一、将查询结果插入到另一张表
1. 查询结果插入新表
select * into tableA from tableB where …
2. 查询结果插入已经存在的表
insert into tableA
select * from tableB where…
3. 查询结果跨数据库
insert into schemaA.tableA
select * from schemaB.tableB where…
4.查询结果加上新字段插入已经存在的表
insert into tableA
select *,NULL from tableB where…
二、SQL server列多次指定错误
The column 'saleareaname' was specified multiple times for 't1'.
列"saleareaname‘被多次指定为’t1‘。
错误原因是select后面的多个表中同时具有相同的列名,解决错误的方法是分别给它们取个不同的别名就好了。
连表查询 两个表里面出现了相同的字段,就会报错
三、GETDATE() 获取当前时间
四、锁表及解锁
1、查看所有锁表
select request_session_id spid,OBJECT_NAME(resource_associated_entity_id) tableName
from sys.dm_tran_locks where resource_type='OBJECT'
2、解锁
declare @spid int
Set @spid = 23 --锁表进程
declare @sql varchar(1000)
set @sql='kill '+cast(@spid as varchar)
exec(@sql)
五、该死的空格
摘自:https://www.cnblogs.com/happycat1988/p/4779805.html
最近发现SQLServer中比较字符串的时候 如果字符串末尾是空格 那么SQLServer会无视那些空格直接进行比较 这和程序中平时的字符串判断逻辑不统一
直接等号判断的时候 SQL会无视末尾的空格 但是like却能够正确的比较
虽然用like也是一种方法 不过如果带有%之类的或许会判断错误 不能单单只用like一个判断 不过反正都是要附加一个条件了
有没有什么比like还简单的呢 于是我就想到了用len函数加上字符串长度同时比较 然后就踩了另外一个坑
len函数也是无视末尾空格的 只有用datalength函数才能作为附加的精确判断的依据
查询了MSDN(LEN (Transact-SQL)) 发现len函数的说明是"Returns the number of characters of the specified string expression, excluding trailing blanks." 也就是排除空格比较的 所以要换用datalength
于是乎整理出了一些精确判断字符串的方法
declare @a nvarchar(50);set @a=N'happycat1988'
declare @b nvarchar(50);set @b=N'happycat1988 '
if(@a = @b and datalength(@a)=datalength(@b))
select 'True' as 配合datalength比较
else
select 'False' as 配合datalength比较
if(@a = @b and @a like @b and @b like @a)
select 'True' as 配合like比较
else
select 'False' as 配合like比较
if(@a + 'a' = @b + 'a')
select 'True' as 末尾补充字符比较
else
select 'False' as 末尾补充字符比较
六、Sql Server Function函数 is not a recognized built-in function name
/*
日期类型转时间戳
*/
ALTER Function fx_DateToTimestamp(@DateInfo datetime)
Returns int
Begin
return DATEDIFF(second, '1970-01-01 08:00:00', @DateInfo);
End
/*
时间戳转日期类型
*/
ALTER Function fx_TimestampToDate(@TimestampInfo int)
Returns datetime
Begin
return DATEADD(second,@TimestampInfo,'1970-01-01 08:00:00');
End
调用的时候一定要记得加上dbo.函数名字 因为SQL server服务端会当作是内建函数,内建函数列表是没有我们自定义函数的,所以就会报错
七、取时间的年月日
convert (varchar(7), getdate(), 120) -- 取年月 xxxx - xx
convert (varchar(10), getdate(), 120) --取年月日 xxxx - xx - xx
八、json提取
json_value(ColName, ' $.KeyName ')
九、sqlserver更新数据表结构增加新字段时,和它相关联的视图出现错列现象
建议在使用某个视图之前 重新编译一下
即,运行 sp_refreshview '视图名'
十、有趣的 case when
我们都知道SQL Server中NULL是一个很特殊的存在,因为NULL不会等于任何值,且NULL也不会不等于任何值。对于NULL我们只能使用IS或IS NOT关键字来进行比较。
SELECT CASE WHEN NULL=1 THEN 1 ELSE 0 END -- 返回 0
SELECT CASE WHEN NOT NULL=1 THEN 1 ELSE 0 END -- 返回 0
SELECT CASE WHEN NOT NOT NULL=1 THEN 1 ELSE 0 END -- 返回 0
事实上无论我们在NULL=1前面加多少个NOT关键字,判断条件NOT ... NOT NULL=1都会返回False。
