上一次分享了使用matplotlib对爬取的豆瓣书籍排行榜进行分析,但是发现python本身自带的这个绘图分析库还是有一些局限,绘图不够美观等,在网上搜索了一波,发现现在有很多的支持python的绘图库可以使用,本次尝试使用pyecharts对爬取的数据进行分析,然后发现这个库实在是太好用了,生成的库也很好看,还能生成动态图,简直是进行数据分析的一大神器!
pyecharts: pyecharts是一个封装百度开源图表库echarts的包,使用pyecharts可以生成独立的网页,也可以在flask、django中集成使用。
本次爬取的首页地址是:
http://www.tianqihoubao.com/lishi/nanjing.html
爬取步骤:
- 爬取主网页,获取进入每个南京市具体年份月份的天气数据的链接
- 爬取上方获取的具体链接的数据
- 存储数据
- 对数据进行筛选后使用pyecharts进行分析
话不多说,马上开始吧!
- 步骤一
从上图可知,我们需要先获取进入每个具体月份的链接,才能爬取想要的数据,所以首先定义获取具体链接的函数,然后在爬取会方便很多;查看网页源代码查找目标所在位置,本次我依然是使用lxml库来进行数据的爬取(PS:感觉习惯了lxml其他库就不好用了),这里需要注意的是,我是将获得的结果一个一个的存入列表,这种方法很笨,但作为菜鸟的我确实不知道其他方法了,还有就是发现爬取的部分链接缺了一点,所以又定义了一个函数来补上。
具体代码如下: 注:转载代码请标明出处
1 def get_mainurl(url): #定义获取月份天气的详细url 函数 2 res = requests.get(url, headers=headers) 3 main_url = [] 4 if res.status_code == 200: #判断请求状态 5 selector = etree.HTML(res.text) 6 htmlurls = selector.xpath('//div[contains(@id,"content")]/div') #循环点 7 try: 8 for htmlurl in htmlurls: 9 Jan = htmlurl.xpath('ul[1]/li[2]/a/@href')[0] #一月份天气url 10 main_url.append(Jan) #将网址放入列表中,一个一个放是很蠢的方法,但我也确实不知道其他方法了,下同 11 Feb = htmlurl.xpath('ul[1]/li[3]/a/@href')[0] #二月份天气url 12 main_url.append(Feb) 13 Mar = htmlurl.xpath('ul[1]/li[4]/a/@href')[0] #同上,下类推 14 main_url.append(Mar) 15 Apr = htmlurl.xpath('ul[2]/li[2]/a/@href')[0] 16 main_url.append(Apr) 17 May = htmlurl.xpath('ul[2]/li[3]/a/@href')[0] 18 main_url.append(May) 19 June = htmlurl.xpath('ul[2]/li[4]/a/@href')[0] 20 main_url.append(June) 21 July = htmlurl.xpath('ul[3]/li[2]/a/@href')[0] 22 main_url.append(July) 23 Aug = htmlurl.xpath('ul[3]/li[3]/a/@href')[0] 24 main_url.append(Aug) 25 Sep = htmlurl.xpath('ul[3]/li[4]/a/@href')[0] 26 main_url.append(Sep) 27 Oct = htmlurl.xpath('ul[4]/li[2]/a/@href')[0] 28 main_url.append(Oct) 29 Nov = htmlurl.xpath('ul[4]/li[3]/a/@href')[0] 30 main_url.append(Nov) 31 Dec = htmlurl.xpath('ul[4]/li[4]/a/@href')[0] 32 main_url.append(Dec) 33 34 time.sleep(0.5) #休眠0.5s 35 except IndexError: 36 pass 37 return main_url #将存了所有url的列表返回 38 else: 39 pass 40 41 42 def link_url(url): #上面获取的url是不完整的,此函数使其完整 43 final_urls= [] 44 list_urls = get_mainurl(url) 45 for list_url in list_urls: 46 if len(list_url) < 30: #因为获取的url有一些少了‘/lishi/’,所以需要判断一下 47 list_url = 'http://www.tianqihoubao.com/lishi/' + list_url 48 final_urls.append(list_url) 49 else: 50 list_url = 'http://www.tianqihoubao.com' + list_url 51 final_urls.append(list_url) 52 return final_urls
- 步骤二
接下来是获取所需的数据,遍历所在节点就行了,需要注意的是要跳过第一个节点,因为其内部没有内容。
代码如下:
