # map(func) Return a new distributed dataset formed by passing each element of the source through a function func. filter(func) Return a new dataset formed by selecting those elements of the source on which func returns true. flatMap(func) Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). mapPartitions(func) Similar to map, but runs separately on each partition (block) of the RDD, so func must be of type Iterator<T> => Iterator<U> when running on an RDD of type T. mapPartitionsWithIndex(func) Similar to mapPartitions, but also provides func with an integer value representing the index of the partition, so func must be of type (Int, Iterator<T>) => Iterator<U> when running on an RDD of type T. sample(withReplacement, fraction, seed) Sample a fraction fraction of the data, with or without replacement, using a given random number generator seed. union(otherDataset) Return a new dataset that contains the union of the elements in the source dataset and the argument. intersection(otherDataset) Return a new RDD that contains the intersection of elements in the source dataset and the argument. distinct([numTasks])) Return a new dataset that contains the distinct elements of the source dataset. groupByKey([numTasks]) When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable<V>) pairs. reduceByKey(func, [numTasks]) When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function func, which must be of type (V,V) => V. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) When called on a dataset of (K, V) pairs, returns a dataset of (K, U) pairs where the values for each key are aggregated using the given combine functions and a neutral "zero" value. Allows an aggregated value type that is different than the input value type, while avoiding unnecessary allocations. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. sortByKey([ascending], [numTasks]) When called on a dataset of (K, V) pairs where K implements Ordered, returns a dataset of (K, V) pairs sorted by keys in ascending or descending order, as specified in the boolean ascending argument. join(otherDataset, [numTasks]) When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all pairs of elements for each key. Outer joins are supported through leftOuterJoin, rightOuterJoin, and fullOuterJoin. cogroup(otherDataset, [numTasks]) When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (Iterable<V>, Iterable<W>)) tuples. This operation is also called groupWith. cartesian(otherDataset) When called on datasets of types T and U, returns a dataset of (T, U) pairs (all pairs of elements). pipe(command, [envVars]) Pipe each partition of the RDD through a shell command, e.g. a Perl or bash script. RDD elements are written to the process's stdin and lines output to its stdout are returned as an RDD of strings. coalesce(numPartitions) Decrease the number of partitions in the RDD to numPartitions. Useful for running operations more efficiently after filtering down a large dataset. repartition(numPartitions) Reshuffle the data in the RDD randomly to create either more or fewer partitions and balance it across them. This always shuffles all data over the network. repartitionAndSortWithinPartitions(partitioner) Repartition the RDD according to the given partitioner and, within each resulting partition, sort records by their keys. This is more efficient than calling repartition and then sorting within each partition because it can push the sorting down into the shuffle machinery. (K,(Iterable<V>,Iterable<W>))
***********************************************************************************************
map是对每个元素操作, mapPartitions是对其中的每个partition操作
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
mapPartitionsWithIndex : 把每个partition中的分区号和对应的值拿出来, 看源码
val func = (index: Int, iter: Iterator[(Int)]) => {
iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator
}
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)
rdd1.mapPartitionsWithIndex(func).collect
PS:通过并行化创建Rdd并指定两个分区,定义查看分区的函数,根据函数查看结果。