因为我们前面说了NULL不会等于任何值,且NULL也不会不等于任何值,所以除了用IS或IS NOT关键字来比较NULL,所有其它比较运算符对NULL进行的比较都是无效的,NULL会让整个表达式都返回False,
所以无论我们在判断条件NULL=1前面加多少个NOT关键字都没有用,因为整个NOT ... NOT NULL=1表达式都会返回False。
虽然上面我们看到NULL会让整个判断表达式都返回False,但是它并不会干扰由OR或AND关键字分隔的其它判断条件,例如:
SELECT CASE WHEN (NOT NOT NULL=1) OR (1=1 AND 2=2) THEN 1 ELSE 0 END -- 返回 1
了解了上面的内容之后,我们再来看一个更好玩的:
case具有两种格式:
- 简单case表达式,它通过将表达式与一组简单的表达式进行比较来确定结果。
- case搜索表达式,它通过计算一组布尔表达式来确定结果。
-- 简单case表达式
SELECT CASE sex
WHEN '男' THEN '1'
WHEN '女' THEN '2'
ELSE '0'
END AS '性别'
FROM test
-- 搜索case表达式
SELECT CASE
WHEN sex = '男' THEN '1'
WHEN sex = '女' THEN '2'
ELSE '0'
END AS '性别'
FROM test
解释:
case 简单表达式的工作方式如下:将第一个表达式与每个 when 子句中的表达式进行比较,以确定它们是否等效。 如果这些表达式等效,将返回 then 子句中的表达式。
-
仅用于等同性检查。
-
按指定的顺序计算每个 when 子句的 input_expression = when_expression。
-
返回首个 input_expression = when_expression 的计算结果为 true 的 result_expression 。
-
如果 input_expression = when_expression 的计算结果均不为 true,则在指定了 else 子句的情况下,SQLServer数据库引擎将返回 else_result_expression;若没有指定 else 子句,则返回 null 值 。
case 搜索表达式:
-
按指定顺序对每个 when 子句的 boolean_expression 进行计算 。
-
返回首个 boolean_expression 的计算结果为 true 的 result_expression 。
-
如果 boolean_expression 的计算结果均不为 true,则在指定了 else 子句的情况下,数据库引擎将返回 else_result_expression;若没有指定 else 子句,则返回 null 值
感觉 just-so-so ?
问题:如果要判断 input_expression 是为 null 值的情况呢?这个时候,建议使用 case 的搜索表达式,如果使用的是简单表达式,那么语句会变成这样
SELECT
CASE SEX
WHEN null THEN '0'
WHEN '男' THEN '1'
WHEN '女' THEN '2'
ELSE '0'
END AS '性别'
FROM test
这样的话,其实是存在问题的,因为正如上面所说的,‘when null’ 恒为 false,剩下的不多说,多看看就懂了
十一、解决数据库死锁的问题


1 SELECT * FROM sysprocesses WHERE blocked <> 0 -- 查询是否发生死锁 2 3 SELECT dbid,name FROM sys.sysdatabases -- 查询发生阻塞或死锁的数据库 4 5 DBCC inputbuffer(133) -- 查询造成阻塞或死锁的Sql语句,参数为spid 6 7 KILL 121 --打破死锁,参数为spid
十二、SQL_SERVER 字符串聚合拼接
文章原地址:https://www.cnblogs.com/stealth7/p/6891211.html
数据范例如下:

要得到的结果目标,获取type相同的所有names拼接在一起的字符串:
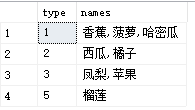
SqlServer并没有一个直接拼接字符串的函数,下面所提到的方法,只是日常的开发中自己个人用到的一些思路,仅供参考!
declare @tempTable table([Type] int,[Name] nvarchar(100))
创建表变量,字段为你需要返回的各列的值
1 insert @tempTable
2 select [type],MAX([name]) name
3 from test
4 group by [type]
插入初始的聚合数据
1 updateTag:
2 update @tempTable
3 set [name] += (','+ a.[name])
4 from test a,@tempTable b
5 where a.[Type] = B.[Type]
6 and CHARINDEX(a.[name],b.[name]) = 0
7 if @@ROWCOUNT > 0
8 begin
9 GOTO updateTag
10 end
11
12
13 select * from @tempTabl
循环插入其他满足条件的聚合数据,这种方案适合包含聚合条件比较复杂的情况,比如需要查询聚合多列拼接字符串结果,其中还涉及到一些列的复杂运算,但是劣势也很明显,如果分组聚合的项比较多时,会比较耗时,因为有一个循环效率不是很高的insert,但是对于几十或者几百次的循环来说还是没太大的问题的。
其实网上搜了一圈还是有不错的方法的,比如STUFF函数,我们可以这么写得到上面的结果:
1 SELECT [TYPE], STUFF(
2 ( SELECT ','+ [Name]
3 FROM test b
4 WHERE b.Type = a.Type
5 FOR XML PATH('')),1 ,1, '') [Names]
6 from Test a
7 group by [TYPE]
十三、a full join b full join c
之前写过一个很麻烦的,不是三个表,而是六七个表进行full join连接!