def get_infos(detail_url): #爬取月份天气详细数据函数 main_res = requests.get(detail_url, headers=headers) main_sele = etree.HTML(main_res.text) main_infos = main_sele.xpath('//div[@class="hd"]/div[1]/table/tr') i = True try: for info in main_infos: if i: #此处i的作用是跳过第一次循环,因为第一个是非天气数据 i = False continue else: date = info.xpath('td[1]/a/text()')[0].replace(" ", '').replace(' ', '') #去掉换行符、空格等,下同 weather = info.xpath('td[2]/text()')[0].replace(" ", '').replace(' ', '') temps = info.xpath('td[3]/text()')[0].replace(' ', '').replace(' ', '') clouds = info.xpath('td[4]/text()')[0].replace(" ", '').replace(' ', '') with open('Nanjing.csv', 'a+', newline='', encoding='utf-8')as fp: #存入csv文件 writer = csv.writer(fp) writer.writerow((date, weather, temps, clouds)) except IndexError: pass
- 步骤三
接下来执行主程序存储就行了,使用了多进程来爬取加快速度,所以爬取的数据排列可能不按顺序,使用wps或excel自行排序即可。
下方附上剩余代码:
import requests from lxml import etree import time import csv from multiprocessing import Pool #请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36' } if __name__ == '__main__': #执行主程序 url = 'http://www.tianqihoubao.com/lishi/nanjing.html' #获取月份天气url的网址 get_mainurl(url) details = link_url(url) with open('Nanjing.csv', 'a+', newline='', encoding='utf-8')as ff: #写入第一行作为表头 writer = csv.writer(ff) writer.writerow(('日期', '天气状况', '气温', '风力风向')) pool = Pool(processes=4) #使用多进程爬取 pool.map(get_infos, details) #需要注意爬取结果并不是按顺序的,可以用excel进行排序
部分数据如下:

- 步骤四
进行数据分析之前,先用pandas的read_csv()方法将数据读出,然后将2011-2018年的温度和天气状况提取出来进行分析,这里温度需要将数字提取出来,天气状况需要将 ‘/’去掉,还有因为一天的天气数据是多个的(例如一天气温有最高温和最低温),所以后面分析时发现数据量大于8年总天数,这是正常的。
由于我也是第一次使用pyecharts,所以话不多说,直接上代码:
1 import pandas as pd 2 from pyecharts import Line, Pie, Page, Bar 3 4 5 page = Page(page_title='南京气温分析') #page 使多个图位于一个网页,网页名 6 7 pd.set_option('display.max_rows', None) #设置使dataframe 所有行都显示 8 df = pd.read_csv('Nanjing.csv') #读取天气数据 9 10 #获取最高气温 11 Max_temps = [] 12 for max_data in df['气温']: 13 Max_temps.append(int(max_data[0:2].replace('℃',''))) 14 Max_temps = Max_temps[:-109] 15 16 #获取最低气温 17 Low_temps = [] 18 for low_data in df['气温']: 19 Low_temps.append(int(low_data[-3:-1].replace('/', ''))) 20 Low_temps = Low_temps[:-109] 21 22 #获取2011年一月气温数据 23 attr = ['{}号'.format(str(i))for i in range(1,32)] 24 Jan_Htemps = Max_temps[:31] 25 Jan_Ltemps = Low_temps[:31] 26 #绘制气温折线图 27 line = Line('南京市2011年一月气温变化') #赋予将折线图对象, 命名 28 line.add('当日最高气温', attr, Jan_Htemps, mark_point=['average', 'max', 'min'], #显示平均、最大/小值 29 mark_point_symbol='diamond', #特殊点用钻石形状显示 30 mark_point_textcolor='red', #标注点颜色 31 is_smooth=True #图像光滑 32 ) 33 line.add('当日最低气温', attr, Jan_Ltemps, mark_point=['average', 'max', 'min'], 34 mark_point_symbol='arrow', 35 mark_point_textcolor='blue' 36 ) 37 line.use_theme('dark') #背景颜色 38 line.show_config() #调试输出pyecharts的js配置信息 39 page.add_chart(line) #添加到page 40 41 #统计2011-2018年的每天最高温的气温分布情况,分四个阶梯 42 