一.MINIST数据集下载
1.https://pjreddie.com/projects/mnist-in-csv/ 此网站提供了mnist_train.csv和mnist_test.csv,其中mnist_train.csv有60000个训练数据,mnist_test.csv有10000个测试数据
2.还有两个较小数据集,可供测试。
https://raw.githubusercontent.com/makeyourownneuralnetwork/makeyourownneuralnetwork/master/mnist_dataset/mnist_train_100.csv
https://raw.githubusercontent.com/makeyourownneuralnetwork/makeyourownneuralnetwork/master/mnist_dataset/mnist_test_10.csv
二.如上下载MNIST数据集,那么MNIST数据集到底是什么呢?是0~9的数字图像的集合,在MNIST数据集中数字图像用784个像素值表示,同一个数字图像有不同的像素值。下面我们可以看下MNIST数据集长什么样子。
1.我们可以用python的open函数加载mnist_train_100.csv数据集,取第一个集合,代码如下,非常简单:

2.如下为输出的集合内容,他们是由785个数字组成,第一个数字为标签,即书写者实际希望表示的数字。后面的784个数字为书写体数字的像素值,范围在0~255之间,像素数组的尺寸为28*28.

3.从这个长达784个值的列表中,人们很难看出这些数字组成了某人书写数字5的图像。我们可以利用上面的数据画出图像,看下到底是不是5?
还是利用python代码实现:

如上,我们把上面的字符串按照","分割,转换成28*28的数组,绘制成图像,那么会是5吗,下面可以看下执行的记结果:
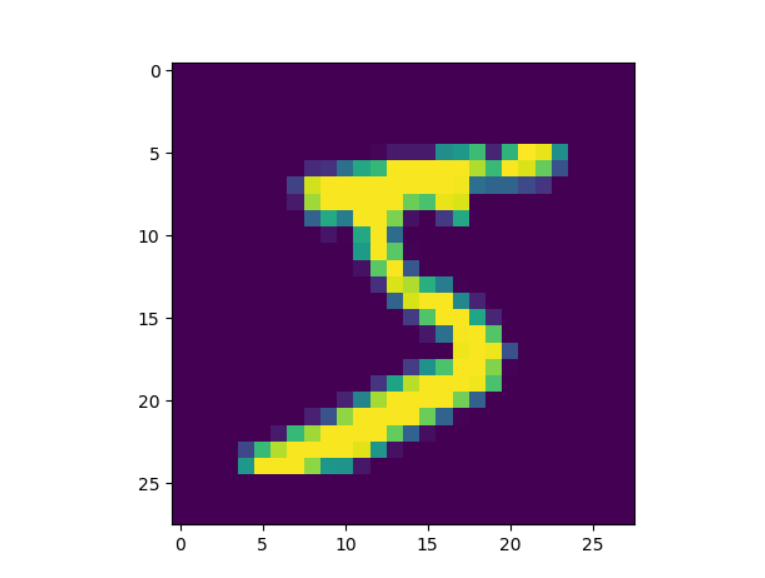
确实很像5,下面MNIST基础已经讲解完全,下面我们进行用标准3层神经网络实现MNIST识别。
三.用标准3层神经网络实现MNIST识别
在做一件事之前我们要先明白我们的目的是什么?一个图片,我们用眼睛可以很直观的看出是什么,比如是花、人等。但是计算机没有眼睛,我们想让它识别图片怎么办呢,这就是我们的目的。我们的目的是让神经网络能识别数字图像。搭建3层神经网络,用MNIST训练数据集训练神经网络,训练完后我们用测试训练集来测试当我们输入一个数字图像的784个像素值时,神经网络到底能不能根据这些像素值来识别出数字图像是几。
1.准备MNIST训练数据。
1.>搭建3层标准神经网络,可以参考我以前的博客。https://www.cnblogs.com/bestExpert/p/9248353.html
2.>搭建完后需要确认3层的节点数目,上面我们说了数字图像是由784个像素值组成,所以输入层需要784个节点。隐藏层节点需要多少个并没有一个明确的规定,我们可以先尝试选择100个节点。输出层我们的目的是确认数字图像是几,所以输出层需要10个节点,对应数字图像0~9。综上我们得出,输入层784个节点,隐藏层100个节点,输出层10个节点。
3.>确定输入值,输入值最佳的范围为0.01~0.99,但是数字图片的像素值在0~255之间,所以我们需要缩小像素值,使其能达到0.01~0.99的范围。如下,用python实现输入值:

