Hive Documentation
https://cwiki.apache.org/confluence/display/Hive/Home
2016-12-22 14:52:41
ANTLR (ANother Tool for Language Recognition)
2017-03-22 16:15:48
Hive Anatomy(解剖):https://www.slideshare.net/nzhang/hive-anatomy
Hive SQL的编译过程:http://tech.meituan.com/hive-sql-to-mapreduce.html
YSmart: Yet Another SQL-to-MapReduce Translator
http://web.cse.ohio-state.edu/hpcs/WWW/HTML/publications/papers/TR-11-7.pdf
https://github.com/YSmart/YSmart
2017-05-24 19:23:27
Add/Replace Columns Cascade
ALTER TABLE table_name [PARTITION partition_spec] -- (Note: Hive 0.14.0 and later) ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...) [CASCADE|RESTRICT] -- (Note: Hive 1.1.0 and later)The CASCADE|RESTRICT clause is available in Hive 1.1.0. ALTER TABLE ADD|REPLACE COLUMNS with CASCADE command changes the columns of a table's metadata, and cascades the same change to all the partition metadata. RESTRICT is the default, limiting column changes only to table metadata.
问题:hive分区表增加字段后,历史分区再重新插入数据,这些增加的字段在HDFS文件中有数据,但查询时仍然为空的问题。
问题的原因就是hive元数据没有更新,加上cascade参数,可以解决该问题。
2017-04-24 19:10:51
hive -v -e ""
-v,--verbose Verbose mode (echo executed SQL to the console) 冗长的/啰嗦的模式;在控制台打印被执行的SQL。
2017-01-21 10:37:40
Windowing and Analytics Functions
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+WindowingAndAnalytics
Enhanced Aggregation, Cube, Grouping and Rollup
https://cwiki.apache.org/confluence/display/Hive/Enhanced+Aggregation%2C+Cube%2C+Grouping+and+Rollup
2017-02-24 09:13:10
public static enum ConfVars { HIVE_WAREHOUSE_SUBDIR_INHERIT_PERMS("hive.warehouse.subdir.inherit.perms", true, "Set this to false if the table directories should be created\n" + "with the permissions derived from dfs umask instead of\n" + "inheriting the permission of the warehouse or database directory.") }
2017-01-16 21:31:02
hive null 比较的问题
《Why NULL never compares false to anything in SQL》:https://www.xaprb.com/blog/2006/05/18/why-null-never-compares-false-to-anything-in-sql/
《Null (SQL)》:https://en.wikipedia.org/wiki/Null_(SQL)
1、where col <> '1.2' -- 会把null过滤掉 2、select case when '1.0.8' < null then '1.0.8' else null end as min_value -- null ,case when '1.0.8' > null then '1.0.8' else null end as max_value -- null ,case when '1.0.8' < null then null else '1.0.8' end as min_value -- '1.0.8' ,case when '1.0.8' > null then null else '1.0.8' end as max_value -- '1.0.8' ,case when null < '1.0.8' then null else '1.0.8' end as min_value -- '1.0.8' ,case when null > '1.0.8' then null else '1.0.8' end as max_value -- '1.0.8' ,case when null < '1.0.8' then '1.0.8' else null end as min_value -- null ,case when null > '1.0.8' then '1.0.8' else null end as max_value -- null from temp.dual ; 3、select '1.0.8' < null -- null ,'1.0.8' > null -- null ,null < '1.0.8' -- null ,null > '1.0.8' -- null from temp.dual ; 4、where col in ('','-',null) -- null不会被查出来 5、case when min_value in (null) then 'null_value' else min_value end -- null
6、注意:count(col), min(col), max(col), avg(col), sum(col) 会忽略空置,count(*) 除外、count(*) 统计行数,例子如下:
SELECT * FROM temp.temp_test_table;
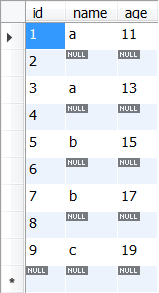
SELECT
COUNT(*) AS count_all,
COUNT(id) AS count_id,
COUNT(name) AS count_name,
COUNT(DISTINCT id) AS count_distinct_id,
COUNT(DISTINCT name) AS count_distinct_name,
COUNT(DISTINCT id, name) AS count_distinct_all
FROM
temp.temp_test_table;

SELECT
MIN(id) AS min_id,
MIN(age) AS min_age,
MAX(id) AS max_id,
MAX(age) AS max_age,
AVG(age) AS avg_age,
SUM(age) AS sum_age
FROM
temp.temp_test_table;

SELECT
id, name, age
FROM
temp.temp_test_table
GROUP BY id , name , age;
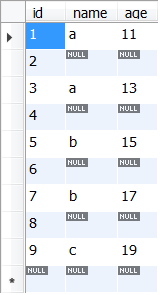
SELECT
name,
COUNT(*) AS count_row,
COUNT(age) AS count_age,
COUNT(DISTINCT age) AS count_distinct_age,
MAX(age) AS max_age,
MIN(age) AS min_age,
AVG(age) AS avg_age,
SUM(age) AS sum_age
FROM
temp.temp_test_table
GROUP BY name;

2016-12-15 22:59:16
UDF
《LanguageManual UDF》:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