Hzero_down = Hthrity_up = Hzup_fifdown = Hfifup_thrdown = 0 43 for i in Max_temps: 44 if i <= 0: 45 Hzero_down += 1 46 elif i<=15: 47 Hzup_fifdown += 1 48 elif i<=30: 49 Hfifup_thrdown += 1 50 else: 51 Hthrity_up +=1 52 53 #统计2011-2018年的每天最高温的气温分布情况分,分四个阶层 54 Lfiv_down = L25_up = Lfiv_tendown = Ltenup_25down = 0 55 for i in Low_temps: 56 if i <= -5: 57 Lfiv_down += 1 58 elif i<=10: 59 Lfiv_tendown += 1 60 elif i<=25: 61 Ltenup_25down += 1 62 else: 63 L25_up +=1 64 65 #绘图 66 attr2 = ['0℃及以下', '0-15℃', '15-30℃', '30℃及以上'] #标签属性 67 H_data = [Hzero_down, Hzup_fifdown, Hfifup_thrdown, Hthrity_up] #数据 68 pie = Pie('南京市2011年-2018年每日最高气温分布', title_pos='center', title_color='red') #绘制饼图,标题位于中间,标题颜色 69 pie.add('',attr2, H_data, is_label_show=True, #展示标签 70 legend_pos='right', legend_orient='vertical', #标签位置,标签排列 71 label_text_color=True, legend_text_color=True, #标签颜色 72 ) 73 pie.show_config() 74 page.add_chart(pie, name='饼图') 75 76 #绘制环形图 77 attr3 = ['-5℃及以下', '-5-10℃', '10-25℃', '25℃及以上'] 78 L_data = [Lfiv_down, Lfiv_tendown, Ltenup_25down, L25_up] 79 pie2 = Pie('南京市2011年-2018年每日最低气温分布', title_pos='center') 80 pie2.add('',attr3, L_data, radius=[30, 70], is_label_show=True, #radius环形图内外圆半径 81 label_text_color=None, legend_orient='vertical', 82 legend_pos='left', legend_text_color=None 83 ) 84 pie2.show_config() 85 page.add_chart(pie2, name='环形图') 86 87 88 #绘制南京2011-2018年天气状况条形统计图 89 Weather_NJ = [] 90 for Weathers in df['天气状况']: 91 Weather_s = Weathers.split('/') 92 Weather_NJ.append(Weather_s[0]) 93 Weather_NJ.append(Weather_s[1]) 94 Weather_NJ = Weather_NJ[:-218] 95 96 sunny = rainy = yin_cloudy = lightening = duo_cloudy = snowy = 0 97 for t in Weather_NJ: 98 if t == '晴': 99 sunny += 1 100 elif t == '阴': 101 yin_cloudy += 1 102 elif t == '多云': 103 duo_cloudy += 1 104 elif t == '雷阵雨': 105 lightening += 1 106 elif '雨' in t and t != '雨夹雪': 107 rainy += 1 108 elif '雪' in t: 109 snowy += 1 110 else: 111 pass 112 Weather_attr = ['晴', '雨天', '多云', '阴天', '雷阵雨', '雪天'] 113 Weather_datas = [sunny, rainy, duo_cloudy, yin_cloudy, lightening, snowy] 114 bar = Bar('南京市2011-2018年天气情况统计', '注意:一天有两个天气变化,部分日期天气情况可能丢失', title_pos='center') 115 bar.add('天气状况', Weather_attr, Weather_datas, is_more_utils=True, 116 mark_point=['max', 'min'], legend_pos='right' 117 ) 118 bar.show_config() 119 page.add_chart(bar) 120 121 page.render('all_analysis.html') #网页地址
图像结果如下:

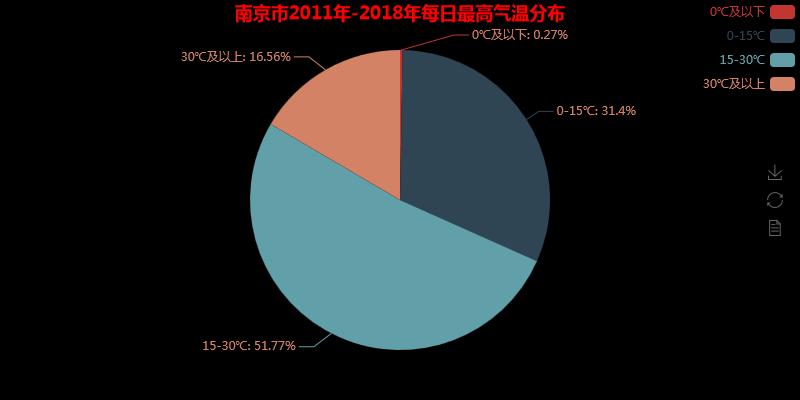
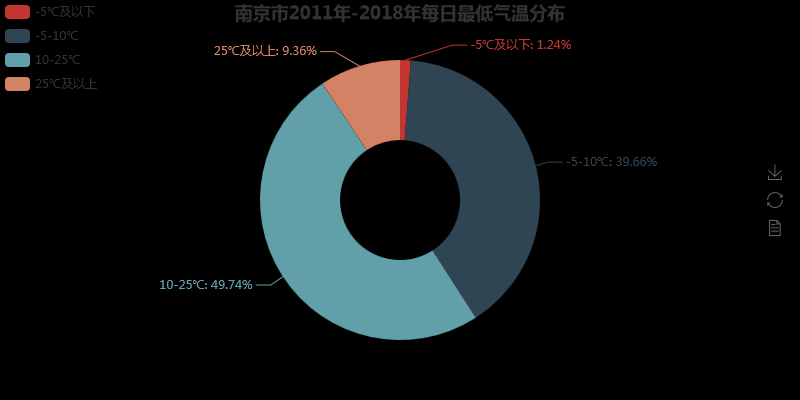

是不是发现使用pyecharts得到的图表更加好看,这里上传的图片是静态的,在网页打开的时查看其实是动态的。
这里只爬取了南京市的历史天气,感兴趣的朋友可以尝试爬取更多城市的,甚至可以在此基础上编写一个小软件,随时随地查看不同地区的历史天气,不过前提是该网站的源代码不发生大变动。
本次分享就到此为止,如果有错误或者疑问或者是建议欢迎大家随时指正,我也会积极回应。