4.>最后一步是确定目标值,上面我们已经说了输出层为10个节点,代表0~9,输出层数据的范围为0.01~0.99,我们可以假设一下,当输入层的像素值代表5的数字时,输出层第6个节点的输出信号应该最大,其他输出信号应该很小,处于抑制状态,这就是我们希望达到的状态,由此我们可以确定目标值应该是第6个节点输出值最大为0.99,其他输出值数据很小,为0.01,这就是我们希望达到的目标值。用python实现如下:

5.>根据mnist_train_100.csv训练数据集来训练神经网络。优化权重。
targets为目标值数组,其中output_nodes为输出层节点数,为10,第一行代码创建一个长度为10的数组,初始值为0.01,第二行代码根据像素值的标签来设置数组中那个值为0.99。、
以上步骤为第一阶段,搭建神经网络,确认3层节点,确定输入值、输出值,训练神经网络。
2.测试网络。
如上已经写到了用MNIST训练集训练神经网络,下面我们需要用测试集测试下训练后的神经网络到底能不能识别数字图像?识别的准确度是多少。
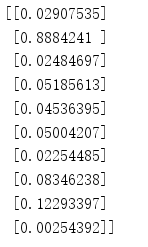
1.>用1个测试集测试。步骤也非常简单,读取测试集的文件,取第一条数据,用query函数测试,输出结果。在执行之前,我们再回忆下输出值,当输入的数据标签为5时,最佳输出值为多少。上面我们说了,输出层为10个节点,对应标签的0~9,所以当输入的标签为5是,输出层的第6个节点的输出值应该最大,其余输出节点输出值小,这是理想输出状态,此时就可以说明神经网络可以识别MINIST数据集,下面就是验证结果的时候了

