知识点:
多线程的实现
图片的下载及写入
字符串高级查找
了解动态加载和json
request 的用法
获取数据的api
'https://www.duitang.com/napi/blog/list/by_search/?kw=%E6%A0%A1%E8%8A%B1&start=0&limt=1000'
图片路径
"path": "https://b-ssl.duitang.com/uploads/item/201509/18/20150918195615_JfdKm.jpeg"
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author: benjaminYang import requests,threading import urllib.parse #设置最大线程 开启30个线程就锁住 thread_lock=threading.BoundedSemaphore(value=50) 'https://www.duitang.com/napi/blog/list/by_search/?kw=%E6%A0%A1%E8%8A%B1&start=0&limt=1000' #通过url 获取数据 def get_page(url): #requests.get 自带了json.loads page=requests.get(url) page=page.content # 将bytes转成 字符串 page=page.decode('utf-8') return page def pages_from_duitang(label): pages=[] url='https://www.duitang.com/napi/blog/list/by_search/?kw={}&start={}&limt=1000' #将中文转成url编码 label=urllib.parse.quote(label) #0-3600 步长100 for index in range(0,3600,50): #将这两个变量替换占位符{} u=url.format(label,index) page=get_page(u) pages.append(page) return pages # print(get_page('https://www.duitang.com/napi/blog/list/by_search/?kw=%E6%A0%A1%E8%8A%B1&start=0&limt=1000')) # 单个页面的对象,startpart 所要匹配字符1,匹配的字符2 def findall_in_page(page,startpart,endpart): all_strings=[] end=0 # -1代表找不到 意思就是匹配到就执行循环 while page.find(startpart,end) !=-1: #匹配第一个字符,从下标0开始匹配到的位置下标,并将字符长短传给start变量 start=page.find(startpart,end)+len(startpart) # 将从第一个需要匹配的字符串后面的字符开始,匹配第二个需要匹配的字符出现的位置,并将这个下标值赋给end变量 end=page.find(endpart,start) #切片 取两个所要匹配字符 之间的部分也就是图片url string=page[start:end] #存入列表 all_strings.append(string) return all_strings # "path": "https://b-ssl.duitang.com/uploads/item/201708/20/20170820215827_fa483.jpeg" def pic_urls_from_pages(pages): pic_urls=[] for page in pages: urls=findall_in_page(page,'path":"','"') pic_urls.extend(urls) # 合并列表 return pic_urls def download_pics(url,n): r=requests.get(url) path='pics/'+ str(n) + '.jpg' with open(path,'wb') as f: f.write(r.content) #下载完了,解锁 thread_lock.release() def main(label): pages=pages_from_duitang(label) pic_urls=pic_urls_from_pages(pages) n=0 for url in pic_urls: n +=1 print('正在下载第{}张图片'.format(n)) #上锁 thread_lock.acquire() #下载 这个方法丢进线程池 t=threading.Thread(target=download_pics,args=(url,n)) t.start() main('校花')

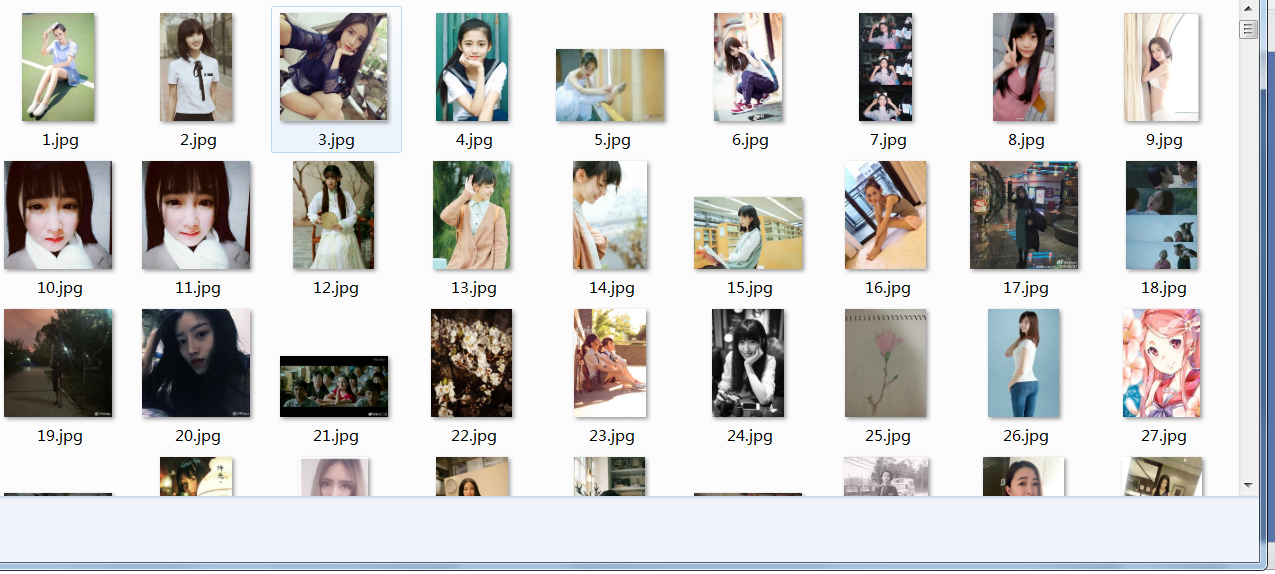
此学习资源来自--潭州Python学院