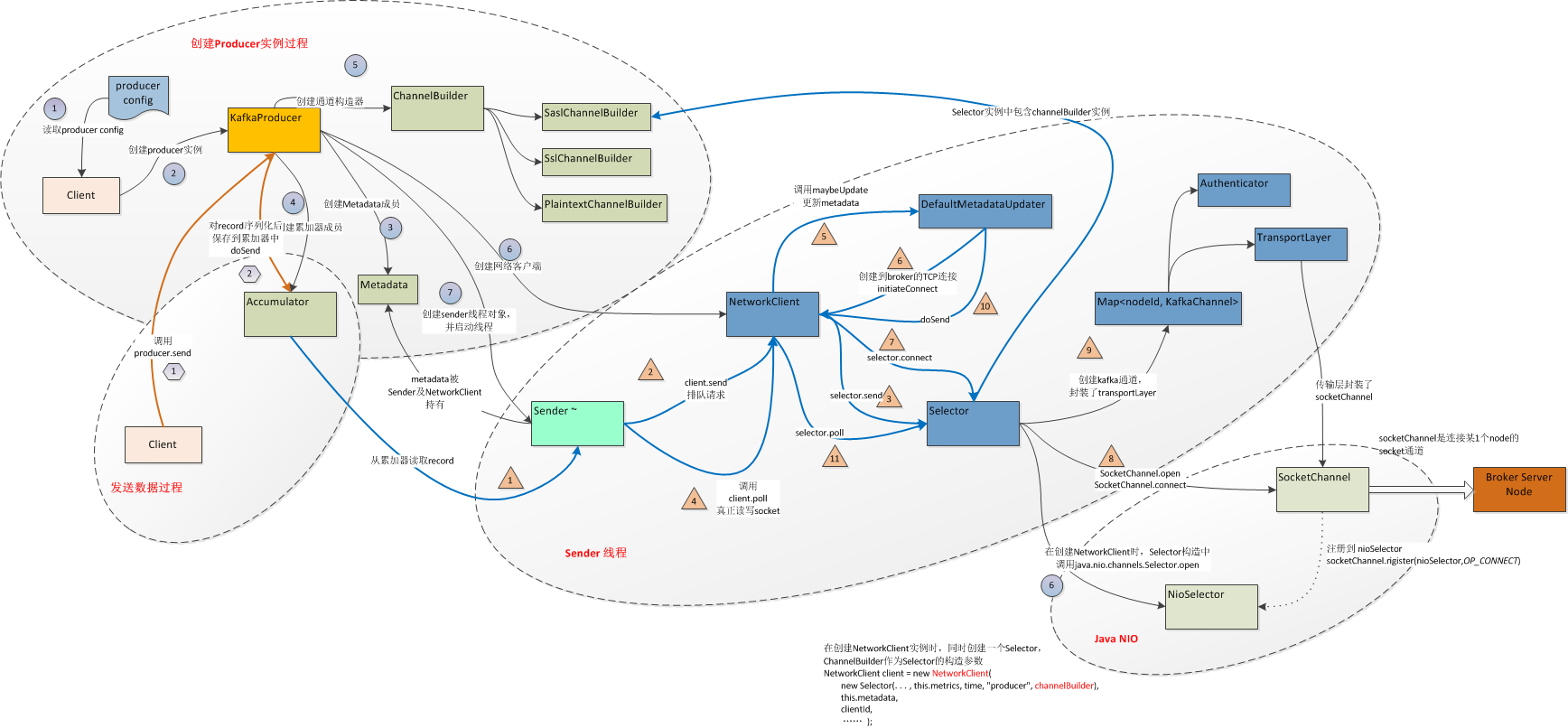
在使用kafka producer API时,主要有2个过程:创建producer实例过程,调用producer实例发送数据(同步/异步)过程,其实在创建producer实例的同时,也创建了一个sender线程,sender线程不断轮询更新metadata及从accumulator中读取数据并真正发送到某个broker上面,下面的活动关系图大致描述了producer的API的内部调用过程
创建producer实例:
1:client读取producer config,sample如下:
{
security.protocol=SASL_PLAINTEXT,
bootstrap.servers=server1.com:8881,server2:8882,
value.serializer=xxx.serialization.avro.AvroWithSchemaSpecificSer,
key.serializer=org.apache.kafka.common.serialization.LongSerializer,
client.id=15164@hostname,
acks=all
}
2:调用以下方法创建producer实例
Producer<K,V> producer = new KafkaProducer<>(props, keySerClass, valueSerClass);
3:Kafka Producer实例是producer的关键入口,封装了后续所有组件的调用,在创建producer实例的过程中,将依次创建以下组件
创建metadata实例,传递参数 refreshBackoffMs(最小过期时间retry.backoff.ms,默认值100毫秒),metadataExpireMs(元数据最大保留时间metadata.max.age.ms,默认值300000毫秒)
metadata保存了topic,partition,borker的相关信息
this.metadata = new Metadata(retryBackoffMs, config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG));
4:创建累加器RecordAccumulator
累计器是一个保存消息的有边界的内存队列,当客户端发送数据时,数据将append到队列尾部,如果内存耗尽,append调用将被阻塞,在实例内部,batches成员保存将被sender的数据
private final ConcurrentMap<TopicPartition, Deque<RecordBatch>> batches;
调用方法
this.accumulator = new RecordAccumulator(config.getInt(ProducerConfig.BATCH_SIZE_CONFIG), //batch.size,默认值16384(16K),record成批发送的字节数 this.totalMemorySize, //buffer.memory,默认值33554432(32M),缓冲区内存字节数 this.compressionType, //compression.type,默认值none,表示producer的数据压缩类型,有效值为none,gzip,snappy,lz4 config.getLong(ProducerConfig.LINGER_MS_CONFIG), retryBackoffMs, //retry.backoff.ms,默认值100毫秒,metadata最小过期时间 metrics, time);
5:创建通道构建器实例,ChannelBuilder是一个接口,因安全认证方式不同,分别有具体的实现类SaslChannelBuilder,SslChannelBuilder及PlaintextChannelBuilder,通道是java nio中的实际与IO通信的部分,在kafka中,类KafkaChannel封装了SocketChannel。在创建构建器实例时,将进行登录认证
ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(config.values());
6:创建网络客户端实例,NetworkClient封装了底层网络的访问,及metadata数据的更新。
NetworkClient client = new NetworkClient(
new Selector(config.getLong(ProducerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG), this.metrics, time, "producer", channelBuilder),
this.metadata,
clientId,
config.getInt(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION),
config.getLong(ProducerConfig.RECONNECT_BACKOFF_MS_CONFIG),
config.getInt(ProducerConfig.SEND_BUFFER_CONFIG),
config.getInt(ProducerConfig.RECEIVE_BUFFER_CONFIG),
this.requestTimeoutMs, time);
在NetworkClient构造函数中,传进了Selector的实例,这是一个封装了java nio selector的选择器,在Selector构造函数中开启了java nio selector,并且也将前面创建的ChannelBuilder传给NetworkClient内部成员
this.nioSelector = java.nio.channels.Selector.open();
7:创建线程类sender并启动线程,将前面创建的NetworkClient实例,metadata实例及累加器accumulator全部导入到sender类中,sender线程类是一个关键类,所有的动作都是在这个线程中处理的,当sender线程启动后,不断的轮询进行元数据的更新和消息的发送
