这篇文章主要是介绍一些基本的click model,这些不同的click model对用户与搜索结果页的交互行为进行不同的假设。
为了定义一个model,我们需要描述出observed variables,hidden variables,以及它们之间的关联,以及它们对model parameters的依赖关系。当我们获取了model parameters之后,我们便可以进行CTR 预估,或者计算数据的最大似然估计。
1. RANDOM CLICK MODEL (RCM)
这是最简单的一个model,只有一个参数:
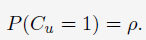
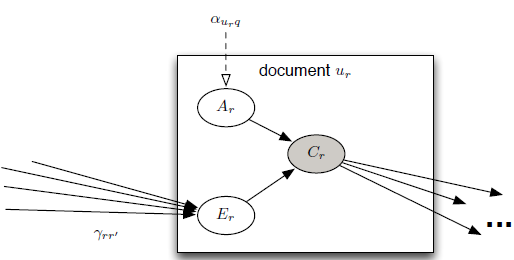
这意味着每个document被点击的概率是一样,即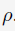 。参数的预估比较简单,相当于计算出全局的CTR。当我们获得了的值之后,我们便可以使用简单的Bernoulli分布来对用户的点击行为进行预估。
。参数的预估比较简单,相当于计算出全局的CTR。当我们获得了的值之后,我们便可以使用简单的Bernoulli分布来对用户的点击行为进行预估。
这个model非常简单,可以作为baseline来看。另外,这个model由于只有一个参数,所以基本不会overfitting。
2. CLICK-THROUGH RATE MODELS (CTR)
我们可以在random click model的基础上进一步,不仅仅只有一个简单的model parameter。下面介绍的model parameter主要与document的排序,或者query-document pair相关。
2.1 RANK-BASED CTR MODEL (RCTR)
对点击日志的研究中经常会用到的一个数据是不同位置下的CTR。根据Joachims等人在2005年发表的paper中可以看出,第1位document的CTR约为0.45,第10位document的CTR则低于0.05。根据这个观察到的现象,我们可以构建一个document点击概率与其位置有关的model:
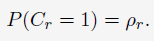
使用最大似然估计(MLE)来预估model parameters时,可以看成直接计算training set在不同位置上的CTR。RCTR也是一个简单的model,不会遇到overfitting的风险,经常作为baseline来看。
2.2 DOCUMENT-BASED CTR MODEL (DCTR)
另一种思路是对query-document pair的点击率进行建模:
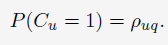
DCTR对每一个query-document pair都构建一个parameter,所以当我们使用过去的观测数据训练兵对新的数据进行预测时,DCTR会比RCM,RCTR更容易overfitting,尤其是当query或者document在以往的数据中没有出现过的时候更是如此。
3. POSITION-BASED MODEL (PBM)
许多click model都会提到所谓的examination hypothesis:

这意味着一个用户点击了某个document,当且仅当他examine了这个document,且这个document是attractive的。参数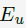 与
与 可以看做是独立的。这个model对应的Bayesian network如下图所示:
可以看做是独立的。这个model对应的Bayesian network如下图所示:
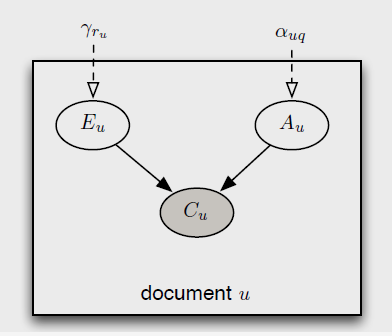
 这个参数是用来表示在相应的query下,这个document的attractiveness。需要强调的一点是,这里的attractiveness是document显示在搜索结果页上的摘要的特征,而不代表document的整篇内容。虽然这两者是相关的,但还不能等同看待。
这个参数是用来表示在相应的query下,这个document的attractiveness。需要强调的一点是,这里的attractiveness是document显示在搜索结果页上的摘要的特征,而不代表document的整篇内容。虽然这两者是相关的,但还不能等同看待。