后来,先union all,然后用union all的结果再,关联这6-7个表,这样比较有扩展性。如果还是用full join的话,很容易写错的
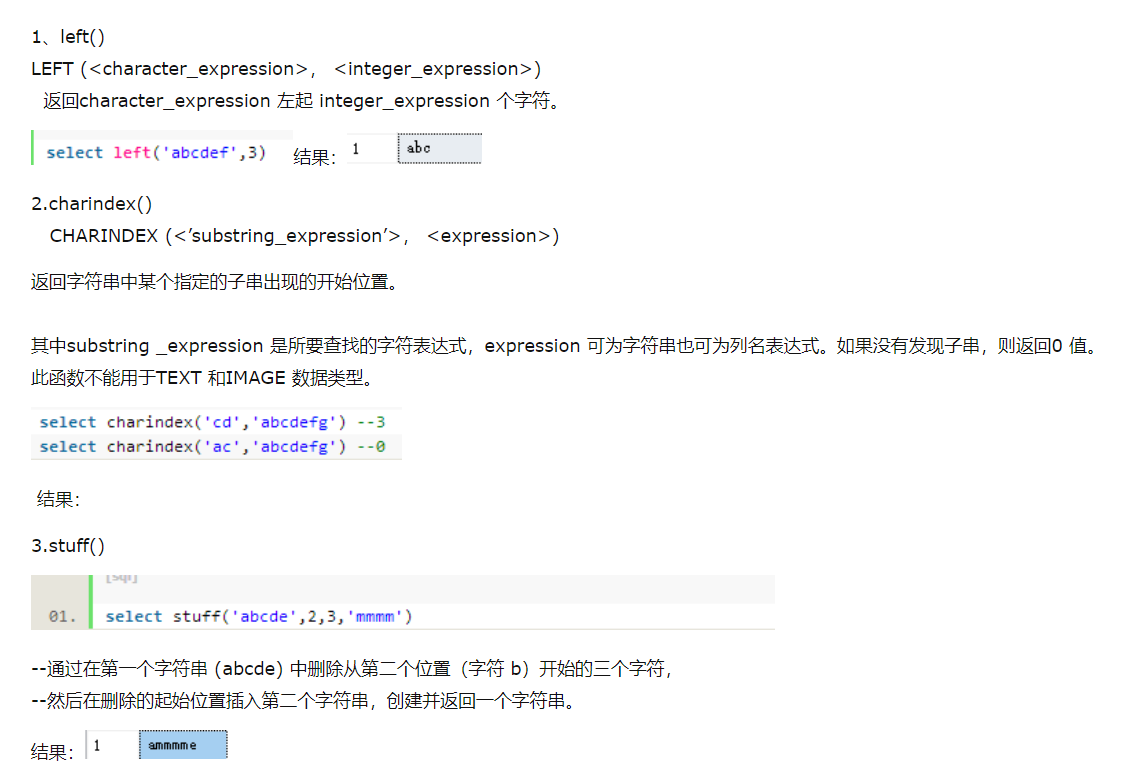
十四、SQLServer函数 left()、charindex()、stuff()的使用
十五、查看所有存储过程或视图里,包含某个关键字的查询语句
首先需要了解,存储过程保存的方式和每个表的保存方式是一样的,都保存在定义的数据库中,使用select * from sysobjects 可是实现查询,他与表的区分是表的xtype=‘U’ 而存储过程的类型是xtype='p'
1 SELECT DISTINCT
2 b.name
3 FROM dbo.syscomments a, dbo.sysobjects b
4 WHERE a.id= b.id
5 AND b.xtype= 'p'
6 AND a.text LIKE '%name%'
7 ORDER BY name
十六、查看包含某个关键字的所有表
首先上语句:
1 SELECT
2 object_name(id) objName,
3 Name AS colName
4 FROM syscolumns
5 WHERE name LIKE '%BU%' -- 在这里添加想要检索的关键字
6 AND id IN (SELECT id FROM sysobjects WHERE xtype = 'u')
7 ORDER BY objname
再来看解释:
1 系统表:sysobjects,sysolumns,object_id()函数,object_name()函数
2
3 1、sysobjects:在数据库内创建的每个对象(约束、默认值、日志、规则、存储过程等)在表中占一行。
4
5 sysobjects 重要字段解释:
6
7 sysobjects (
8
9 Name sysname, --object 名称
10
11 id int, --object id
12
13 xtype char(2), -- object 类型
14
15 type char(2), -- Object 类型(与xtype 似乎一模一样)
16
17 uid smallint, -- object 所有者的ID
18
19 ... --其他的字段不常用到。
20
21 )
22
23 xtype可以是下列对象类型中的一种:
24 C = CHECK 约束 D = 默认值或 DEFAULT 约束 F = FOREIGN KEY 约束 L = 日志 FN = 标量函数
25 IF = 内嵌表函数 P = 存储过程 PK = PRIMARY KEY 约束(类型是 K) RF = 复制筛选存储过程