this.sender = new Sender(client, this.metadata, this.accumulator, config.getInt(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION) == 1, config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG), (short) parseAcks(config.getString(ProducerConfig.ACKS_CONFIG)), config.getInt(ProducerConfig.RETRIES_CONFIG), this.metrics, new SystemTime(), clientId, this.requestTimeoutMs); String ioThreadName = "kafka-producer-network-thread" + (clientId.length() > 0 ? " | " + clientId : ""); this.ioThread = new KafkaThread(ioThreadName, this.sender, true); this.ioThread.start();
发送数据过程:
1:客户端发送数据
客户端构造好ProducerRecord,调用send方法发送消息,send方法是一个异步方法,返回一个future对象,调用完后就立即返回,send方法只是把数据写入到内存队列RecordAccumulator后就返回了,如果想同步发送消息并确认消息是否发送成功,可以再调用get方法,这将阻塞当前发送线程
ProducerRecord<K, V> producerRecord = new ProducerRecord<>(“topic”,data); producer.send(producerRecord, new ProducerCallBack(requestId));
在调用send方法时,可以传入回调对象,回调函数用于处理send后对ack的处理
2:record 保存到累加器中
在send方法内部,如果有配置拦截器,则先调用拦截器对数据做处理,处理完后的数据,再调用doSend方法,
ProducerRecord<K, V> interceptedRecord = this.interceptors == null ? record : this.interceptors.onSend(record); return doSend(interceptedRecord, callback); //异步发送一条记录到topic
在doSend方法把记录保存到累加器之前,需要做几个事情,首先需要调用waitOnMetadata确认给定topic的并包含partition的metadata是否可用,在waitOnMetadata中如果没有partition,则在循环中请求更新metadata,并唤醒sender线程 (sender.wakeup()),更新metadata,如果超出block时间则timeout异常退出
long waitedOnMetadataMs = waitOnMetadata(record.topic(), this.maxBlockTimeMs); //KafkaProducer.send()的最长阻塞时间,max.block.ms,默认为60000毫秒
while (metadata.fetch().partitionsForTopic(topic) == null) { log.trace("Requesting metadata update for topic {}.", topic); int version = metadata.requestUpdate(); sender.wakeup(); //唤醒sender线程去更新metadata metadata.awaitUpdate(version, remainingWaitMs); //等待metadata更新,如果超出max.block.ms时间,则抛出timeout异常 ...... }
如果在到达 max.block.ms前成功更新metadata,则对record做key/value序列化,添加到累加器中,然后再次唤醒sender线程
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, interceptCallback, remainingWaitMs);
在这个阶段中,数据只是发送到一个中间的缓冲区中,并没有真正的传到broker上
sender线程
1:sender线程启动后,循环执行Sender.run(now)函数,此函数的最主要功能就是从accumulator中drain出数据,转成生产者请求数据List<ClientRequest>
2:如果有生产者请求数据列表,则调用NetworkClient.send函数,此函数内部调用了doSend(ClientRequest,long)函数,将请求加入飞行队列中inFlightRequests,
{NetworkClient}
private void doSend(ClientRequest request, long now) { request.setSendTimeMs(now); this.inFlightRequests.add(request); //将请求加入飞行队列 selector.send(request.request()); //数据被保存到KafkaChannel的内存中 }
3:接着调用Selector.send(Send)方法,从Send数据中取到目标KafkaChannel,再放到KafkaChannel通道的待发送内存中,此时数据还没有真正的被传递broker
{Selector}
public void send(Send send) { KafkaChannel channel = channelOrFail(send.destination()); //取到目标channel try { channel.setSend(send); //把数据保存到目标channel内存中 } catch (CancelledKeyException e) { this.failedSends.add(send.destination()); close(channel); } }
4:当所有从accumulator中取出来的数据被放到对应的channel后,调用NetworkClient.poll,这才是对socket实际读写的地方
5-8:首先需要对元数据的更新,在maybeUpdate中,如果元数据更新时间(metadataTimeout)已经到0了,说明需要更新元数据,找到最近最少用的节点,如果没建好连接,则先创建socket的连接,到第7步,调用Selector.connect,到第8步调用SocketChannel.open及SocketChannel.connect建立socket连接