PS:程序不可能在控制台写,通常是在java写好jar包提交到集群上运行
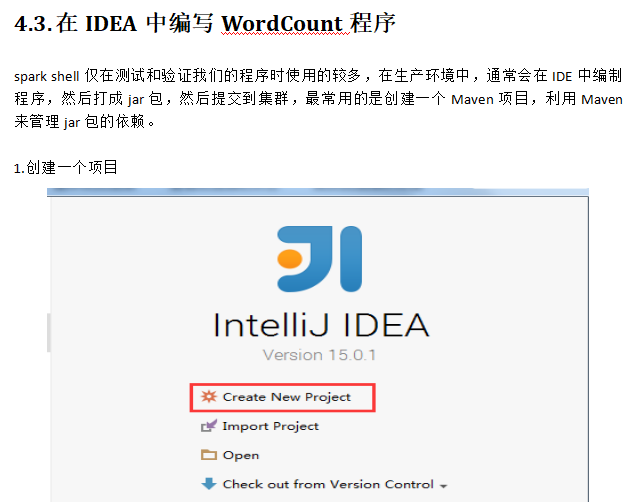
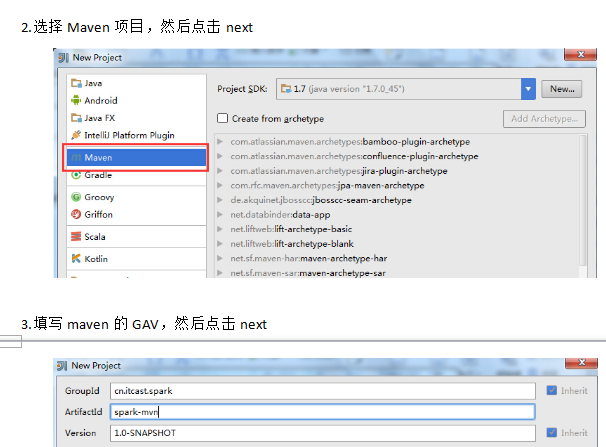
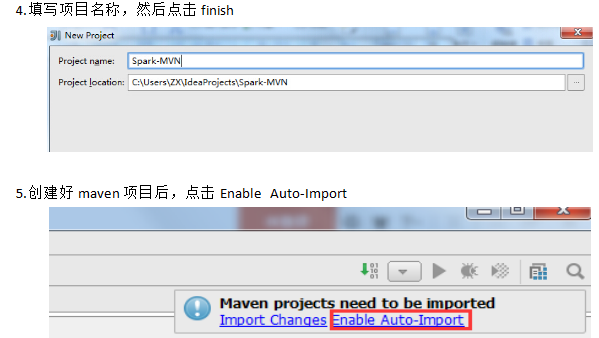
PS: 然后导入配置文件pom.xml
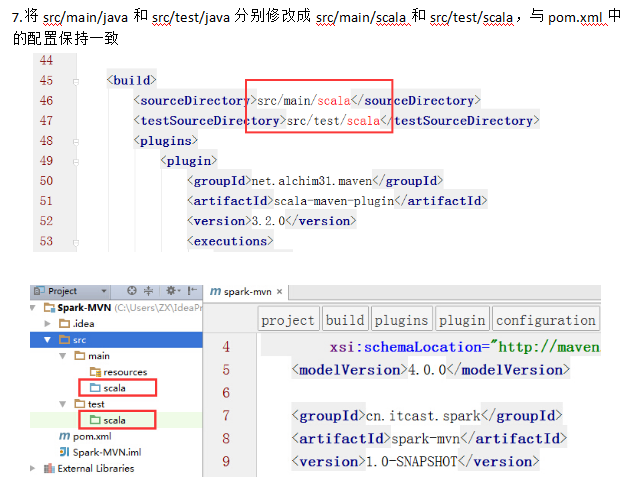
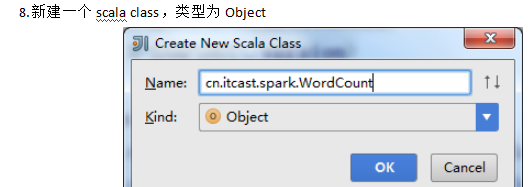
9.编写spark程序 package cn.itcast.spark import org.apache.spark.{SparkContext, SparkConf} object WordCount { def main(args: Array[String]) { //创建SparkConf()并设置App名称 val conf = new SparkConf().setAppName("WC") //创建SparkContext,该对象是提交spark App的入口 val sc = new SparkContext(conf) //使用sc创建RDD并执行相应的transformation和action sc.textFile(args(0)).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_, 1).sortBy(_._2, false).saveAsTextFile(args(1)) //停止sc,结束该任务 sc.stop() } }
PS:没有插件请看:https://jingyan.baidu.com/article/c910274bb6905bcd361d2d8b.html
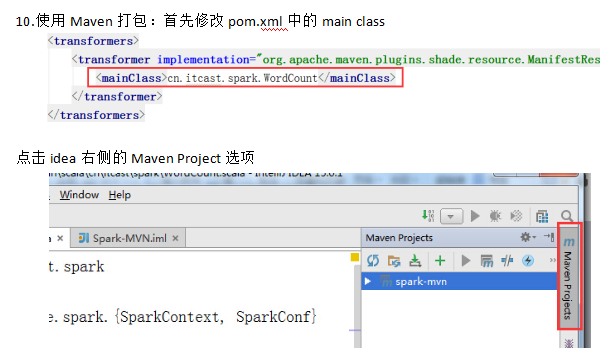
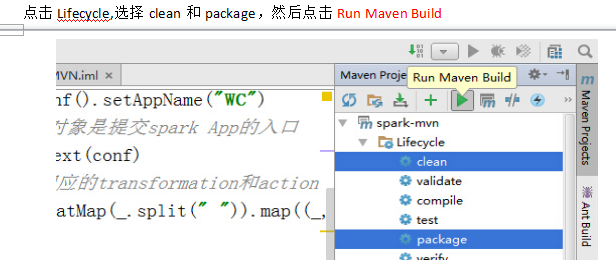
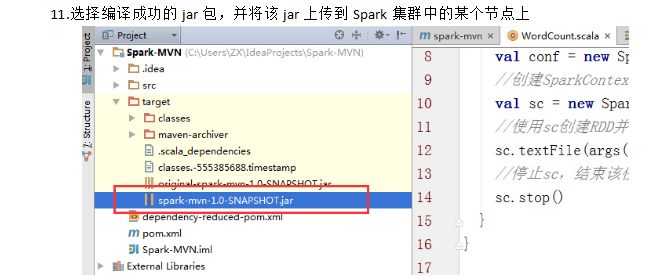
6.首先启动hdfs和Spark集群
启动hdfs
/usr/local/hadoop-2.6.1/sbin/start-dfs.sh
启动spark
/usr/local/spark-1.5.2-bin-hadoop2.6/sbin/start-all.sh
7.使用spark-submit命令提交Spark应用(注意参数的顺序)
/usr/local/spark-1.5.2-bin-hadoop2.6/bin/spark-submit
--class cn.itcast.spark.WordCount
--master spark://node1.itcast.cn:7077
--executor-memory 2G
--total-executor-cores 4
/root/spark-mvn-1.0-SNAPSHOT.jar
hdfs://node1.itcast.cn:9000/words.txt
hdfs://node1.itcast.cn:9000/out
查看程序执行结果
hdfs dfs -cat hdfs://node1.itcast.cn:9000/out/part-00000
(hello,6)
(tom,3)
(kitty,2)
(jerry,1)
-------------------------------Day2 主要讲了Rdd算子和几个例子
http://homepage.cs.latrobe.edu.au/zhe/ZhenHeSparkRDDAPIExamples.html map是对每个元素操作, mapPartitions是对其中的每个partition操作 ------------------------------------------------------------------------------------------- ------------------------------------------------------------------------------------------- mapPartitionsWithIndex : 把每个partition中的分区号和对应的值拿出来, 看源码 val func = (index: Int, iter: Iterator[(Int)]) => { iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator } val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2) rdd1.mapPartitionsWithIndex(func).collect ------------------------------------------------------------------------------------------- ------------------------------------------------------------------------------------------- aggregate def func1(index: Int, iter: Iterator[(Int)]) : Iterator[String] = { iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator } val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2) rdd1.mapPartitionsWithIndex(func1).collect ###是action操作, 第一个参数是初始值, 二:是2个函数[每个函数都是2个参数(第一个参数:先对个个分区进行合并, 第二个:对个个分区合并后的结果再进行合并), 输出一个参数] ###0 + (0+1+2+3+4 + 0+5+6+7+8+9) rdd1.aggregate(0)(_+_, _+_) rdd1.aggregate(0)(math.max(_, _), _ + _) ###5和1比, 得5再和234比得5 --> 5和6789比,得9 --> 5 + (5+9) rdd1.aggregate(5)(math.max(_, _), _ + _) val rdd2 = sc.parallelize(List("a","b","c","d","e","f"),2) def func2(index: Int, iter: Iterator[(String)]) : Iterator[String] = { iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator } rdd2.aggregate("")(_ + _, _ + _) rdd2.aggregate("=")(_ + _, _ + _) val rdd3 = sc.parallelize(List("12","23","345","4567"),2) rdd3.aggregate("")((x,y) => math.max(x.length, y.length).toString, (x,y) => x + y) val rdd4 = sc.parallelize(List("12","23","345",""),2) rdd4.aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y) val rdd5 = sc.parallelize(List("12","23","","345"),2) rdd5.aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y) ------------------------------------------------------------------------------------------- ------------------------------------------------------------------------------------------- aggregateByKey val pairRDD = sc.parallelize(List( ("cat",2), ("cat", 5), ("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)), 2) def func2(index: Int, iter: Iterator[(String, Int)]) : Iterator[String] = { iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator } pairRDD.mapPartitionsWithIndex(func2).collect pairRDD.aggregateByKey(0)(math.max(_, _), _ + _).collect pairRDD.aggregateByKey(100)(math.max(_, _), _ + _).collect ------------------------------------------------------------------------------------------- ------------------------------------------------------------------------------------------- checkpoint sc.setCheckpointDir("hdfs://node-1.itcast.cn:9000/ck") val rdd = sc.textFile("hdfs://node-1.itcast.cn:9000/wc").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_) rdd.checkpoint rdd.isCheckpointed rdd.count rdd.isCheckpointed rdd.getCheckpointFile ------------------------------------------------------------------------------------------- ------------------------------------------------------------------------------------------- coalesce, repartition val rdd1 = sc.parallelize(1 to 10, 10) val rdd2 = rdd1.coalesce(2, false) rdd2.partitions.length ------------------------------------------------------------------------------------------- ------------------------------------------------------------------------------------------- collectAsMap : Map(b -> 2, a -> 1) val rdd = sc.parallelize(List(("a", 1), ("b", 2))) rdd.collectAsMap ------------------------------------------------------------------------------------------- ------------------------------------------------------------------------------------------- combineByKey : 和reduceByKey是相同的效果 ###第一个参数x:原封不动取出来, 第二个参数:是函数, 局部运算, 第三个:是函数, 对局部运算后的结果再做运算 ###每个分区中每个key中value中的第一个值, (hello,1)(hello,1)(good,1)-->(hello(1,1),good(1))-->x就相当于hello的第一个1, good中的1 val rdd1 = sc.textFile("hdfs://master:9000/wordcount/input/").flatMap(_.split(" ")).map((_, 1)) val rdd2 = rdd1.combineByKey(x => x, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n) rdd1.collect rdd2.collect ###当input下有3个文件时(有3个block块, 不是有3个文件就有3个block, ), 每个会多加3个10 val rdd3 = rdd1.combineByKey(x => x + 10, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n) rdd3.collect val rdd4 = sc.parallelize(List("dog","cat","gnu","salmon","rabbit","turkey","wolf","bear","bee"), 3) val rdd5 = sc.parallelize(List(1,1,2,2,2,1,2,2,2), 3) val rdd6 = rdd5.zip(rdd4) val rdd7 = rdd6.combineByKey(List(_), (x: List[String], y: String) => x :+ y, (m: List[String], n: List[String]) => m ++ n) ------------------------------------------------------------------------------------------- ------------------------------------------------------------------------------------------- countByKey val rdd1 = sc.parallelize(List(("a", 1), ("b", 2), ("b", 2), ("c", 2), ("c", 1))) rdd1.countByKey rdd1.countByValue ------------------------------------------------------------------------------------------- ------------------------------------------------------------------------------------------- filterByRange val rdd1 = sc.parallelize(List(("e", 5), ("c", 3), ("d", 4), ("c", 2), ("a", 1))) val rdd2 = rdd1.filterByRange("b", "d") rdd2.collect ------------------------------------------------------------------------------------------- ------------------------------------------------------------------------------------------- flatMapValues : Array((a,1), (a,2), (b,3), (b,4)) val rdd3 = sc.parallelize(List(("a", "1 2"), ("b", "3 4"))) val rdd4 = rdd3.flatMapValues(_.split(" ")) rdd4.collect ------------------------------------------------------------------------------------------- ------------------------------------------------------------------------------------------- foldByKey val rdd1 = sc.parallelize(List("dog", "wolf", "cat", "bear"), 2) val rdd2 = rdd1.map(x => (x.length, x)) val rdd3 = rdd2.foldByKey("")(_+_) val rdd = sc.textFile("hdfs://node-1.itcast.cn:9000/wc").flatMap(_.split(" ")).map((_, 1)) rdd.foldByKey(0)(_+_) ------------------------------------------------------------------------------------------- ------------------------------------------------------------------------------------------- foreachPartition val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 3) rdd1.foreachPartition(x => println(x.reduce(_ + _))) ------------------------------------------------------------------------------------------- ------------------------------------------------------------------------------------------- keyBy : 以传入的参数做key val rdd1 = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3) val rdd2 = rdd1.keyBy(_.length) rdd2.collect ------------------------------------------------------------------------------------------- ------------------------------------------------------------------------------------------- keys values val rdd1 = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), 2) val rdd2 = rdd1.map(x => (x.length, x)) rdd2.keys.collect rdd2.values.collect ------------------------------------------------------------------------------------------- ------------------------------------------------------------------------------------------- mapPartitions
PS:例子
package cn.itcast.spark.day2 import java.net.URL import org.apache.spark.{SparkConf, SparkContext} /** * 根据指定的学科, 取出点击量前三的 * Created by root on 2016/5/16. */ object AdvUrlCount { def main(args: Array[String]) { //从数据库中加载规则 val arr = Array("java.itcast.cn", "php.itcast.cn", "net.itcast.cn") val conf = new SparkConf().setAppName("AdvUrlCount").setMaster("local[2]") val sc = new SparkContext(conf) //rdd1将数据切分,元组中放的是(URL, 1) val rdd1 = sc.textFile("c://itcast.log").map(line => { val f = line.split(" ") (f(1), 1) }) val rdd2 = rdd1.reduceByKey(_ + _) val rdd3 = rdd2.map(t => { val url = t._1 val host = new URL(url).getHost (host, url, t._2) }) //println(rdd3.collect().toBuffer) // val rddjava = rdd3.filter(_._1 == "java.itcast.cn") // val sortdjava = rddjava.sortBy(_._3, false).take(3) // val rddphp = rdd3.filter(_._1 == "php.itcast.cn") for (ins <- arr) { val rdd = rdd3.filter(_._1 == ins) val result= rdd.sortBy(_._3, false).take(3) //通过JDBC向数据库中存储数据 //id,学院,URL,次数, 访问日期 println(result.toBuffer) } //println(sortdjava.toBuffer) sc.stop() } }
Day3
PS:讲解几个小案例,和spark调用数据库,wordcount执行过程
package cn.itcast.spark.day1 import org.apache.spark.{SparkConf, SparkContext} /** * Created by root on 2016/5/14. */ object WordCount { def main(args: Array[String]) { //非常重要,是通向Spark集群的入口 val conf = new SparkConf().setAppName("WC") .setJars(Array("C:\HelloSpark\target\hello-spark-1.0.jar")) .setMaster("spark://node-1.itcast.cn:7077") val sc = new SparkContext(conf) //textFile会产生两个RDD:HadoopRDD -> MapPartitinsRDD sc.textFile(args(0)).cache() // 产生一个RDD :MapPartitinsRDD .flatMap(_.split(" ")) //产生一个RDD MapPartitionsRDD .map((_, 1)) //产生一个RDD ShuffledRDD .reduceByKey(_+_) //产生一个RDD: mapPartitions .saveAsTextFile(args(1)) sc.stop() } }
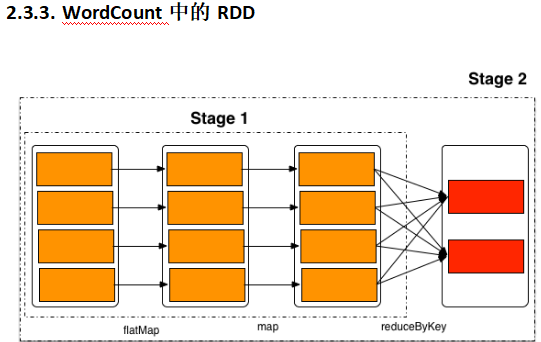
PS:wordcount会经历这些流程(RDD),跟MapReduce差不多,只是数据模型不同
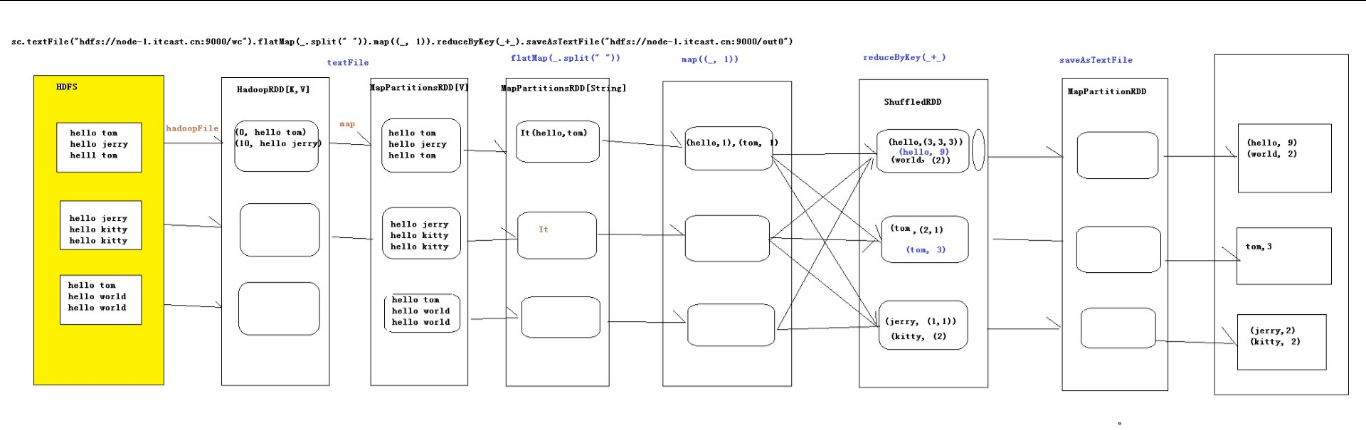
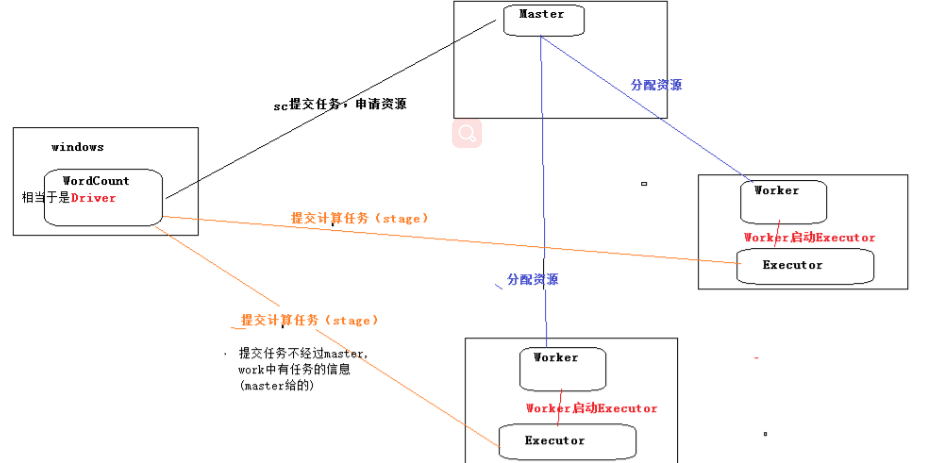
PS:Spark集群提交任务的过程与MapReduce类似






