业务描述:
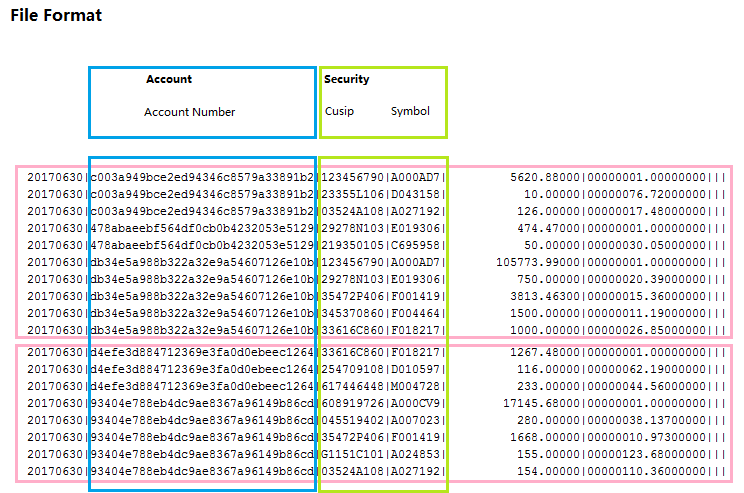
项目中需要对用户的holding文件进行处理,转成内部格式,并对关键业务项(如security)生成内部ID,为简化起见,此处将ID设置为UUID,文件样例如下,以“|”分割
20170630|c003a949bce2ed94346c8579a33891b2|123456790|A000AD7| 5620.88000|00000001.00000000||| 20170630|c003a949bce2ed94346c8579a33891b2|23355L106|D043158| 10.00000|00000076.72000000||| 20170630|c003a949bce2ed94346c8579a33891b2|03524A108|A027192| 126.00000|00000017.48000000||| 20170630|478abaeebf564df0cb0b4232053e5129|29278N103|E019306| 474.47000|00000001.00000000||| 20170630|478abaeebf564df0cb0b4232053e5129|219350105|C695958| 50.00000|00000030.05000000||| 20170630|db34e5a988b322a32e9a54607126e10b|123456790|A000AD7| 105773.99000|00000001.00000000||| 20170630|db34e5a988b322a32e9a54607126e10b|29278N103|E019306| 750.00000|00000020.39000000||| 20170630|db34e5a988b322a32e9a54607126e10b|35472P406|F001419| 3813.46300|00000015.36000000||| 20170630|db34e5a988b322a32e9a54607126e10b|345370860|F004464| 1500.00000|00000011.19000000||| 20170630|db34e5a988b322a32e9a54607126e10b|33616C860|F018217| 1000.00000|00000026.85000000||| 20170630|d4efe3d884712369e3fa0d0ebeec1264|33616C860|F018217| 1267.48000|00000001.00000000||| 20170630|d4efe3d884712369e3fa0d0ebeec1264|254709108|D010597| 116.00000|00000062.19000000||| 20170630|d4efe3d884712369e3fa0d0ebeec1264|617446448|M004728| 233.00000|00000044.56000000||| 20170630|93404e788eb4dc9ae8367a96149b86cd|608919726|A000CV9| 17145.68000|00000001.00000000||| 20170630|93404e788eb4dc9ae8367a96149b86cd|045519402|A007023| 280.00000|00000038.13700000||| 20170630|93404e788eb4dc9ae8367a96149b86cd|35472P406|F001419| 1668.00000|00000010.97300000||| 20170630|93404e788eb4dc9ae8367a96149b86cd|G1151C101|A024853| 155.00000|00000123.68000000||| 20170630|93404e788eb4dc9ae8367a96149b86cd|03524A108|A027192| 154.00000|00000110.36000000|||
对此文件,我们暂且只关注第3,第4列,分别表示security的cusip及symbol
1:Redis准备
因在spark中需要使用redis,故先在本机安装好redis server,可参看文章:Redis安装
启动redis服务:
redis-server redis.windows.conf
如果在window 10系统中,可以参考另外一篇文章搭建环境:window10 系统上设置redis开发环境
另外开启一个redis client命令行窗口:
redis-cli -h 127.0.0.1 -p 6379
2:启动spark shell:
对于Redis的客户端,官方建议的是Jedis,可以从 https://github.com/xetorthio/jedis 下载源代码并打包,或者使用maven dependency下载