Joachims等人在2005年发表的paper中显示用户examine一个document的概率主要依赖于该document在搜索结果页中的位置,并且是位置越低概率越低。为了将这个特性考虑进model,我们为每个位置引入examination parameters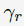 。这样的position-based model (PBM)由Craswell等人在2008年提出,可以表示成如下公式:
。这样的position-based model (PBM)由Craswell等人在2008年提出,可以表示成如下公式:
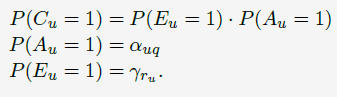
4. CASCADE MODEL (CM)
cascade model由Craswell等人在2008年提出,它假设用户在搜索结果页上从上至下浏览document,直至他找到一个相关的document为止。基于这个假设,第1位的document可以认为总是被examine的,而从第2位开始的documents当且仅当其上一个document被examine过且没有被点击时,它才会被examine。cascade model的公式表达如下:
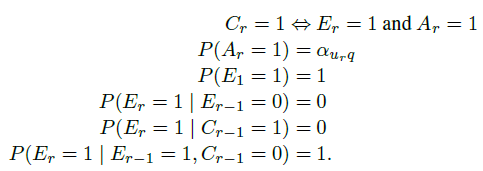
cascade model的参数估计不难,因为该model下,所有的examine事件都是被观察到的(确定的)。cascade model假设第一次点击的document以上的所有documents都被examine过。cascade model只对一个session中只有一次点击行为的事件进行建模,并且它无法解释non-linear examination patterns。cascade model的Bayesian network如下图所示:
cascade model(CM)和position-based model(PBM)的主要区别在于,PBM中一个document的点击概率与排名比它靠前的documents无关,是相互独立的,而CM则不是。另外,CM不允许一次session中有多于一次的点击情况出现,而PBM则是可以的。
5. USER BROWSING MODEL (UBM)
由Dupret and Piwowarski在2008年提出的user browsing model(UBM)是PBM的一种扩展,其包含了cascade model的思路。UBM认为,examination probability虽然以position-based为主,但也需要将之前的点击情况考虑进来:
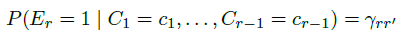
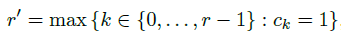
所以,上式又可以写成:
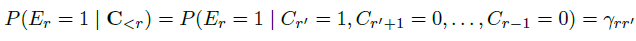
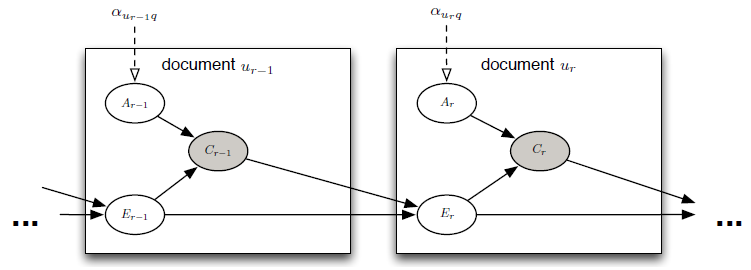
UBM的Bayesian network如下图所示。左侧的箭头表示examination probability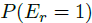 依赖于
依赖于 的点击事件
的点击事件 。而
。而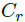 反过来又会影响其后面的document的examination probability。
反过来又会影响其后面的document的examination probability。
6. DEPENDENT CLICK MODEL (DCM)
Guo等人在2009年提出的dependent click model(DCM)是cascade model的一种扩展,可以对一次session中有多次点击的事件进行建模。这个model假设用户点击了一个document后,仍然有可能examine其它的documents。即:
其中 是continuation parameter,只依赖于document的位置。
是continuation parameter,只依赖于document的位置。
为了与后面会遇到的model保持一致,也为了简化parameter estimation,我们引入satisfaction variables 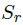 ,来表示在一次点击发生后用户的satisfaction。
,来表示在一次点击发生后用户的satisfaction。
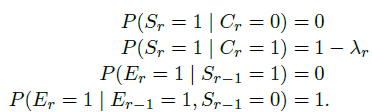
DCM的Bayesian network如下图所示:

7. CLICK CHAIN MODEL (CCM)