2.3.4.练习 启动spark-shell /usr/local/spark-1.5.2-bin-hadoop2.6/bin/spark-shell --master spark://node1.itcast.cn:7077 练习1: //通过并行化生成rdd val rdd1 = sc.parallelize(List(5, 6, 4, 7, 3, 8, 2, 9, 1, 10)) //对rdd1里的每一个元素乘2然后排序 val rdd2 = rdd1.map(_ * 2).sortBy(x => x, true) //过滤出大于等于十的元素 val rdd3 = rdd2.filter(_ >= 10) //将元素以数组的方式在客户端显示 rdd3.collect 练习2: val rdd1 = sc.parallelize(Array("a b c", "d e f", "h i j")) //将rdd1里面的每一个元素先切分在压平 val rdd2 = rdd1.flatMap(_.split(' ')) rdd2.collect 练习3: val rdd1 = sc.parallelize(List(5, 6, 4, 3)) val rdd2 = sc.parallelize(List(1, 2, 3, 4)) //求并集 val rdd3 = rdd1.union(rdd2) //求交集 val rdd4 = rdd1.intersection(rdd2) //去重 rdd3.distinct.collect rdd4.collect 练习4: val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2))) val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2))) //求jion val rdd3 = rdd1.join(rdd2) rdd3.collect //求并集 val rdd4 = rdd1 union rdd2 //按key进行分组 rdd4.groupByKey rdd4.collect 练习5: val rdd1 = sc.parallelize(List(("tom", 1), ("tom", 2), ("jerry", 3), ("kitty", 2))) val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2))) //cogroup val rdd3 = rdd1.cogroup(rdd2) //注意cogroup与groupByKey的区别 rdd3.collect 练习6: val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5)) //reduce聚合 val rdd2 = rdd1.reduce(_ + _) rdd2.collect 练习7: val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2), ("shuke", 1))) val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 3), ("shuke", 2), ("kitty", 5))) val rdd3 = rdd1.union(rdd2) //按key进行聚合 val rdd4 = rdd3.reduceByKey(_ + _) rdd4.collect //按value的降序排序 val rdd5 = rdd4.map(t => (t._2, t._1)).sortByKey(false).map(t => (t._2, t._1)) rdd5.collect //想要了解更多,访问下面的地址 http://homepage.cs.latrobe.edu.au/zhe/ZhenHeSparkRDDAPIExamples.html
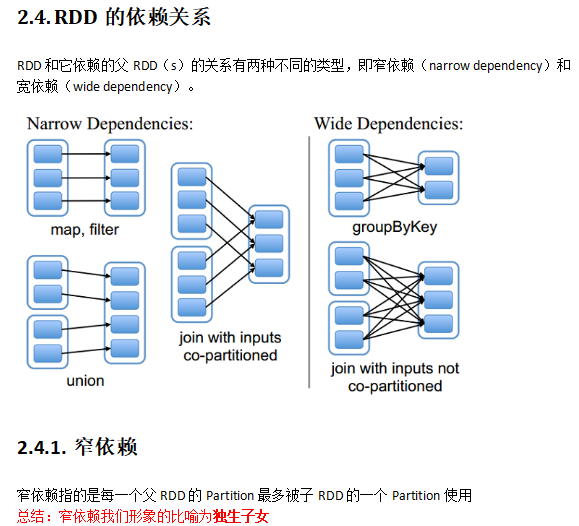