26 S = 系统表 TF = 表函数 TR = 触发器 U = 用户表 UQ = UNIQUE 约束(类型是 K)
27 V = 视图 X = 扩展存储过程
28
29 type可以是下列值之一:
30 C = CHECK 约束 D = 默认值或 DEFAULT 约束 F = FOREIGN KEY 约束
31 FN = 标量函数 IF = 内嵌表函数 K = PRIMARY KEY 或 UNIQUE 约束
32 L = 日志 P = 存储过程 R = 规则 RF = 复制筛选存储过程
33 S = 系统表 TF = 表函数 TR = 触发器 U = 用户表 V = 视图 X = 扩展存储过程
34
35 二、sysolumns:当前数据库的所有字段都保留在里面
36
37 重要字段解释:
38
39 sysColumns (
40
41 name sysname, --字段名称
42
43 id int, --该字段所属的表的ID
44
45 xtype tinyInt, --该字段类型,关联sysTypes表
46
47 length smallint, --该字段物理存储长度
48
49 ...--其他的字段不常用到
50
51 )
52
53 三、object_id(objectname),object_name(objectid)函数
54
55 数据库中每个对像都有一个唯一的Id值,用Object_name(id)可以根据id值得到对像的名称,object_id(name)可以根据对像名称得到对象的ID
56
57 SQL SERVER 2000以上版本都支持这个函数。
十七、SQL server 常用的时间函数
以下部分摘自 https://www.cnblogs.com/yanghaibo/articles/1693522.html
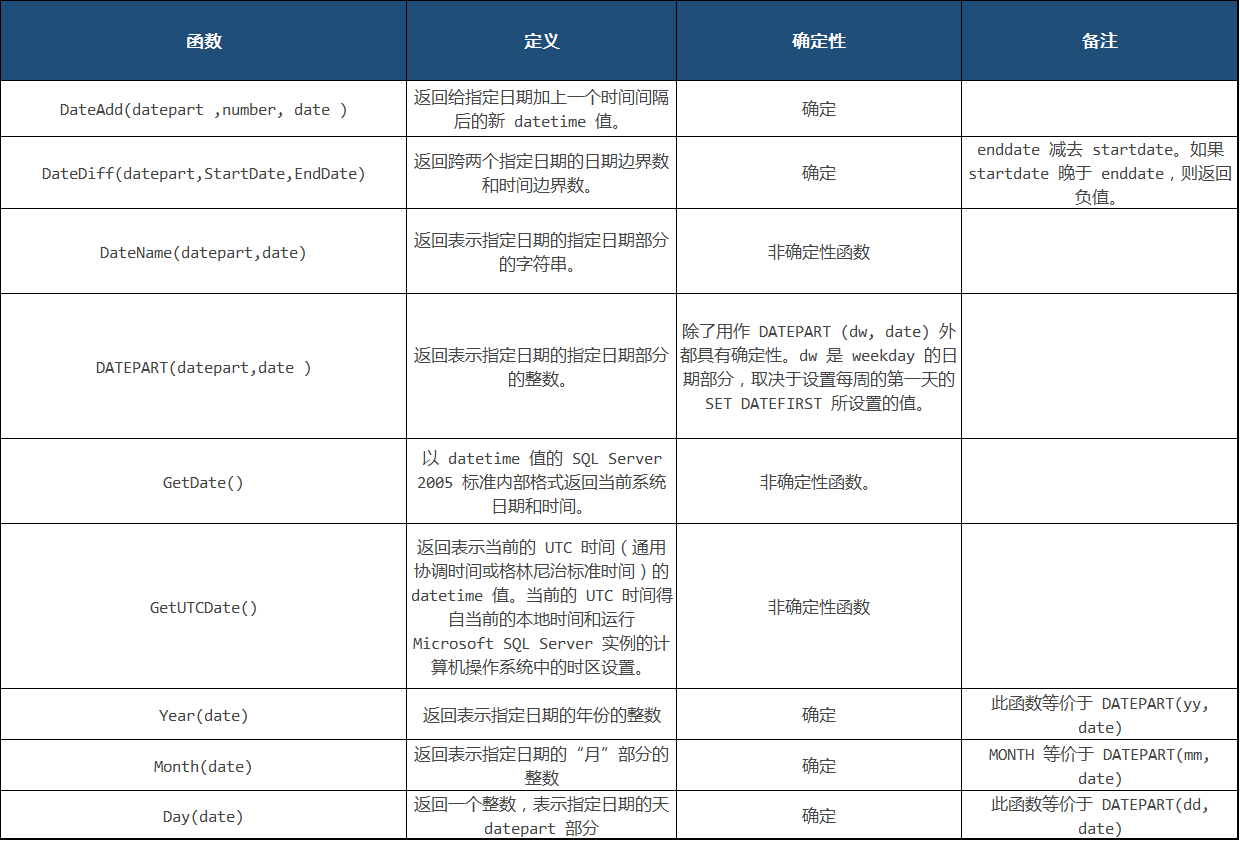
非确定函数,引用该列的视图和表达式无法进行索引

1.一个月第一天的 Select DATEADD(mm, DATEDIFF(mm,0,getdate()), 0)
2.本周的星期一 Select DATEADD(wk, DATEDIFF(wk,0,getdate()), 0)
3.一年的第一天 Select DATEADD(yy, DATEDIFF(yy,0,getdate()), 0)
4.季度的第一天 Select DATEADD(qq, DATEDIFF(qq,0,getdate()), 0)
5.当天的半夜 Select DATEADD(dd, DATEDIFF(dd,0,getdate()), 0)
6.上个月的最后一天 Select dateadd(ms,-3,DATEADD(mm, DATEDIFF(mm,0,getdate()), 0))