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
<type>jar</type>
<scope>compile</scope>
</dependency>
找到maven仓库的Jedis目录(.m2 epository edisclientsjedis2.9.0),将jedis-2.9.0.jar拷贝到spark的jars目录中,
spark-shell --jars ..jarsjedis-2.9.0.jar
3:程序代码
在spark shell中执行以下代码:
import java.util.UUID import redis.clients.jedis.Jedis val txtFile = sc.textFile("D:\temp\holdings.txt",2) val rdd1 = txtFile.map(line => line.split("\|")) val rdd2 = rdd1.map(x => ((x(2)+"_"+x(3)).hashCode, x(2),x(3))) val rdd3 = rdd2.distinct
上述的每一个rdd运算,都将产生一个新的rdd,此处为了简化,方便理解,假设文件被读入到2个分区,通常每个分区大小为128M,

在rdd3中,保存的是security的元组列表,分别在2个分区中,因为rdd2.distinct 时已经对数据进行shuffle,所以不存在相互重叠,现在我们要做的是对每个security tuple,在redis中查找是否已经存在记录,如果不存在,就在redis中创建一天k-v记录,并生成一个UUID
val jd = new Jedis("127.0.0.1",6379) rdd3.foreach(x => if(jd.get(x._2) ==null) jd.set(x._2,UUID.randomUUID().toString()))
执行上述代码,期望在redis中生成k-v,以tuple的第2个元素为key,生成的UUID为value,但执行时报错Task not serializable:
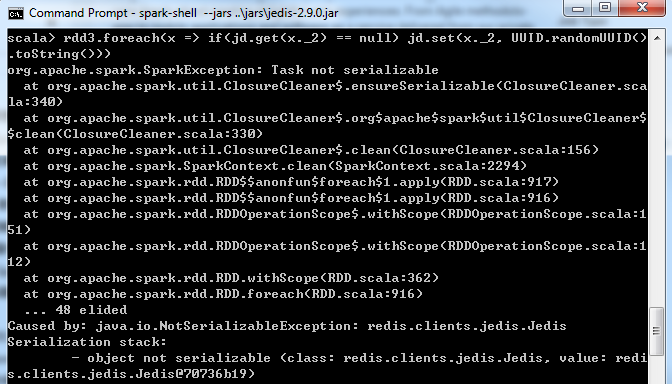
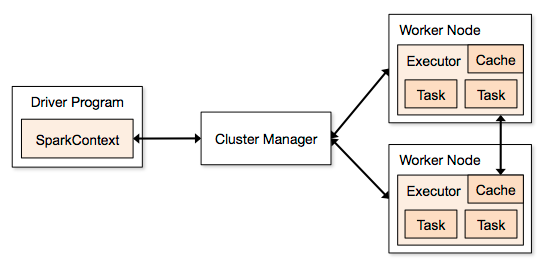
在spark shell中,启动的是一个默认的SparkContext sc,上面代码的jd是在Driver中创建的,但由于rdd的操作是分布式运行在Executor中,而不是在Driver中,在做foreach时,需要将命令文本做序列化,并分发到相应的Worker Node机器,但redis 的TCP链接已经绑定在Driver进程,是无法分发到各个节点去执行的,所以提示序列化错误,请见Spark架构图:
修改代码,在reduce partition中进行数据库链接,使用foreachPartition函数取代foreach
rdd3.foreachPartition(it => { val jd = new Jedis("127.0.0.1",6379) it.foreach(x => if(jd.get(x._2) ==null) jd.set(x._2,UUID.randomUUID().toString())) })
执行成功,

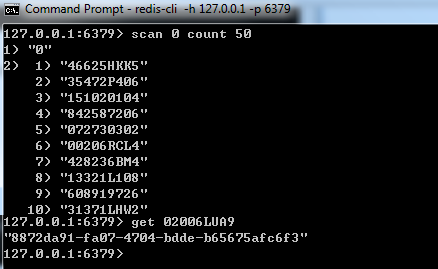
在redis client窗口中可以scan Redis数据库,并使用get命令获取相应的k-v
4:在IDEA中本地调试sprak程序
在IDEA中,修改如下图红框所示的参数,然后启动调试就可以了

5:程序打包执行
在spark-shell通过交互式命令验证后,就可以将程序打包成可执行jar包,先创建一个maven工程,修改pom文件如下,此处使用了sprint boot插件sprint-boot-maven-plugin并指定mainClass:
package mytest import org.apache.spark._ import java.util.UUID import redis.clients.jedis.Jedis object Import { def main(args: Array[String]): Unit = { val file = args(0) val sparkConf = new SparkConf().setAppName("MyImport") if(args.length ==2) { sparkConf.setMaster(args(1)) } val sc = new SparkContext(sparkConf) val txtFile = sc.textFile(file,4) val rdd1 = txtFile.map(line => line.split("\|")) val rdd2 = rdd1.map(x => ((x(2)+"_"+x(3)).hashCode, x(2),x(3))) val rdd3 = rdd2.distinct rdd3.foreachPartition(it => { val jd = new Jedis("127.0.0.1",6379) it.foreach(x => if(jd.get(x._2) ==null) jd.set(x._2,UUID.randomUUID().toString())) }) } }