click chain model在DCM的基础上更进一步,作者引入了一个参数来解决用户没有任何的点击行为就放弃搜索的情况。他们同时更新了continuation parameter,使之不依赖于document的位置,而是依赖于query-document的relevance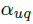 。CCM可以用公式表示为:
。CCM可以用公式表示为:
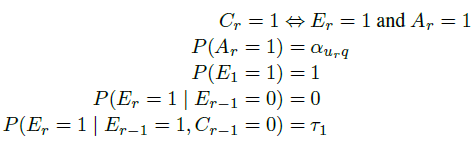
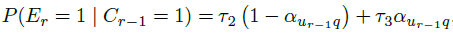
其中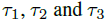 是3个常数(continuation parameters)。
是3个常数(continuation parameters)。
同样地,我们引入satisfaction variable :
:
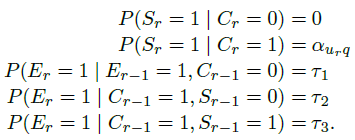
CCM假设了satisfaction的概率等同于attractiveness的概率。这是一个很强的假设,因为satisfaction是由document的内容决定的(在点击之后),而attractiveness则主要依赖于document展示在搜索结果页上的摘要。
需要注意的是,CCM是到现在为止唯一的一个区分没有点击后的continuation probability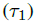 和点击document后dissatisfy的continuation probability
和点击document后dissatisfy的continuation probability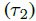 的model。CCM的Bayesian network如下图所示:
的model。CCM的Bayesian network如下图所示:
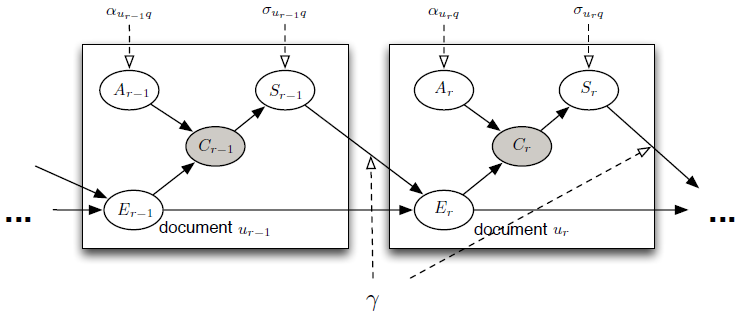
8. DYNAMIC BAYESIAN NETWORK MODEL (DBN)
由Chapelle and Zhang在2009年提出的dynamic Bayesian network model(DBN)也是cascade model的另一种不同形式的扩展。不同于CCM,DBN假设用户在点击一个document后的satisfaction不同于这个document的attractiveness(或者说perceived relevance)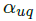 ,而是actual relevance
,而是actual relevance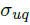 :
:
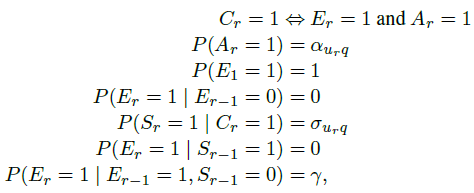
其中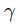 表示用户没有点击document或者点击之后没有satisfy的continuation probability。DBN的Bayesian network如下图所示:
表示用户没有点击document或者点击之后没有satisfy的continuation probability。DBN的Bayesian network如下图所示:
SIMPLIFIED DBN MODEL (SDBN)
当假设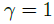 时,parameter estimation会变得容易很多。
时,parameter estimation会变得容易很多。
当我们进一步假设用户点击一个document之后,总是sarisfy的话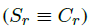 ,即
,即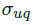 的值总是为1的情形下,SDBN便退化为cascade model。
的值总是为1的情形下,SDBN便退化为cascade model。
9. CLICK PROBABILITIES
click model是用于对用户在搜索结果页上的点击行为进行建模。我们讨论的这些basic click models 能够计算出给定一个document后的点击概率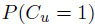 ,以及在给定相同session中前面的点击事件后对特定document进行点击的概率