如下为输出结果,可以看出输出的矩阵中第2个值最大,说明我们上面的假设是成功的,下面我们在用全部数据测试下,看看成功率为多少。
2.>创建记分卡,遍历整个测试集,当输出结果为我们预期的结果时在记分卡上加1,否则为0,最后统计1的比例,得出神经网络识别的准确率。代码如下:
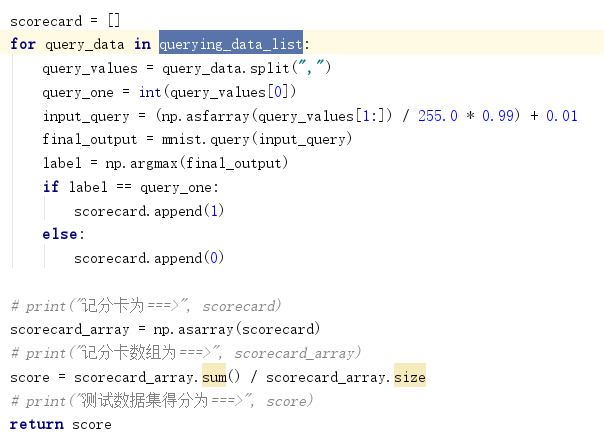
执行结果为:
0.6
执行后可以看出,准确率非常小,只有0.6,即60%,在考虑到使用的训练集很小,只有10个数据时,这个结果实际并不太糟糕,下面我们可以使用60000的训练集和10000的测试集来再次查看准确率。
3.>上面我们测试的准确率太小,下面我们换大的MNIST训练集,开篇时提供了下载地址。下面我们直接使用,只需要在代码里面把文件的路径一换就可以,执行结果如下:
0.75
我们可以看出准确率已经在75%以上,这都可以与行业标准媲美。那么准确率还能再提高吗?答案是可以的,下面我们可以用一些办法改进准确率。
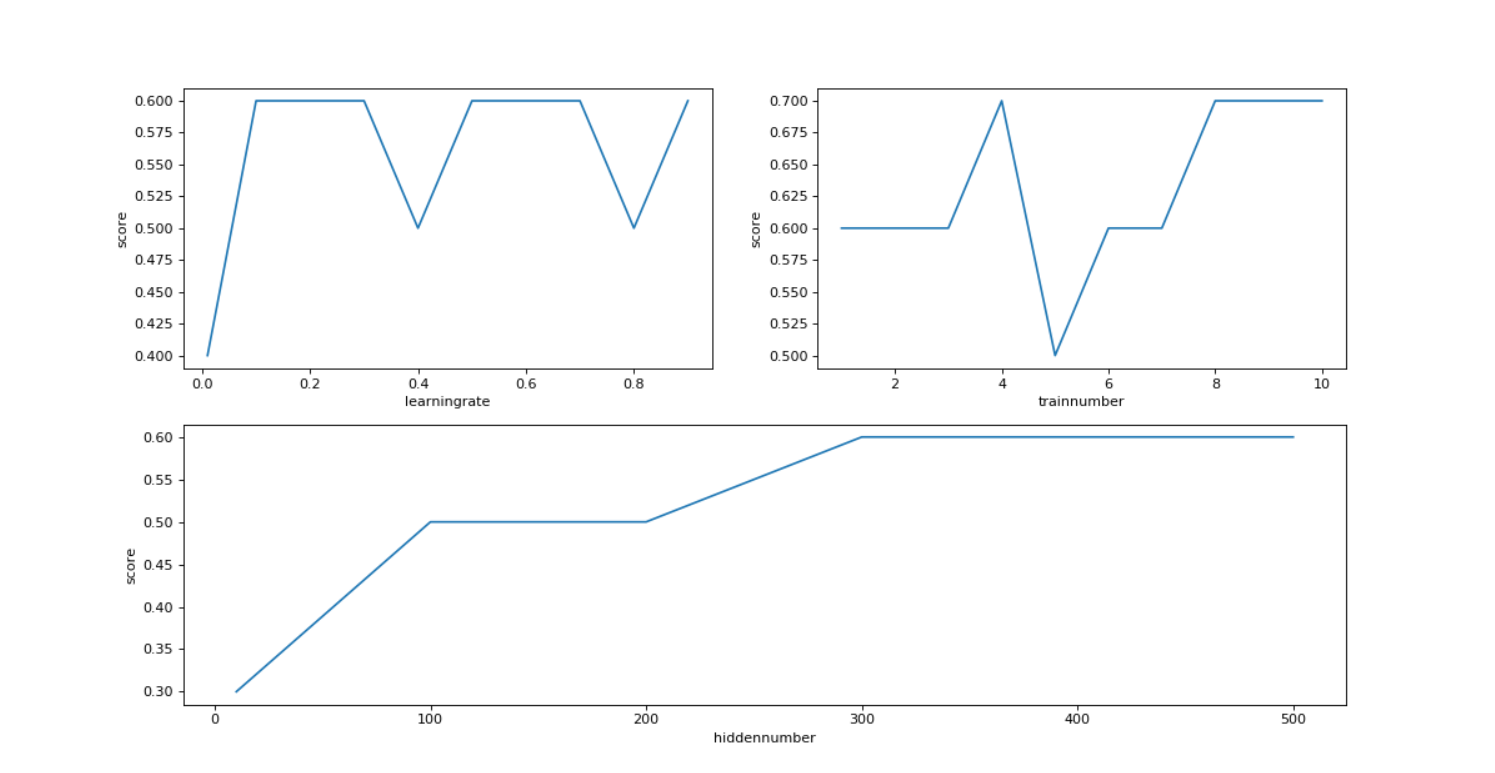
3.一些改进(调整后的图形均为小的mnist数据集的结果)
1.>调整学习率
上面我们设置的初始学习率为0.3,我们可以试着调整学习率,来提高准确度。学习率我们可以从0.1调整到0.9。我们可以用图形直观的看出随着学习率的调整mnist识别的准确率的变化趋势。

