逻辑回归
标签(空格分隔): 逻辑回归 吴恩达 分类
1. 基本内容
此处讨论的是二分类问题,即预测值 (yin {0,1}),其中,(0) 代表Negative Class, (1) 代表 Positive Class。
回归一般是预测连续值,分类是预测离散值,但是逻辑回归预测的是离散值,它其实是一个分类问题,称其“回归”是历史问题。
在逻辑回归中,假设函数 (h_ heta(x)) 满足 (0 le h_ heta(x) le 1)。通常选取如下形式:
其中: $$ g(z) = frac{1}{1+e^{-z}}$$
(g(z))的函数图像如下所示:
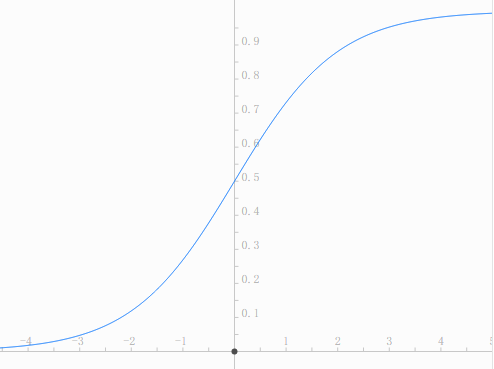
(g(z)) 被称为 Sigmoid 函数或逻辑函数。
此处的假设函数 (h heta(x)) 可以理解为:在参数 ( heta) 下,对输入(x), 预测值 (y) 取值为 (1) 的概率。形式化的表示如下:
显然,有:
对于假设函数 (h_ heta(x) = g( heta^Tx)), 如果当 (h_ heta(x) ge 0.5) 时 预测值 (y=1),(h_ heta(x) < 0.5) 时 预测值 (y=0),则有 ( heta^Tx ge 0) 时 (y = 1),( heta^Tx < 0) 时 (y = 0),
2. 决策边界(Decision Boundary)
决策边界即满足 (h_ heta(x) = 0.5) 的区域,此处的 (0.5) 是阈值。不同的问题决策边界的形状不一样,使用高次的特征可能产生形状复杂的决策边界。例如使用二阶特征(x^2),可能产生圆或椭圆等。
3. 代价函数
对于逻辑回归,代价函数的形式如下:
其中:
注意 (y) 的取值只能是1或者0,上述(Cost)函数可以合并,因此得到新的代价函数表达形式:
4. 梯度下降
梯度下降的目标是最小化代价函数(J( heta))。
过程为:
(注意同时更新所有的 ( heta_j))
解出上式中的偏导数,得到:
(注意同时更新所有的 ( heta_j))
这个形式同线性回归的形似看起来是完全一样的,但是在线性回归中,(h_ heta(x) = heta^Tx), 而在逻辑回归中, (h_ heta(x)=frac{1}{1+e^{- heta^Tx)}}) 。
在逻辑回归中也可以使用特征缩放来加速收敛,另外,选择参数 (alpha) 的方法同线性回归是一样的。