7.去年的最后一天 Select dateadd(ms,-3,DATEADD(yy, DATEDIFF(yy,0,getdate()), 0))
8.本月的最后一天 Select dateadd(ms,-3,DATEADD(mm, DATEDIFF(m,0,getdate())+1, 0))
9.本年的最后一天 Select dateadd(ms,-3,DATEADD(yy, DATEDIFF(yy,0,getdate())+1, 0))
10.本月的第一个星期一 select DATEADD(wk, DATEDIFF(wk,0,dateadd(dd,6-datepart(day,getdate()),getdate())), 0)
十八、去掉字符串前后空格
ltrim(rtrim(' test '))
十九、截取字符串
1.LEFT ( character_expression , integer_expression )
函数说明:LEFT ( '源字符串' , '要截取最左边的字符数' )
select LEFT('abcdefg',3);
结果:abc
2.RIGHT ( character_expression , integer_expression )
函数说明:RIGHT ( '源字符串' , '要截取最右边的字符数' ),返回字符串中从右边开始指定个数的 integer_expression 字符
select RIGHT('abcdefg',3);
结果:efg
3.SUBSTRING ( expression , start , length )
函数说明:SUBSTRING ( '源字符串' , '截取起始位置(含该位置上的字符)' , '截取长度' ),返回字符、expression 表达式的一部分
select SUBSTRING('abcdefg',3 ,4); //意思:从第三位开始截取,截取4位
结果:cdef
4.CHARINDEX(expression1, expression2 [,start_location])
函数说明:CHARINDEX 查询字符串所在的位置,expression1 为子字符串,expression2 为父字符串,start_location 表示开始位置。
select CHARINDEX('d', 'abcdef', 0);
结果:4
二十、当聚合函数遇见NULL
现象:Sql Server报出警告:Warning: Null value is eliminated by an aggregate or other SET operation.
原因:Null 会被聚合函数忽略,同时,count()/sum()/min()/max()函数都不会计算null值。
解决:设置 SET ANSI_WARNINGS OFF
建议:保持默认ON打开状态,警告信息不会影响语句执行