import java.net.MalformedURLException; import java.net.URL; import java.util.regex.Matcher; import java.util.regex.Pattern; public class TestUDFParseUrl { public static void main(String[] args) { try { URL url = new URL("http://le.com?a=1&b=2&c=3"); String query = url.getQuery(); System.out.println(query);//a=1&b=2&c=3 Pattern p = Pattern.compile("(&|^)c=([^&]*)"); System.out.println(p);//(&|^)c=([^&]*) Matcher m = p.matcher(query); if (m.find()) { System.out.println(m);//java.util.regex.Matcher[pattern=(&|^)c=([^&]*) region=0,11 lastmatch=&c=3] System.out.println(m.group(0));//&c=3 System.out.println(m.group(1));//& System.out.println(m.group(2));//3 } } catch (MalformedURLException e) { e.printStackTrace(); } } }
2016-12-11 15:12:34
SerDe
问题:MapReduce写出的Hive Map类型字段,使用 hive SQL 查询时报错,但使用 hive --rcfilecat 命令可以查看。
经测试发现是hive表SerDe设置的问题,
当SerDe为 org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe 时,使用 hive SQL 查询报错如下:
org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.ArrayIndexOutOfBoundsException
当SerDe为 org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe 时,使用 hive SQL 查询报错如下:
java.lang.ClassCastException: org.apache.hadoop.hive.serde2.columnar.BytesRefArrayWritable cannot be cast to org.apache.hadoop.io.BinaryComparable
当SerDe为 'org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe' 时,使用 hive SQL 查询正常;
set; /* 输出结果中关于SerDe的部分 hive.default.fileformat=TextFile hive.default.rcfile.serde=org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe hive.default.serde=org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe hive.fetch.output.serde=org.apache.hadoop.hive.serde2.DelimitedJSONSerDe hive.script.serde=org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe hive.serdes.using.metastore.for.schema=org.apache.hadoop.hive.ql.io.orc.OrcSerde, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe, org.apache.hadoop.hive.serde2.dynamic_type.DynamicSerDe, org.apache.hadoop.hive.serde2.MetadataTypedColumnsetSerDe, org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, org.apache.hadoop.hive.serde2.lazybinary.LazyBinarySerDe system:java.class.path=/usr/local/hive/lib/hive-serde-1.2.1.jar */
--在以上的环境下测试 drop table if exists temp.temp_map_column_test_table ; create table temp.temp_map_column_test_table ( props map<string,string> ) STORED AS RCFile ; desc formatted temp.temp_map_column_test_table ; --SerDe Library: org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe drop table if exists temp.temp_map_column_test_table2 ; create table temp.temp_map_column_test_table2 ( props map<string,string> ) ROW FORMAT DELIMITED COLLECTION ITEMS TERMINATED BY ',' MAP KEYS TERMINATED BY ':' LINES TERMINATED BY '\n' STORED AS RCFile ; desc formatted temp.temp_map_column_test_table2 ; --SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe drop table if exists temp.temp_map_column_test_table3 ; create table temp.temp_map_column_test_table3 ( props map<string,string> ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe' STORED AS RCFile ; desc formatted temp.temp_map_column_test_table3 ; --SerDe Library: org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe
--1、在建表语句中指定SerDe ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe' --2、修改环境变量 set hive.default.rcfile.serde=org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe ; --3、修改表 alter table temp.temp_map_column_test_table set serde 'org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe' WITH SERDEPROPERTIES ('collected.delim' = ',', 'mapkey.delim' = ':', 'line.delim' = '\n' ); --or alter table temp.temp_map_column_test_table set serde 'org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe'; alter table temp.temp_map_column_test_table set SERDEPROPERTIES ('collected.delim' = ',', 'mapkey.delim' = ':', 'line.delim' = '\n' );
What is a SerDe?
- SerDe is a short name for "Serializer and Deserializer."
- Hive uses SerDe (and FileFormat) to read and write table rows.
- HDFS files --> InputFileFormat --> <key, value> --> Deserializer --> Row object
- Row object --> Serializer --> <key, value> --> OutputFileFormat --> HDFS files
Note that the "key" part is ignored when reading, and is always a constant when writing. Basically row object is stored into the "value".