{NetworkClient} public long maybeUpdate(long now) { // should we update our metadata? long timeToNextMetadataUpdate = metadata.timeToNextUpdate(now); long timeToNextReconnectAttempt = Math.max(this.lastNoNodeAvailableMs + metadata.refreshBackoff() - now, 0); long waitForMetadataFetch = this.metadataFetchInProgress ? Integer.MAX_VALUE : 0; // if there is no node available to connect, back off refreshing metadata long metadataTimeout = Math.max(Math.max(timeToNextMetadataUpdate, timeToNextReconnectAttempt), waitForMetadataFetch); if (metadataTimeout == 0) { // Beware that the behavior of this method and the computation of timeouts for poll() are // highly dependent on the behavior of leastLoadedNode. Node node = leastLoadedNode(now); maybeUpdate(now, node); } return metadataTimeout; } private void maybeUpdate(long now, Node node) { if (node == null) { log.debug("Give up sending metadata request since no node is available"); // mark the timestamp for no node available to connect this.lastNoNodeAvailableMs = now; return; } String nodeConnectionId = node.idString(); if (canSendRequest(nodeConnectionId)) { //如果连接以及建好,可以发送数据 this.metadataFetchInProgress = true; MetadataRequest metadataRequest; if (metadata.needMetadataForAllTopics()) metadataRequest = MetadataRequest.allTopics(); else metadataRequest = new MetadataRequest(new ArrayList<>(metadata.topics())); ClientRequest clientRequest = request(now, nodeConnectionId, metadataRequest); log.debug("Sending metadata request {} to node {}", metadataRequest, node.id()); doSend(clientRequest, now); //发送数据,将数据保存到channel的内存中 } else if (connectionStates.canConnect(nodeConnectionId, now)) { // we don't have a connection to this node right now, make one log.debug("Initialize connection to node {} for sending metadata request", node.id()); initiateConnect(node, now); //创建socket连接 // If initiateConnect failed immediately, this node will be put into blackout and we // should allow immediately retrying in case there is another candidate node. If it // is still connecting, the worst case is that we end up setting a longer timeout // on the next round and then wait for the response. } else { // connected, but can't send more OR connecting // In either case, we just need to wait for a network event to let us know the selected // connection might be usable again. this.lastNoNodeAvailableMs = now; } }
9:socket连接建立好后,注册到nioSelector中,并使用前面创建的channelBuilder创建KafkaChannel通道,KafkaChannel中创建和封装了传输层TransportLayer,传输层封装了socketChannel,通道保存在Map中,而且KafkaChannel中也创建了authenticator认证器
{Selector} SelectionKey key = socketChannel.register(nioSelector, SelectionKey.OP_CONNECT); //注册到Selector中 KafkaChannel channel = channelBuilder.buildChannel(id, key, maxReceiveSize); //创建KafkaChannel key.attach(channel); this.channels.put(id, channel);
10:如果到节点的状态是连接的,并且channel状态已经ready(传输层是ready的,authenticator认证器是complete状态),那么在上面metadataUpdate中,就可以发送元数据更新的请求,调用NetworkClient.doSend,数据被放到飞行请求队列(inFlightRequests)及相应的KafkaChannel内存中,如果inFlightRequests中的请求在请求超时后(默认为"request.timeout.ms" -> "30000",30秒),将断开请求所对应的socket连接,并设置重刷metadata
11:调用Selector.poll进行数据的IO操作,如果获取到selector key,则在这个可以上取到对应的KafkaChannel,调用channel.write发送数据到broker上