-
bs4库的prettify()方法:

-
将某一个标签打印:
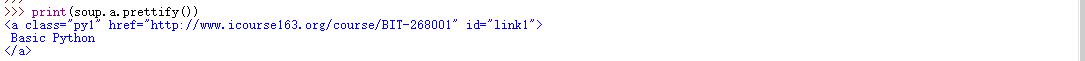
-
对于中文的HTML代码,也可以直接打印:

基于bs4库的HTML内容查找方法
-
<>.find_all(name,attrs,recursive,string,**kwargs):返回一个列表类型,存储查找的结果
-
name:对标签名称的检索字符串。
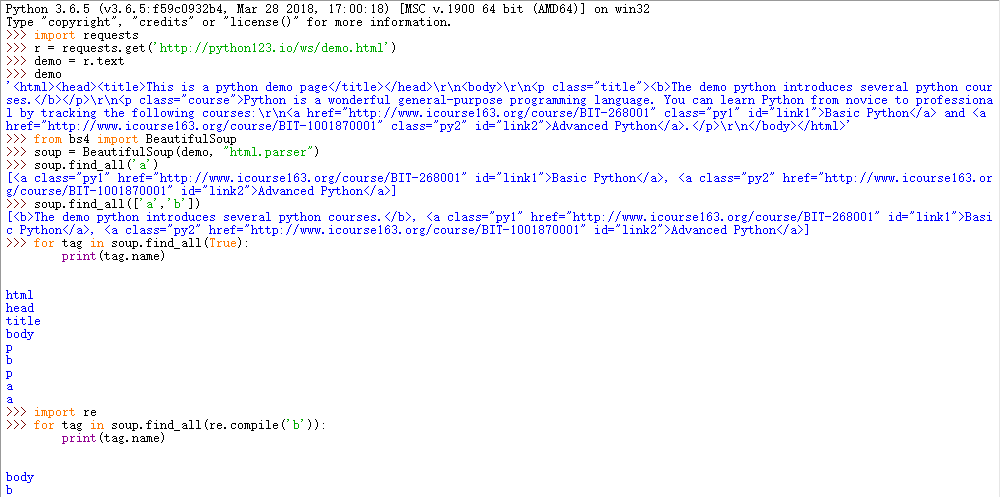
其中的(import re)是导入正则表达式库。
-
attrs:对标签属性值的检索字符串,可标注属性检索。

-
recursive:是否对子孙全部检索,默认为Ture。

-
string:<>...</>中字符串区域的检索字符串。

-
find_all函数的简写形式:
-
<tag>(..)等价于<tag>.find_all(..)
-
soup(..)等价于soup.find_all(..)
-
find_all函数的扩展方法:
-
<>.find():搜索且只返回一个结果,字符串类型,同.find_all()参数
-
<>.find.parents():在先辈节点中搜索,返回列表类型,同.find_all参数
-
<>.find.parent():在先辈节点中返回一个结果,字符串类型,同.find_all()参数
-
<>.find_next_siblings():在后续平行节点中搜索,返回列表类型,同.find_all()参数
-
<>.find.next_sibling ():在后续平行节点中返回一个结果,字符串类型,同.find_all()参数
-
<>.find_previous_siblings():在前序平行节点中搜索,返回列表类型,同.find_all()参数
-
<>.find_previous_sibling():在前序平行节点中返回一个结果,字符串类型,同.find_all()参数