PS:Checkpoint保证了数据的 高可用。
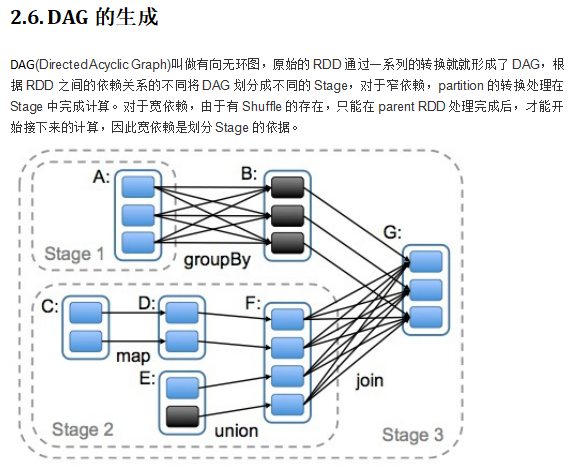
PS:Sprak Stage
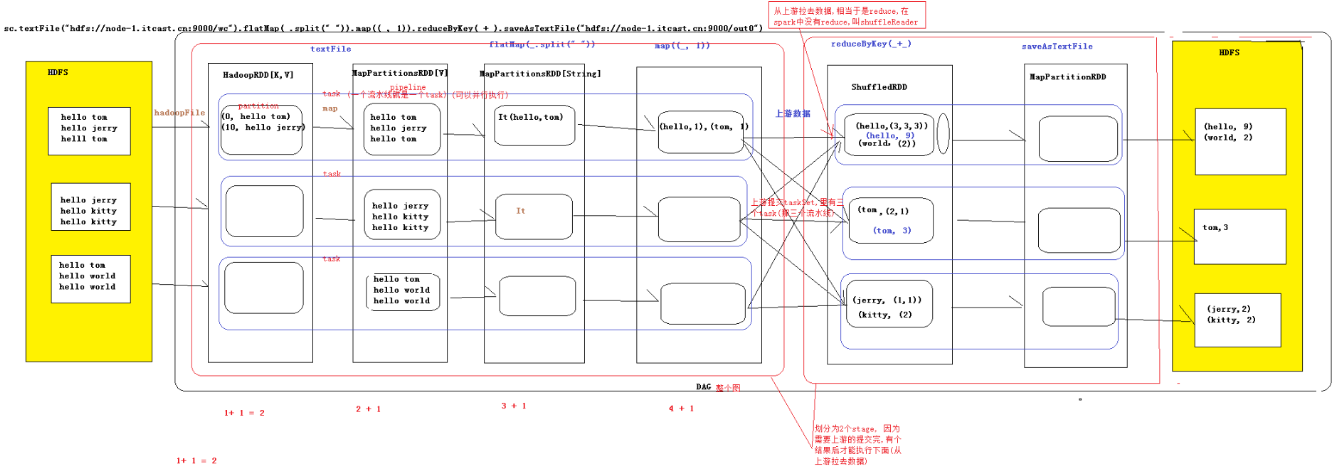