2.>调整训练次数。
我们把训练一次记为一个世纪。我们可以试着增加训练次数。下面显示的是1-10次训练次数和准确率的变化趋势。

3.>增加隐藏层的节点数量。
输入节点只需引入输入信号,输出节点只要送出神经网络的答案,是隐藏层进行学习,将输入转变为答案。这是学习发生的场所。事实上,隐藏层节点前后的连接权重具有学习能力。所以我们可以试着改变隐藏层的节点数量来优化神经网络。
4.整体改变
1.>我们可以用上面三种方式改变简单的mnist数据集的神经网络,找到最适合的学习率、运行世纪次数和隐藏层数量。
2.>我们可以用上面三种方式改变全量的mnist数据集的神经网络,找到最适合的学习率、运行世纪次数和隐藏层数量。
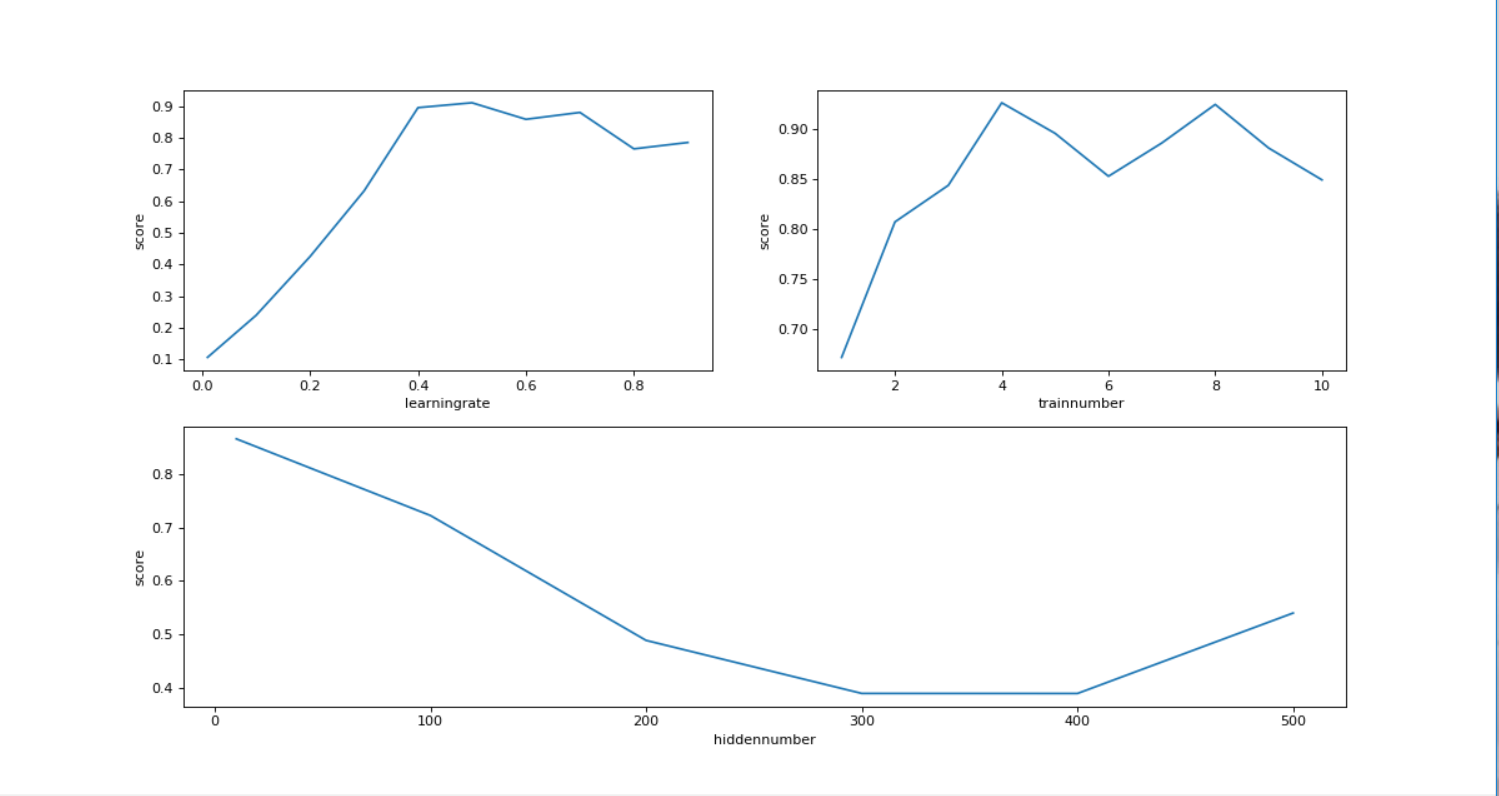
如上可以看见随着学习率、训练次数和隐藏层的变化的准确率。因为是全量运行,所以时间比较长,我运行了大概有50分钟。
上面练习的代码可以参考https://github.com/pythonAndAI/nerve-net