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>mytest</groupId> <artifactId>myproject</artifactId> <version>1.0-SNAPSHOT</version> <inceptionYear>2008</inceptionYear> <properties> <scala.version>2.11.8</scala.version> <spark.version>2.2.1</spark.version> </properties> <repositories> <repository> <id>scala-tools.org</id> <name>Scala-Tools Maven2 Repository</name> <url>http://scala-tools.org/repo-releases</url> </repository> </repositories> <pluginRepositories> <pluginRepository> <id>scala-tools.org</id> <name>Scala-Tools Maven2 Repository</name> <url>http://scala-tools.org/repo-releases</url> </pluginRepository> </pluginRepositories> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.4</version> <scope>test</scope> </dependency> <dependency> <groupId>org.specs</groupId> <artifactId>specs</artifactId> <version>1.2.5</version> <scope>test</scope> </dependency> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.0</version> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> <configuration> <scalaVersion>${scala.version}</scalaVersion> <args> <arg>-target:jvm-1.5</arg> </args> </configuration> </plugin> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <executions> <execution> <goals> <goal>repackage</goal> </goals> <configuration> <!--<classifier>spring-boot</classifier>--> <mainClass>mytest.Import</mainClass> </configuration> </execution> </executions> </plugin> </plugins> </build> <reporting> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <configuration> <scalaVersion>${scala.version}</scalaVersion> </configuration> </plugin> </plugins> </reporting> </project>
在上面的pom文件中,使用的是spring-boot-maven-plugin插件,将所有的依赖包打包到一个fat-jar包中,执行mvn package后,生成可执行jar包:myproject-1.0-SNAPSHOT.jar,包的大小将近100M
开启一个新的命令窗口,运行下面命令,此命令将在本地以单机多线程模式的方式运行
java -jar myproject-1.0-SNAPSHOT.jar d: empholdings.txt local[4]
或
spark-submit --master local[4] d: empmyproject-1.0.SNAPSHOT.jar d: empholdings.txt
可以看到spark正常运行,并在redis中可以查到新创建的记录。