论文地址:https://arxiv.org/abs/1906.01250?context=cs.LG
已有的研究工作:
在实体链接上,已有的工作大多基于维基百科和启发式方法,它需要大量特地为任务注释的文档集合。并且这样的模型只适用于特定领域,在其他领域应用效果较差。
本文的工作和创新点:
本文主要关注的是实体链接的问题,也就是说,从句子当中提取出了一个实体,我们想知道它是知识图谱上的哪个节点。只利用自然产生的信息,包括未标记的文档和维基百科。首先为未标记文档中提到的每个实体创建一个召回列表,然后使用候选列表作为弱监督来约束文档级的实体链接模型。
研究方法:
给出一个从句子中提到的实体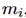 ,找到它的一个候选的知识节点
,找到它的一个候选的知识节点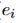 。对于文件里的其他的每个实体
。对于文件里的其他的每个实体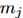 ,其中
,其中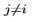 ,我们可以找出一组候选的知识节点
,我们可以找出一组候选的知识节点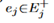 。我们可以根据任意两对
。我们可以根据任意两对 它们各自的embedding
它们各自的embedding 和
和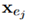 来计算它们之间的相似度
来计算它们之间的相似度

然后找一个 里最大的作为
里最大的作为 和
和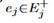 的相似度
的相似度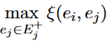 。
。
对于每一个实体 ,以及它们的上下文
,以及它们的上下文 ,我们可以用一个一层的网络来计算它的表达
,我们可以用一个一层的网络来计算它的表达
网络结构表示如下:
对于一个文件中的其它实体 ,我们也可以计算它们之间的相似度
,我们也可以计算它们之间的相似度
之后,以此作为权重,计算 与其他句子中的实体
与其他句子中的实体 到它的节点的表达:
到它的节点的表达:
以此来表示这个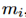 和
和 的匹配程度。这个是别的实体的信息,但需要它自身的一个匹配分数。用
的匹配程度。这个是别的实体的信息,但需要它自身的一个匹配分数。用 来表示。加上之后作为最终的
来表示。加上之后作为最终的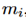 到
到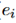 的分数。公式如下:
的分数。公式如下:

对于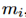 ,实际上我们有两个知识节点的集合,一个是准确的节点的集合
,实际上我们有两个知识节点的集合,一个是准确的节点的集合 ,另一个是不准确的节点的集合
,另一个是不准确的节点的集合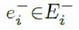 。
。
我们的目标,是希望准确的节点集合中任意一个节点的分数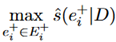 要比不准确的节点的分数
要比不准确的节点的分数 高一个margin
高一个margin
所以对于不满足这个条件的情况进行惩罚:
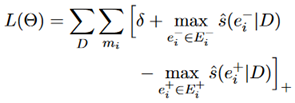
实验结果如下:

可以看到在一些数据集上远远优于其它同类的半监督模型,在一些任务上,甚至优于结合了人工注释数据的全监督模型。
评价:
一篇做实体链接很优秀的模型,在做实体链接的时候,不光关注当前实体,也考虑了其它实体链接的情况,使用加权的平均来作为注意力机制。在过程中使用的弱监督或半监督的方法很具有创新性。从实验结果上来看,在某些数据集上超过了一些为特定问题训练的全监督模型。在future work中作者提到,如果结合一些全监督模型中使用的人工注释数据,可能进一步提高模型效果。