,以及在给定相同session中前面的点击事件后对特定document进行点击的概率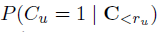 。前者可以用于预估document的CTR,后者则可以用于模拟点击行为,或者用于计算最大似然。
。前者可以用于预估document的CTR,后者则可以用于模拟点击行为,或者用于计算最大似然。
对于RCM,RCTR,DCTR,PBM这些简单的model来说,对一个document的examination probability不依赖于该document前面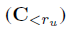 的点击。所以对于这些model来说有
的点击。所以对于这些model来说有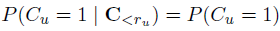 。对于RCM,RCTR,DCTR来说,这些概率直接等于model parameters:
。对于RCM,RCTR,DCTR来说,这些概率直接等于model parameters: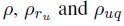 。对于PBM,则是
。对于PBM,则是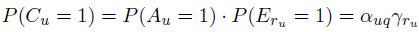 。
。
对于其余的basic click models来说,document的examination依赖于其上面的document。对于CM,DCM,CCM,DBN,SDBN来说有:
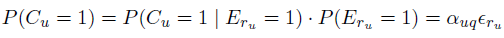
而各model的不同之处在于计算examination probability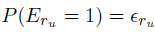 。对上述models的general rule为:
。对上述models的general rule为:
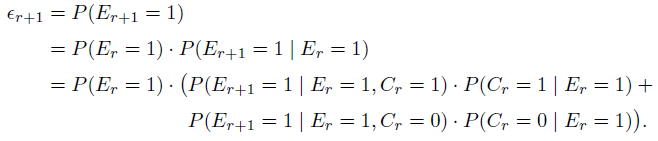
例如DBN model: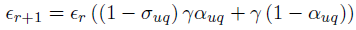 。
。
对于CM,DCM,CCM,DBN,SDBN来说,conditional probability可以用如下公式进行计算:
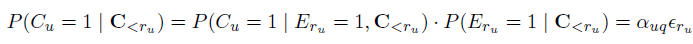
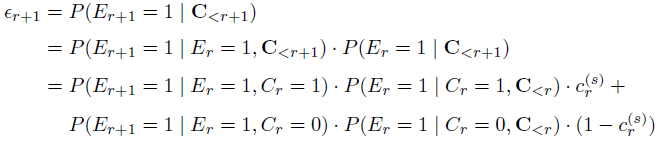
其中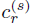 表示再一次特定的query session中的是否点击。又由于:
表示再一次特定的query session中的是否点击。又由于:
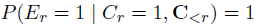
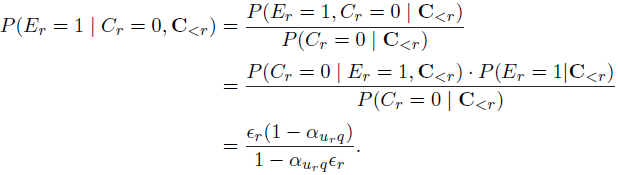
所以最终计算得到:
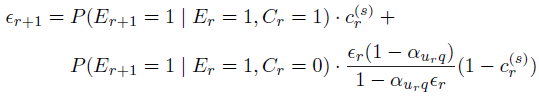
另外,对于UBM model来说,计算过程有些不一样。
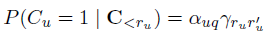
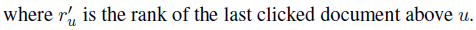
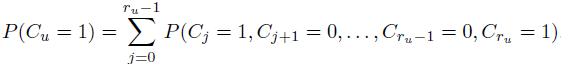
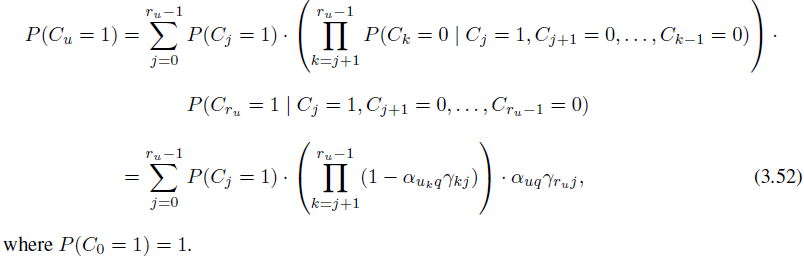
下图为上面各个model的计算情况的总结:

10. SUMMARY
上述各个model有许多相似之处。
1)attractiveness variable 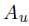
2)satisfaction variable 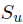
3)define how the examination probability 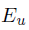 depends on the examination, satisfaction and click events for previous documents:
depends on the examination, satisfaction and click events for previous documents: 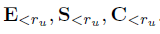
最后再来一张总结图:

版权声明:
本文由笨兔勿应所有,发布于http://www.cnblogs.com/bentuwuying。如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任。