PS:我觉得,rdd那种编程方式比较难,所以用spark sql 来简化翻译成rdd的编程模式。


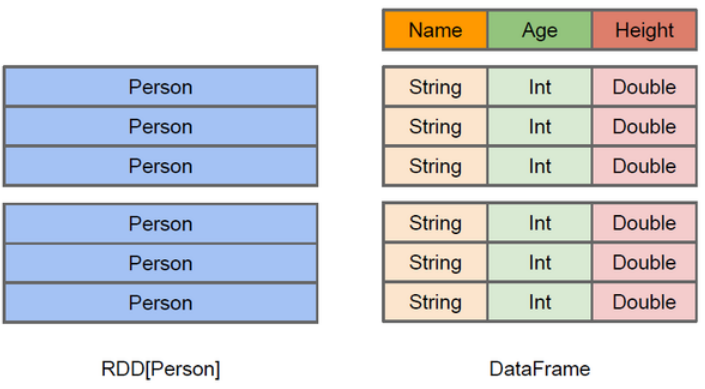
PS:将文件中复杂的数据生成表格,同时进行查询。
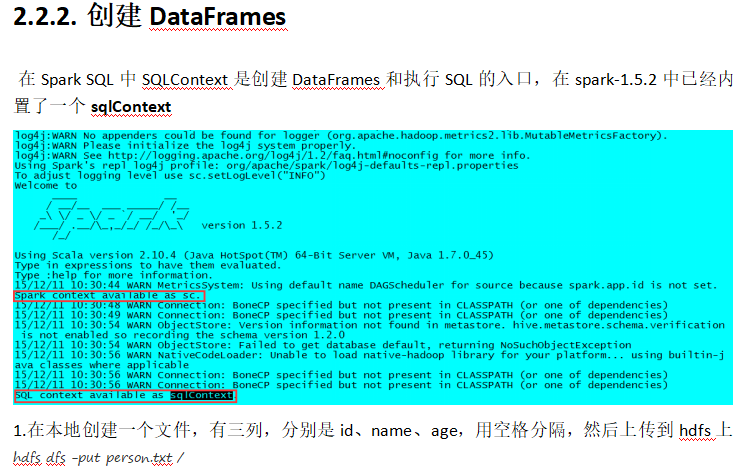

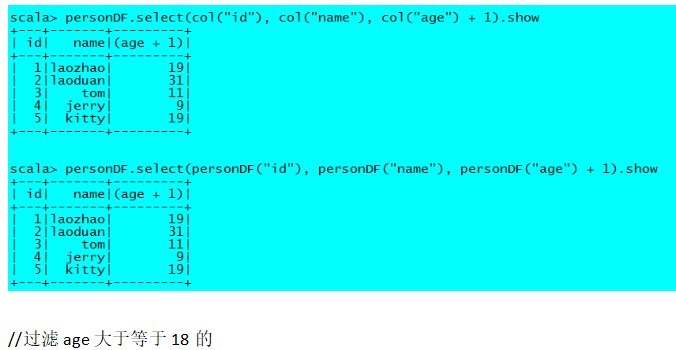
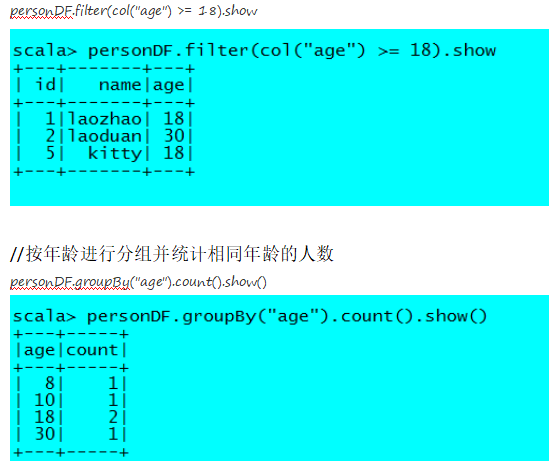
PS:DataFrame有两种风格的语法表达


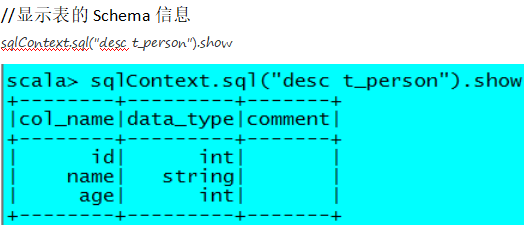

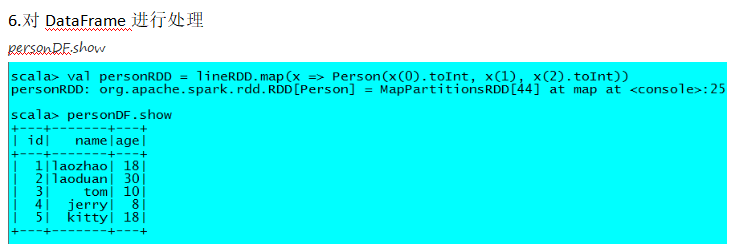
package cn.itcast.spark.sql import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.sql.SQLContext object InferringSchema { def main(args: Array[String]) { //创建SparkConf()并设置App名称 val conf = new SparkConf().setAppName("SQL-1") //SQLContext要依赖SparkContext val sc = new SparkContext(conf) //创建SQLContext val sqlContext = new SQLContext(sc) //从指定的地址创建RDD val lineRDD = sc.textFile(args(0)).map(_.split(" ")) //创建case class //将RDD和case class关联 val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt)) //导入隐式转换,如果不到人无法将RDD转换成DataFrame //将RDD转换成DataFrame import sqlContext.implicits._ val personDF = personRDD.toDF //注册表 personDF.registerTempTable("t_person") //传入SQL val df = sqlContext.sql("select * from t_person order by age desc limit 2") //将结果以JSON的方式存储到指定位置 df.write.json(args(1)) //停止Spark Context sc.stop() } } //case class一定要放到外面 case class Person(id: Int, name: String, age: Int)
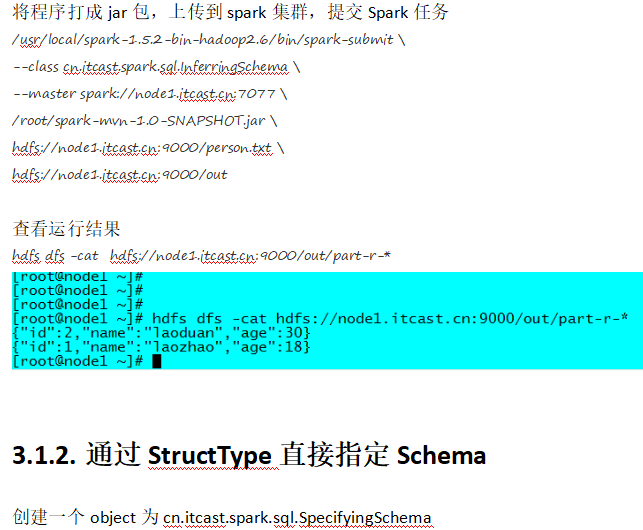
package cn.itcast.spark.sql import org.apache.spark.sql.{Row, SQLContext} import org.apache.spark.sql.types._ import org.apache.spark.{SparkContext, SparkConf} /** * Created by ZX on 2015/12/11. */ object SpecifyingSchema { def main(args: Array[String]) { //创建SparkConf()并设置App名称 val conf = new SparkConf().setAppName("SQL-2") //SQLContext要依赖SparkContext val sc = new SparkContext(conf) //创建SQLContext val sqlContext = new SQLContext(sc) //从指定的地址创建RDD val personRDD = sc.textFile(args(0)).map(_.split(" ")) //通过StructType直接指定每个字段的schema val schema = StructType( List( StructField("id", IntegerType, true), StructField("name", StringType, true), StructField("age", IntegerType, true) ) ) //将RDD映射到rowRDD val rowRDD = personRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).toInt)) //将schema信息应用到rowRDD上 val personDataFrame = sqlContext.createDataFrame(rowRDD, schema) //注册表 personDataFrame.registerTempTable("t_person") //执行SQL val df = sqlContext.sql("select * from t_person order by age desc limit 4") //将结果以JSON的方式存储到指定位置 df.write.json(args(1)) //停止Spark Context sc.stop() } }
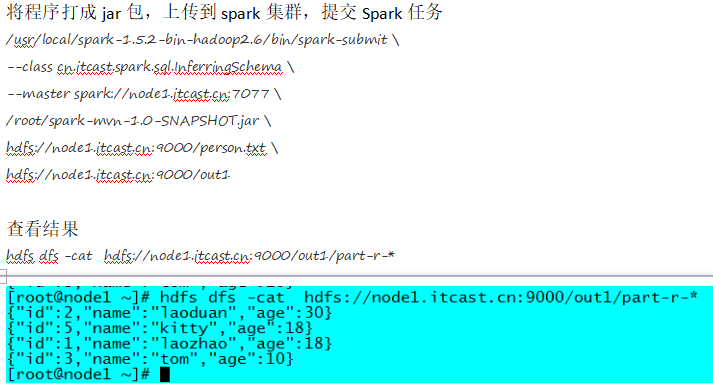

