论文地址:https://www.aclweb.org/anthology/P19-1030/
已有的研究工作:
最近有众多的模型关注对于句子的通用编码建模,从而将其用在任何监督任务中。针对单词序列,完全基于Attention的模型存在两个主要的问题:1、随着句子长度的增长,其对内存的消耗会呈2次方增长;2、不能有效的抓取和利用语义信息。递归神经网络可以通过遍历树结构来提取很好语义信息。
本文的工作和创新点:
本文提出了一个Tree Transformer模型,该模型只需通过注意力机制进行递归遍历,就可以捕获用于句子的短语语法,以及用于依赖树的单词依赖性。
研究方法:
早期的研究方法:
句子向量的表示最早来自于2013年词嵌入的突破,现有的方法包括基于RNN类网络的方法,在单词序列上使用LSTM/GRU,在每一步提取上下文特征,之后使用某种池化方法。典型的例子如ELMO模型。
在Transformer提出之后,也有BERT、GPT等这样的利用attention的句子建模方法,在大规模的数据集上进行预训练。
这样的模型在建模的过程中没有考虑语法和语义上的一些信息。
同时也有一些对于自然语言句子的树形结构的研究,如RvNN模型,自底向上地在子节点上应用符合函数,计算父节点的表示,直到根节点。
本文提出的模型:
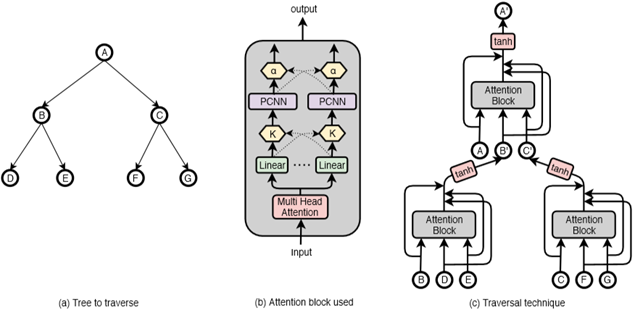
本文提出了一种新的递归神经网络结构,该结构由一个可分解的注意框架构成,称之为模型树转换器。其原理主要是:给定依赖关系树或选择树结构,任务是遍历其中的每一个子树,并推断出其根表示向量。该模型使用复合函数将一组子表示转换为一个单亲表示。该模型结构图如下图所示。
下面是具体的解释。对于依赖树(dependency tree),它在每个节点上都包含一个词,要遍历依赖树中的一个子树,需要同时查看父树和子树的表示。对于constituency tree,只有叶子节点包含单词,非终结向量仅在遍历了每个子树之后计算。使用attention块作为组成函数,
而对于本文的attention的计算方式,即multi-branch attention框架。它基于Transformer中的multi-head attention的框架。标准的dot-product attention的公式为:
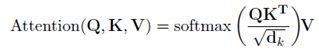
因为我们需要n个branches,所以对于每个向量复制n份。所以应用下面公式:
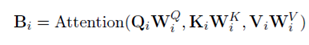
其中i在[1,n]之间,W作为参数存在,并且节点之间的参数是相同的。之后对于得到的这些向量,使用残差连接在不同的语义空间上组合,最后通过一个层归一化。公式表达如下:
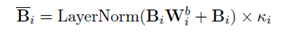
在这些transformer的表示上,使用一个position-wise的卷积网络。通过一个概率分布来进行放缩。
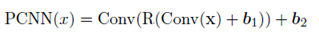
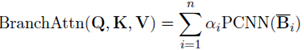
最后通过另一个残差连接组合,下面公式中的EwS表示element-wise summation。x和 分别对应attention模块的输入输出。
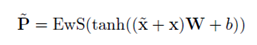
实验部分:
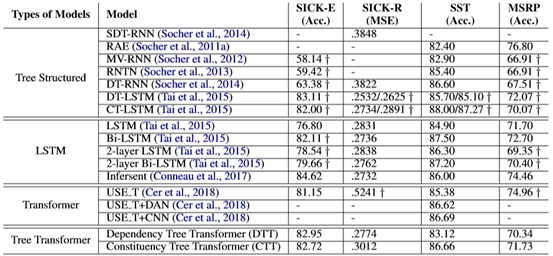
与标准模型、基于lstm的模型以及树结构的LSTMs相比,本文模型在四个任务上得到了比较好的结果。
综合评价:
本文的idea让人感觉很自然,我们有LSTM网络,有结合了语义特征的tree LSTM网络。对于transformer结构,也可以由tree transformer结构。而且tree transformer结构除了可以捕获语义信息这个作用,也可以克服transformer对于长句子建模的问题。不过从实验结果来看,提升不是很明显,如在SST数据集上,tree transformer的结果86.66相比于tree LSTM的87.27还要更差一点。