One principle of Hive is that Hive does not own the HDFS file format. Users should be able to directly read the HDFS files in the Hive tables using other tools or use other tools to directly write to HDFS files that can be loaded into Hive through "CREATE EXTERNAL TABLE" or can be loaded into Hive through "LOAD DATA INPATH," which just move the file into Hive's table directory.
Note that org.apache.hadoop.hive.serde is the deprecated old SerDe library. Please look at org.apache.hadoop.hive.serde2 for the latest version.
https://cwiki.apache.org/confluence/display/Hive/DeveloperGuide#DeveloperGuide-HiveSerDe
2016-12-10 22:34:31
问题:分隔符和ASCII码控制字符导致 串列,串行
1、替换hive默认分隔符
regexp_replace(columnName,'\001|\n','')
2、替换ASCII码控制字符
控制字符:[\x00-\x1F\x7F]
regexp_replace(columnName, '[\\x00-\\x1F\\x7F]','')
0~31及127(共33个)是控制字符或通信专用字符(其余为可显示字符),如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(响铃)等;通信专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等;ASCII值为8、9、10 和13 分别转换为退格、制表、换行和回车字符。它们并没有特定的图形显示,但会依不同的应用程序,而对文本显示有不同的影响。
hive默认分隔符

2016-10-11 21:59:01
Hive常用参数设置
set hive.default.fileformat=rcfile; --将RCFile设置为默认文件格式
set hive.exec.compress.output=true; --压缩输出的数据文件
set hive.map.aggr=true; --在map阶段聚合,提高聚合函数性能
set hive.exec.parallel=true; --并行执行任务
set mapred.max.split.size=268435456; --设置一个map处理的最大文件为256M
set hive.exec.reducers.bytes.per.reducer=134217728; --设置一个reduce处理的最大文件为128M
set hive.exec.dynamic.partition=true; --设置动态分区
set hive.exec.dynamic.partition.mode=nonstrict; --将动态分区模式设为非严格模式
set hive.groupby.skewindata=true; --在group by操作有数据倾斜的时候进行负载均衡
set hive.optimize.skewjoin=true; --在两表关联有数据倾斜时优化
2016-11-13 20:06:57
Hive培训资料

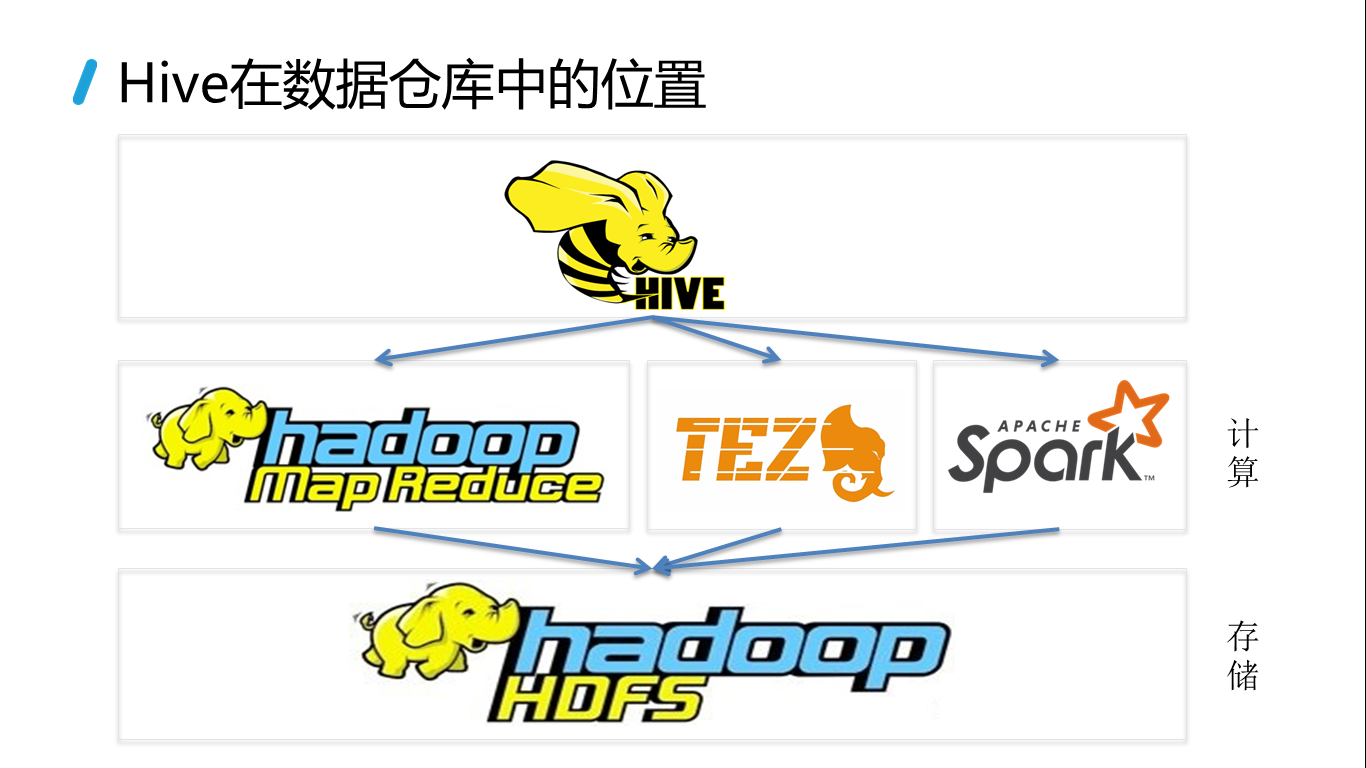
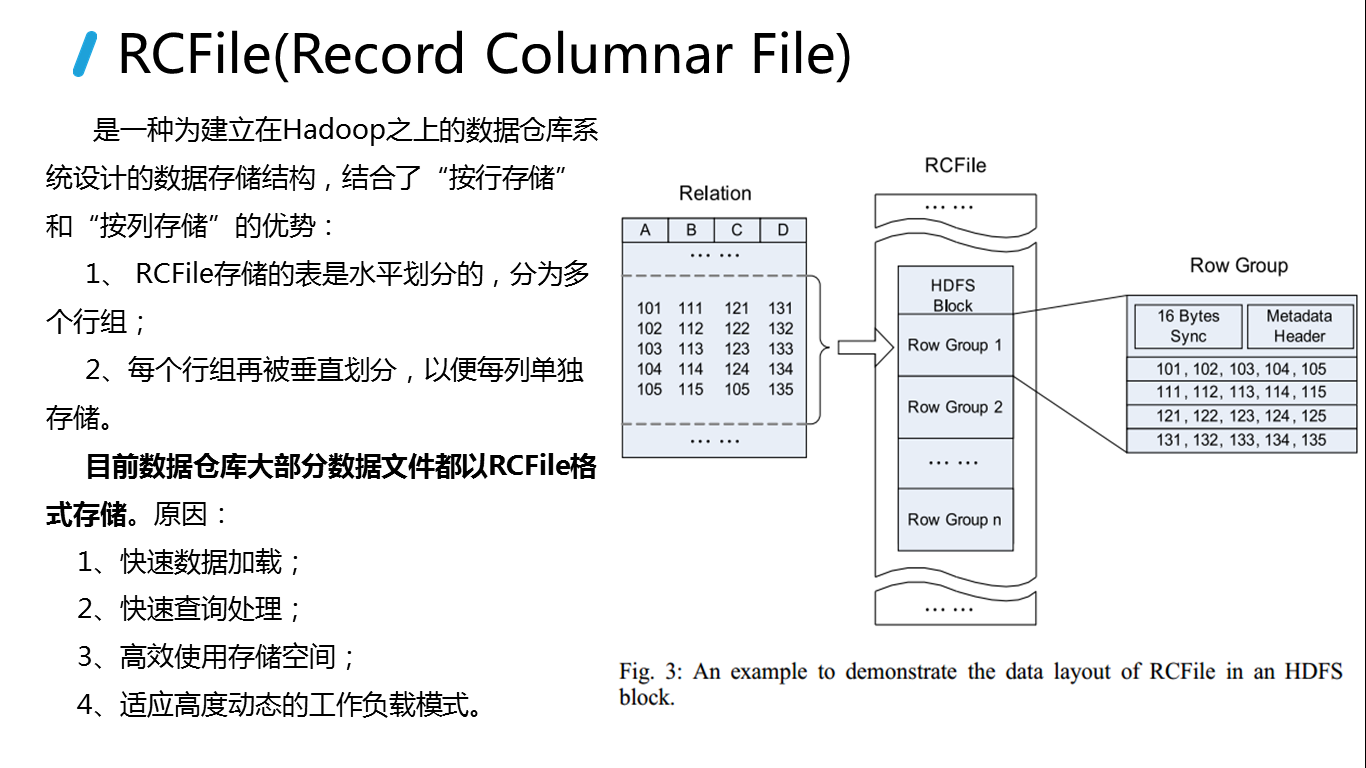







2016-11-27 22:37:24
Hive调优以及发展趋势