PS:Spark sQL支持很多数据源,上面的都支持


package cn.itcast.spark.sql import java.util.Properties import org.apache.spark.sql.{SQLContext, Row} import org.apache.spark.sql.types.{StringType, IntegerType, StructField, StructType} import org.apache.spark.{SparkConf, SparkContext} object JdbcRDD { def main(args: Array[String]) { val conf = new SparkConf().setAppName("MySQL-Demo") val sc = new SparkContext(conf) val sqlContext = new SQLContext(sc) //通过并行化创建RDD val personRDD = sc.parallelize(Array("1 tom 5", "2 jerry 3", "3 kitty 6")).map(_.split(" ")) //通过StructType直接指定每个字段的schema val schema = StructType( List( StructField("id", IntegerType, true), StructField("name", StringType, true), StructField("age", IntegerType, true) ) ) //将RDD映射到rowRDD val rowRDD = personRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).toInt)) //将schema信息应用到rowRDD上 val personDataFrame = sqlContext.createDataFrame(rowRDD, schema) //创建Properties存储数据库相关属性 val prop = new Properties() prop.put("user", "root") prop.put("password", "123456") //将数据追加到数据库 personDataFrame.write.mode("append").jdbc("jdbc:mysql://192.168.10.1:3306/bigdata", "bigdata.person", prop) //停止SparkContext sc.stop() } }

-------------------Day 5 Spark Streaming
PS:最早的时候离线式的数据处理是MapReduce完成的,后来升级为Hive;实时计算使用的Storm
但是现在Spark提供的了一站式的解决方案。 如果想处理离线的数据可以使用RDD,也可以使用Spark Sql; 实时数据处理可以采用spark Streaming
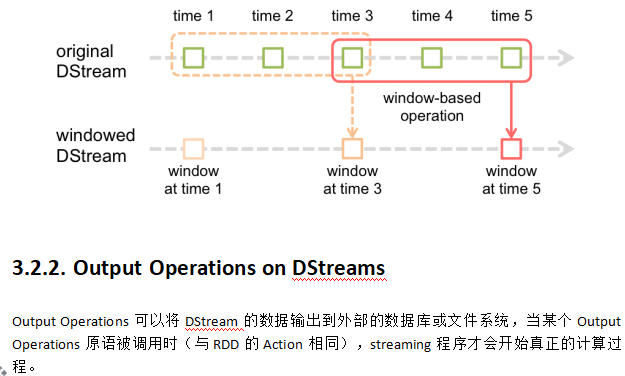
PS:其实Spark Streaming就是连续的RDD,很多个RDD被称为DStream,今后我们就操作这些DStream

