一、提取所需要断言的内容:
响应数据如下:加入需要提取id为90的值
{
"id" : 90,
"name" : "python",
"url" : "http://www.v2ex.com/go/python",
"title" : "Python",
"title_alternative" : "Python",
"topics" : 7428,
"stars" : 4776,
"header" : "这里讨论各种 Python 语言编程话题,也包括 Django,Tornado 等框架的讨论。这里是一个能够帮助你解决实际问题的地方。",
"footer" : null,
"created" : 1278683336,
"avatar_mini" : "//v2ex.assets.uxengine.net/navatar/8613/985e/90_mini.png?m=1501663676",
"avatar_normal" : "//v2ex.assets.uxengine.net/navatar/8613/985e/90_normal.png?m=1501663676",
"avatar_large" : "//v2ex.assets.uxengine.net/navatar/8613/985e/90_large.png?m=1501663676"
}
1、sample添加-后置处理器-添加JSON Extracror(这里面需要稍微学习下json path espressions的语法了)--得到id的值90
自己看这个网址学习吧:http://goessner.net/articles/JsonPath/

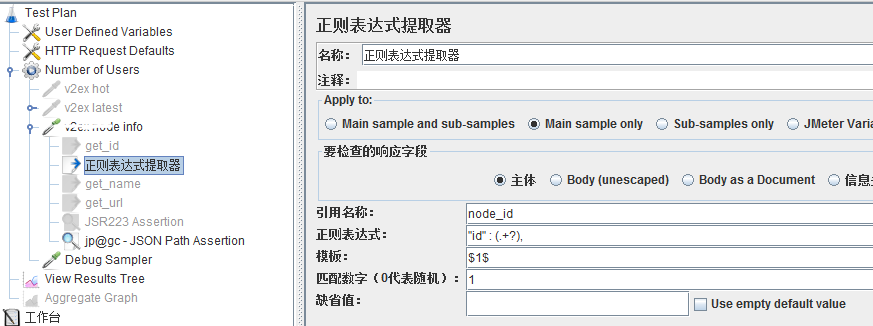
2、也可以使用正则表达式提取
"id":(.+?),
二、断言提取出来的值
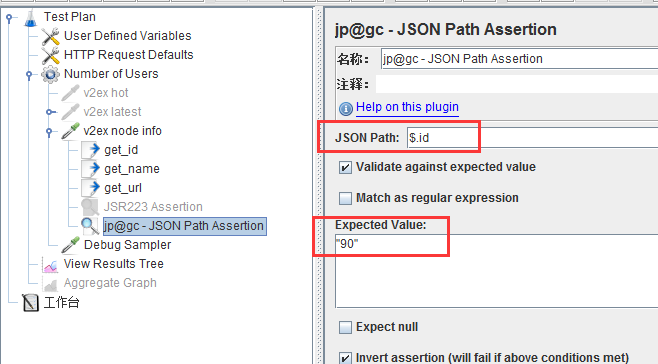
sample-断言-添加json path assert(前提是要安装这个包啊啊啊)
三、json path espressions的语法学习

$:跟对象元素
@:当前对象元素
?():应用过滤器(脚本)表达式
还是自己练习吧。。。。
1 { "store": {
2 "book": [
3 { "category": "reference",
4 "author": "Nigel Rees",
5 "title": "Sayings of the Century",
6 "price": 8.95
7 },
8 { "category": "fiction",
9 "author": "Evelyn Waugh",
10 "title": "Sword of Honour",
11 "price": 12.99
12 },
13 { "category": "fiction",
14 "author": "Herman Melville",
15 "title": "Moby Dick",
16 "isbn": "0-553-21311-3",
17 "price": 8.99
18 },
19 { "category": "fiction",
20 "author": "J. R. R. Tolkien",
21 "title": "The Lord of the Rings",
22 "isbn": "0-395-19395-8",
23 "price": 22.99
24 }
25 ],
26 "bicycle": {
27 "color": "red",
28 "price": 19.95
29 }
30 }
31 }
$.store.book[*].author:商店所有书籍的作者(四个作者)
$..author :所有作者
$.store.* :商店所有的东西,包括book和bicycle
$.store..price :所有东西的价格
$..book[2] :第三本书
$..book[0,1] /$..book[:2] :前两本书
$..book[?(@.isbn)] :用isbn编号过滤所有书籍
$..book[?(@.price<10)] :过滤所有比10更便宜的书
$..* :XML文档中的所有元素