5. 多分类问题
对于将元素分成 (k) 类的问题(即(yin{1, 2, cdots, k})), 训练 (k) 个二分类器 (h_ heta^{(i)}(x)),每次训练时,将第 (k) 类元素分为一类,其余元素分为一类,得到如下结果:
完成上述训练后,在分类时,将输入元素带入每个分类器中,求得 (h_ heta^{(i)}(x)), 根据其物理意义,选取此值最大的一个,即为最可信的分类,故将该元素分入此类。
上述方法将二分类问题的解法运用到了多分类问题中。
6. 欠拟合(Underfitting 或 high bias)与过拟合(Overfitting)及正则化
如果对训练集数据,假设函数产生的结果跟实际结果相比,偏差较大,则称其为欠拟合。反之,如果选取了过多的特征,以致对于训练集数据能产生几乎没有偏差的结果,但是不能很好的泛化到新的数据实例中,则称之为过拟合。
如下图所示(图片均来自吴恩达教授机器学习公开课截图)。
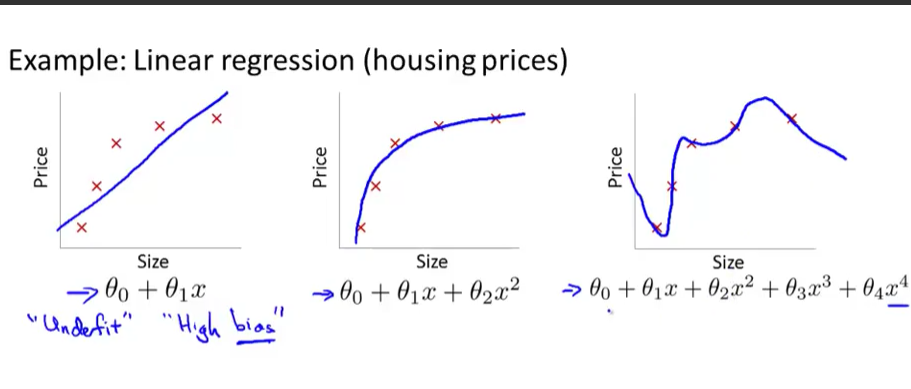
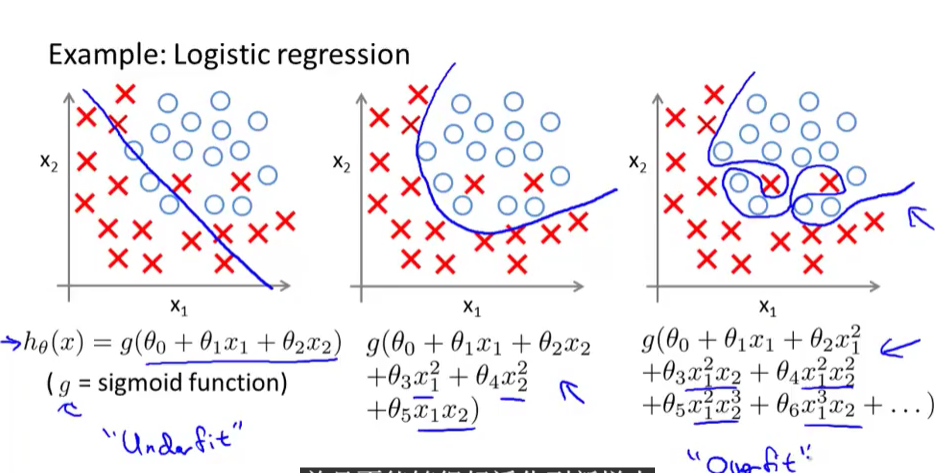
产生过拟合的原因,往往是特征数目太多,相比之下,训练集数据太少导致的。针对其产生原因,解决过拟合问题主要有两个方法,第一个是人工的去掉一些不太重要的属性,使特征数量减少。另一个是正则化,即尽量选取小的参数( heta_j), 使得特征都保留,但每个特征只对最终结果产生较小的影响。正则化是被广泛使用的一个方法。
正则化事实上是在代价函数里增加了惩罚项,例如,如果不希望去掉特性 (x_3), 但是又不想让它影响太大,可以加入正则化项 (1000* heta_3^2) 来惩罚,即当 ( heta_3) 取值较大时,代价函数的值也很大,逼迫 ( heta_3) 只能取趋近于0的值。
现实问题中,用户并不能很清楚的知道哪些特征更重要,哪些不重要,因此加入的正则化项为 (lambda sum_{j=1}^{n} heta_j^2) (注意不包含 ( heta_0), 虽然这没有多大影响,但通常这么写)。使得整体上每个参数取值都比较小。参数较小能使得拟合出来的函数更为光滑(不会证明)。
(lambda) 称为正则化参数,其取值不能过大(会造成欠拟合),也不能过小,有自动选取(lambda) 的方法。
最后,代价函数的形似如下(以线性回归为例):