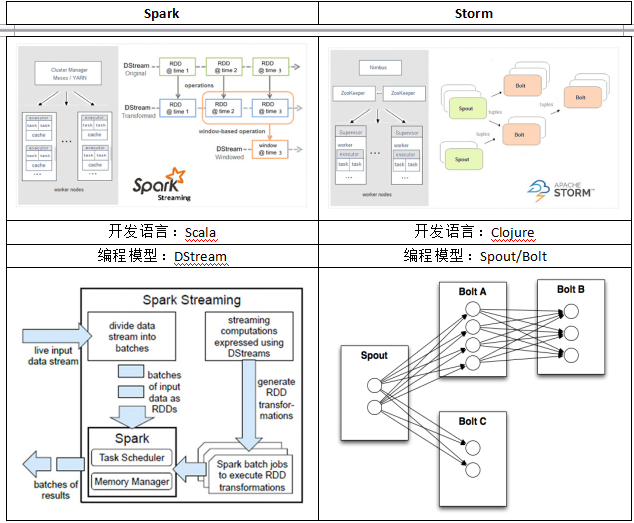
1.1.1. Spark与Storm的对比

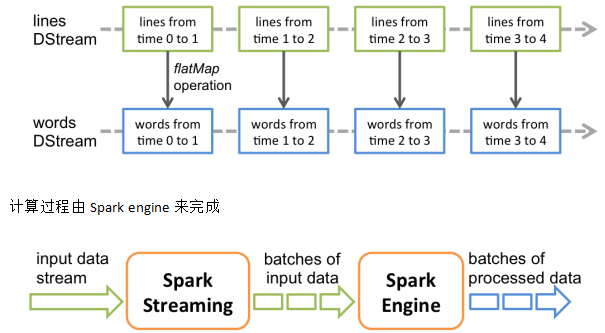

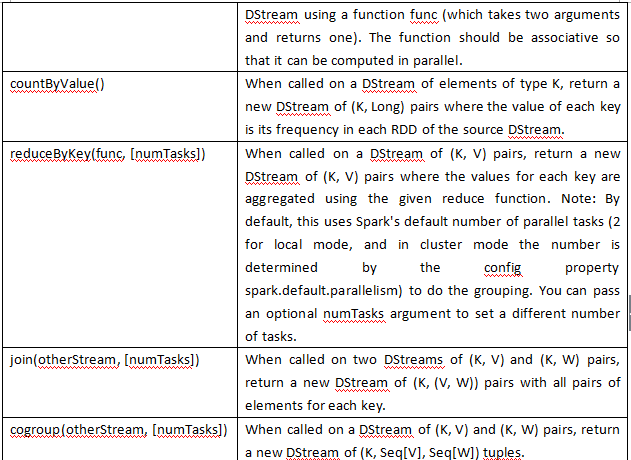


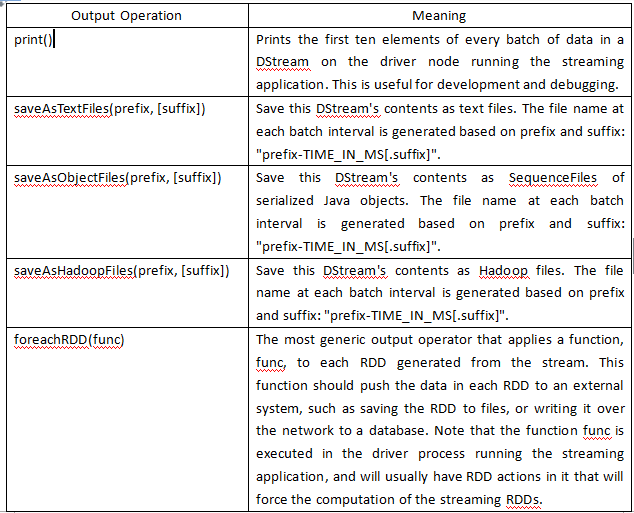

PS: 不停的写数据
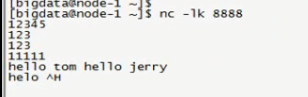
package cn.itcast.spark.day5 import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.streaming.{Seconds, StreamingContext} /** * Created by root on 2016/5/21. */ object StreamingWordCount { def main(args: Array[String]) { LoggerLevels.setStreamingLogLevels()//设置日志,记录日志 //StreamingContext val conf = new SparkConf().setAppName("StreamingWordCount").setMaster("local[2]") val sc = new SparkContext(conf) val ssc = new StreamingContext(sc, Seconds(5))//多长时间产生一次数据 //接收数据 val ds = ssc.socketTextStream("172.16.0.11", 8888) //DStream是一个特殊的RDD //hello tom hello jerry; flatMap是一行一行的 val result = ds.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_) //打印结果 result.print() ssc.start() ssc.awaitTermination() } }
package cn.itcast.spark.day5 import org.apache.log4j.{Logger, Level} import org.apache.spark.Logging object LoggerLevels extends Logging { def setStreamingLogLevels() { val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements if (!log4jInitialized) { logInfo("Setting log level to [WARN] for streaming example." + " To override add a custom log4j.properties to the classpath.") Logger.getRootLogger.setLevel(Level.WARN) } } }
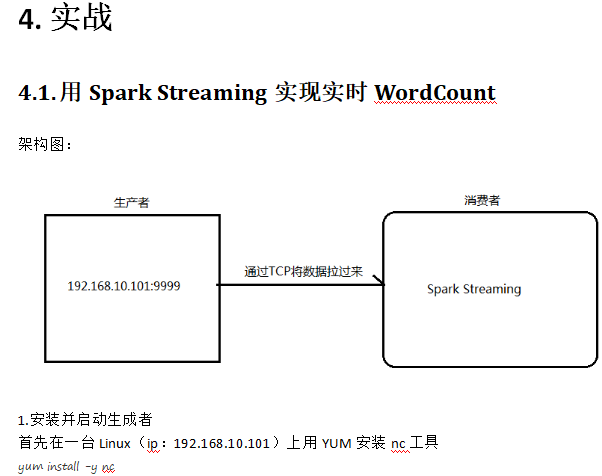
PS:客户端拿到数据

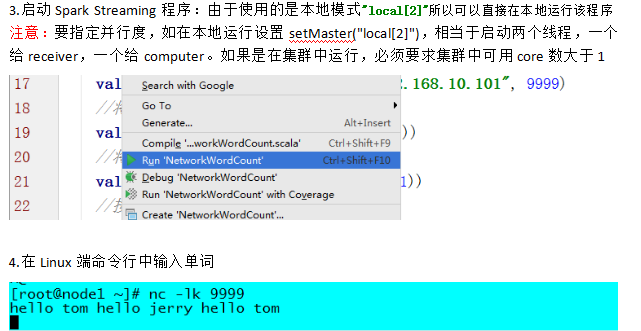

package cn.itcast.spark.day5 import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} /** * Created by root on 2016/5/21. */ object StateFulWordCount { //Seq这个批次某个单词的次数 //Option[Int]:以前的结果 //分好组的数据 val updateFunc = (iter: Iterator[(String, Seq[Int], Option[Int])]) => { //iter.flatMap(it=>Some(it._2.sum + it._3.getOrElse(0)).map(x=>(it._1,x))) //iter.map{case(x,y,z)=>Some(y.sum + z.getOrElse(0)).map(m=>(x, m))} //iter.map(t => (t._1, t._2.sum + t._3.getOrElse(0))) iter.map{ case(word, current_count, history_count) => (word, current_count.sum + history_count.getOrElse(0)) } } def main(args: Array[String]) { LoggerLevels.setStreamingLogLevels() //StreamingContext val conf = new SparkConf().setAppName("StateFulWordCount").setMaster("local[2]") val sc = new SparkContext(conf) //updateStateByKey必须设置setCheckpointDir sc.setCheckpointDir("c://ck") val ssc = new StreamingContext(sc, Seconds(5)) val ds = ssc.socketTextStream("172.16.0.11", 8888) //DStream是一个特殊的RDD //hello tom hello jerry val result = ds.flatMap(_.split(" ")).map((_, 1)).updateStateByKey(updateFunc, new HashPartitioner(sc.defaultParallelism), true) result.print() ssc.start() ssc.awaitTermination() } }
PS:Spark Streaming的结合详细看项目的介绍。